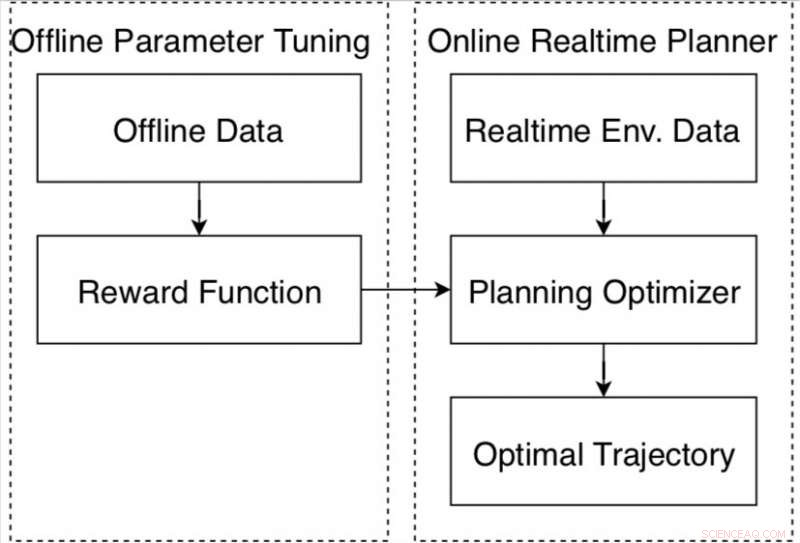
Datadriven rörelseplanerare för autonom körning på Apollo-plattformen. Kredit:Fan et al.
Forskare vid det kinesiska multinationella teknikföretaget Baidu har nyligen utvecklat ett datadrivet ramverk för autotuning för självkörande fordon baserat på Apollos autonoma körplattform. Ramverket, presenteras i en tidning förpublicerad på arXiv, består av en ny förstärkningsinlärningsalgoritm och en offlineträningsstrategi, samt en automatisk metod för insamling och märkning av data.
En rörelseplanerare för autonom körning är ett system utformat för att generera en säker och bekväm bana för att nå en önskad destination. Att designa och trimma dessa system för att säkerställa att de presterar bra under olika körförhållanden är en svår uppgift som flera företag och forskare världen över för närvarande försöker ta sig an.
"Rörelseplanering för självkörande bilar har många utmanande problem, "Fan Haoyang, en av forskarna som genomförde studien, berättade för Tech Xplore. "En huvudutmaning är att den måste hantera tusentals olika scenarier. Vanligtvis, vi definierar en belöning/kostnadsfunktionell inställning som kan anpassa dessa skillnader i scenarier. Dock, vi tycker att det är en svår uppgift."
Vanligtvis, belöning-kostnad funktionell inställning kräver omfattande arbete på uppdrag av forskare, samt resurser och tid på både simuleringar och vägtester. Dessutom, miljön kan förändras dramatiskt över tiden och när körförhållandena blir mer komplicerade, att justera prestandan för rörelseplaneraren blir allt svårare.

Algoritmavstämningsslinga för rörelseplaneraren i Apollo autonoma körplattform. Kredit:Fan et al.
"För att systematiskt lösa detta problem, vi utvecklade ett datadrivet ramverk för automatisk justering baserat på Apollos ramverk för autonom körning, "Fläkten sa. "Idén med auto-tuning är att lära sig parametrar från mänskliga demonstrerade kördata. Till exempel, vi skulle vilja förstå från data hur mänskliga förare balanserar hastighet och körbekvämlighet med hinderavstånd. Men i mer komplicerade scenarier, till exempel, en fullsatt stad, vad kan vi lära oss av mänskliga förare?"
Ramverket för automatisk justering som utvecklats på Baidu inkluderar en ny förstärkningsinlärningsalgoritm, som kan lära av data och förbättra dess prestanda över tid. Jämfört med de flesta omvända förstärkningsinlärningsalgoritmer, den kan effektivt tillämpas på olika körscenarier.
Ramverket inkluderar också en offlineutbildningsstrategi, erbjuder ett säkert sätt för forskare att justera parametrar innan ett autonomt fordon testas på allmänna vägar. Den samlar också in data från expertförare och information om miljön, automatiskt märka dessa så att de kan analyseras med förstärkningsinlärningsalgoritmen.
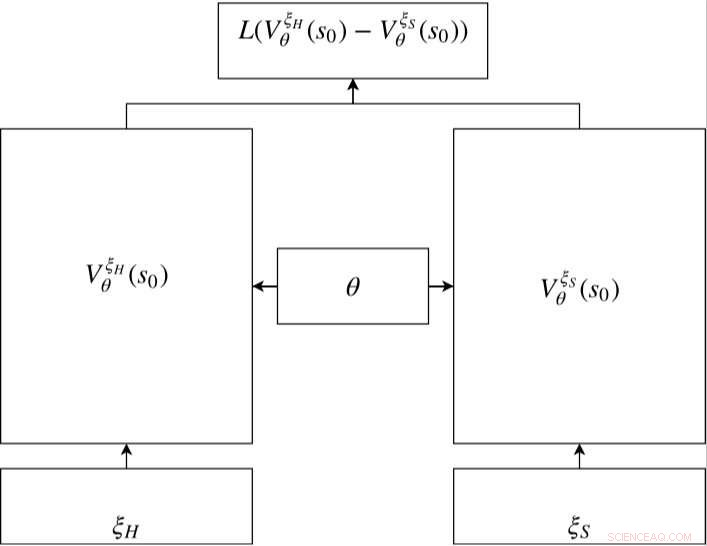
Siamesiskt nätverk i RC-IRL. Värdenätverken för både den mänskliga och de samplade banorna delar samma nätverksparameterinställningar. Förlustfunktionen utvärderar skillnaden mellan samplade data och den genererade banan via värdenätverksutgångarna. Kredit:Fan et al.
"Jag tror att vi utvecklade en säker pipeline för att göra ett maskininlärning skalbart system genom att använda mänskliga demonstrationsdata, "Fläkten sa. "Den öppna slingan mänskliga demodata samlas in och behöver inte extra märkning. Eftersom utbildningsprocessen också är offline, vår metod är lämplig för autonom körningsplanering, upprätthålla trafiksäkerheten på vägarna."
Forskarna utvärderade en rörelseplanerare som justerades med deras ramverk både på simuleringar och tester på allmän väg. Jämfört med befintliga metoder, deras datadrivna metod kunde bättre anpassa sig till olika körscenarier, presterar genomgående bra under en mängd olika förhållanden.
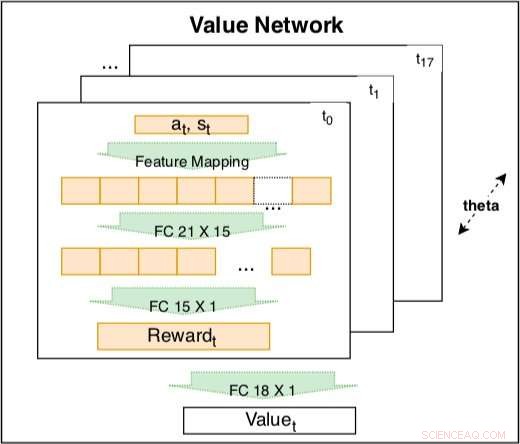
Värdenätverket inuti den siamesiska modellen används för att fånga körbeteende baserat på kodade funktioner. Nätverket är en träningsbar linjär kombination av kodade belöningar vid olika tidpunkter t =t0, ..., t17. Vikten av den kodade belöningen är en inlärbar tidsförfallsfaktor. Den kodade belöningen inkluderar ett indatalager med 21 råfunktioner och ett dolt lager med 15 noder för att täcka möjliga interaktioner. Parametrarna för belöningen vid olika tidpunkter delar samma θ för att bibehålla konsistensen. Kredit:Fan et al.
"Vår forskning är baserad på Baidu Apollo Open Source Autonomous Driving-plattform, ", sa Fan. "Vi hoppas att fler och fler människor från akademin och industrin kan bidra till det autonoma körekosystemet genom Apollo. I framtiden, vi planerar att förbättra det nuvarande ramverket för Baidu Apollo till ett skalbart system för maskininlärning som systematiskt kan förbättra scenariotäckningen för autonoma bilar."
© 2018 Tech Xplore