Denna animation visar en serie kollisionshändelser på STAR, var och en med tusentals partikelspår och signalerna registrerade när några av dessa partiklar träffar olika detektorkomponenter. Det bör ge dig en uppfattning om hur komplex utmaningen är att rekonstruera en fullständig förteckning över varje partikel och de förhållanden under vilka den skapades så att forskare kan jämföra hundratals miljoner händelser för att leta efter trender och göra upptäckter. Upphovsman:Brookhaven National Laboratory
För första gången, forskare har använt högpresterande datorer (HPC) för att rekonstruera data som samlats in genom ett kärnfysikaliskt experiment-ett framsteg som dramatiskt kan minska den tid det tar att göra detaljerad information tillgänglig för vetenskapliga upptäckter.
Demonstrationsprojektet använde Cori -superdatorn vid National Energy Research Scientific Computing Center (NERSC), ett högpresterande datacenter vid Lawrence Berkeley National Laboratory i Kalifornien, att rekonstruera flera datamängder som samlats in av STAR -detektorn under partikelkollisioner vid Relativistic Heavy Ion Collider (RHIC), en forskningsanläggning för kärnfysik vid Brookhaven National Laboratory i New York. Genom att köra flera datorjobb samtidigt på de tilldelade superdatorkärnorna, laget omvandlade 4,73 petabyte rå data till 2,45 petabyte med "fysikfärdiga" data på en bråkdel av den tid det skulle ha tagit med egna datoreresurser med hög kapacitet, även med en tvåvägs transkontinental dataresa.
"Anledningen till att det här är riktigt fantastiskt, "sa Brookhaven -fysikern Jérôme Lauret, som hanterar STAR:s datorbehov, "är att dessa högpresterande datorresurser är elastiska. Du kan ringa för att reservera en stor tilldelning av datorkraft när du behöver det-till exempel strax före en stor konferens när fysiker har bråttom att presentera nya resultat. "Enligt Lauret, att förbereda rådata för analys tar vanligtvis många månader, vilket gör det nästan omöjligt att ge en sådan kortsiktig respons. "Men med HPC, kanske du kan kondensera så många månaders produktionstid till en vecka. Det skulle verkligen stärka forskarna! "
Prestationen visar de synergistiska funktionerna hos RHIC och NERSC - U.S. Department of Energy (DOE) Office of Science Användarfaciliteter som ligger vid DOE-drivna nationella laboratorier på motsatta kuster-anslutna till ett av de mest omfattande högpresterande datadelningsnätverken i världen, DOE:s Energy Sciences Network (ESnet), en annan DOE Office of Science User Facility.
"Detta är en nyckelmodell för högpresterande datorer för experimentella data, visar att forskare kan få sina rådatabehandlings- eller simuleringskampanjer gjorda på några dagar eller veckor vid en kritisk tid istället för att sprida sig över månader på sina egna dedikerade resurser, "sa Jeff Porter, medlem i data- och analystjänstteamet på NERSC.
Miljarder datapunkter
För att göra fysiska upptäckter vid RHIC, forskare måste sortera igenom hundratals miljoner kollisioner mellan joner accelererade till mycket hög energi. STJÄRNA, en sofistikerad, elektroniskt instrument i egen storlek, registrerar det subatomära skräpet som strömmar från dessa partikelsmutsningar. I de mest energiska händelserna, många tusentals partiklar träffar detektorkomponenter, producerar fyrverkeriliknande uppvisningar av färgglada partikelspår. Men för att ta reda på vad dessa komplexa signaler betyder, och vad de kan berätta om den spännande formen av materia som skapades vid RHIC:s kollisioner, forskare behöver detaljerade beskrivningar av alla partiklar och förhållandena under vilka de producerades. De måste också jämföra enorma statistiska prover från många olika typer av kollisionshändelser.
För att katalogisera den informationen krävs sofistikerade algoritmer och programvara för mönsterigenkänning för att kombinera signaler från de olika avläsningselektronikerna, och ett sömlöst sätt att matcha data med register över kollisionsförhållanden. All information måste sedan förpackas på ett sätt som fysiker kan använda för sina analyser.

Cori, den nyaste superdatorn vid National Energy Research Scientific Computing Center (NERSC), är en Cray XC40 med en topprestanda på cirka 30 petaflops. Upphovsman:Brookhaven National Laboratory
Sedan RHIC började köra år 2000, denna rådata behandling, eller rekonstruktion, har utförts på dedikerade datorresurser vid RHIC och ATLAS Computing Facility (RACF) vid Brookhaven. High-throughput computing (HTC) -kluster knyter ihop data, händelse för händelse, och skriva ut de kodade detaljerna för varje kollision till ett centraliserat masslagringsutrymme som är tillgängligt för STAR -fysiker runt om i världen.
Men utmaningen att hänga med i data har vuxit med RHICs ständigt förbättrade kollisionshastigheter och eftersom nya detektorkomponenter har lagts till. Under de senaste åren har STARs årliga råuppsättningar har nått miljarder händelser med datastorlekar i multi-petabyte-serien. Så STAR-datorteamet undersökte användningen av externa resurser för att möta kravet på snabb tillgång till fysik-redo data.
Många kärnor gör att ljus fungerar
Till skillnad från datorer med hög kapacitet på RACF, som analyserar händelser en efter en, HPC -resurser som de på NERSC delar upp stora problem i mindre uppgifter som kan köras parallellt. Så den första utmaningen var att "parallellisera" behandlingen av STAR -händelsedata.
"Vi skrev arbetsflödesprogram som uppnådde den första nivån av parallellisering - händelseparallellisering, "Sa Lauret. Det betyder att de skickar in färre jobb som består av många händelser som kan bearbetas samtidigt på de många HPC -datorkärnorna.
"Tänk dig att bygga en stad med 100 bostäder. Om detta gjordes med hög genomströmning, varje hus skulle ha en byggare som utför alla uppgifter i följd - att bygga grunden, väggarna, och så vidare, "Sa Lauret." Men med HPC ändrar vi paradigmet. Istället för en arbetare per hus har vi 100 arbetare per hus, och varje arbetare har en uppgift - att bygga väggarna eller taket. De fungerar parallellt, på samma gång, och vi monterar ihop allt i slutet. Med detta tillvägagångssätt, vi kommer att bygga det huset 100 gånger snabbare. "
Självklart, det tar lite kreativitet att tänka på hur sådana problem kan delas upp i uppgifter som kan köras samtidigt istället för sekventiellt, La Lauret till.
HPC sparar också tid när råttdetektorsignaler matchas med data om miljöförhållandena under varje händelse. Att göra detta, datorerna måste komma åt en "tillståndsdatabas" - en registrering av spänningen, temperatur, tryck, och andra detektorförhållanden som måste beaktas för att förstå beteendet hos partiklarna som produceras vid varje kollision. I händelse-för-händelse, rekonstruktion med hög kapacitet, datorerna hämtar databasen för att hämta data för varje enskild händelse. Men eftersom HPC -kärnor delar lite minne, händelser som inträffar nära i tiden kan använda samma cachade tillståndsdata. Färre samtal till databasen innebär snabbare databehandling.
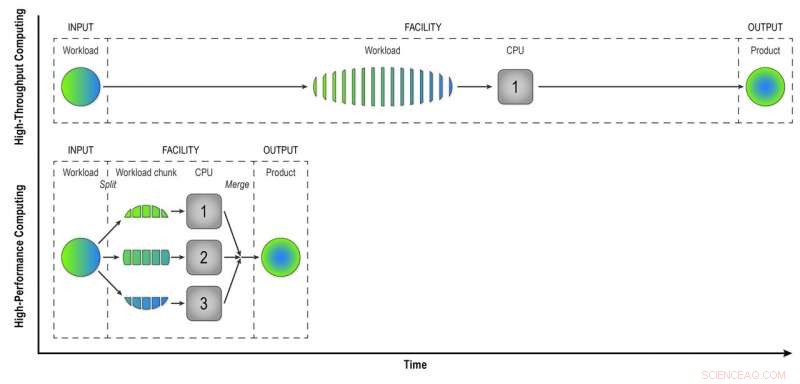
Vid beräkning med hög kapacitet, en arbetsbelastning som består av data från många STAR-kollisioner bearbetas händelse-för-händelse på ett sekventiellt sätt för att ge fysiker "rekonstruerade data"-produkten de behöver för att analysera data fullt ut. Högpresterande datorer bryter arbetsbelastningen i mindre bitar som kan köras genom separata processorer för att påskynda datarekonstruktionen. I denna enkla illustration, att bryta en arbetsbelastning på 15 händelser i tre bitar av fem händelser som bearbetas parallellt ger samma produkt på en tredjedel av tiden som metoden med hög genomströmning. Om du använder 32 processorer på en superdator som Cori kan du kraftigt minska den tid det tar att transformera rådata från en riktig STAR -dataset, med många miljoner evenemang, till användbar information som fysiker kan analysera för att göra upptäckter. Upphovsman:Brookhaven National Laboratory
Teamwork i nätverk
En annan utmaning för att migrera uppgiften att återuppbygga rådata till en HPC -miljö var bara att få data från New York till superdatorer i Kalifornien och tillbaka. Både in- och utdataset är enorma. Teamet började smått med ett princip-princip-experiment-bara några hundra jobb-för att se hur deras nya arbetsflödesprogram skulle prestera.
"Vi fick mycket hjälp från nätverksproffsen på Brookhaven, "sa Lauret, "särskilt Mark Lukascsyk, en av våra nätverksingenjörer, som var så upphetsad över vetenskapen och hjälpte oss att göra upptäckter. "Kollegor i RACF och ESnet hjälpte också till att identifiera hårdvaruproblem och utvecklade lösningar när teamet arbetade nära Jeff Porter, Mustafa Mustafa, och andra på NERSC för att optimera dataöverföringen och arbetsflödet från ände till slut.
Börja smått, skala upp
Efter att ha finjusterat deras metoder baserat på de första testerna, laget började skala upp till att använda 6, 400 datorkärnor på NERSC, sedan upp och upp och upp.
"6, 400 kärnor är redan hälften av storleken på de resurser som finns tillgängliga för datarekonstruktion vid RACF, "Sa Lauret." Så småningom gick vi till 25, 600 kärnor i vårt senaste test. "Med allt klart i förväg för en tidstilldelning på Cori-superdatorn, "vi gjorde detta test i några dagar och fick en hel dataproduktion klar på nolltid, "Sa Lauret. Enligt Porter på NERSC, "Den här modellen är potentiellt ganska transformativ, och NERSC har arbetat för att stödja sådant resursutnyttjande genom, till exempel, länka sitt centrumomfattande högpresterande disksystem direkt till dess dataöverföringsinfrastruktur och möjliggöra stor flexibilitet i hur jobbplatser kan schemaläggas. "
Den totala effektiviteten för hela processen-tiden programmet kördes (inte satt i viloläge, väntar på datorresurser) multiplicerat med effektiviteten att använda de tilldelade superdatorplatserna och få användbar utmatning hela vägen tillbaka till Brookhaven - var 98 procent.
"Vi har bevisat att vi effektivt kan använda HPC -resurser för att eliminera eftersläpning av obearbetade data och lösa tillfälliga resurskrav för att påskynda vetenskapliga upptäckter, Sa Lauret.
Han utforskar nu sätt att generalisera arbetsflödet till Open Science Grid-ett globalt konsortium som sammanställer datoreressurser-så att hela samhället med hög energi och kärnfysiker kan använda det.