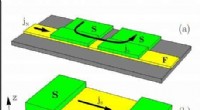
En ny fotonisk chipdesign minskar drastiskt energi som behövs för att beräkna med ljus, med simuleringar som tyder på att det skulle kunna driva optiska neurala nätverk 10 miljoner gånger mer effektivt än sina elektriska motsvarigheter. Kredit:MIT News
MIT-forskare har utvecklat ett nytt "fotoniskt" chip som använder ljus istället för elektricitet - och förbrukar relativt lite ström i processen. Chipet skulle kunna användas för att bearbeta massiva neurala nätverk miljontals gånger mer effektivt än dagens klassiska datorer gör.
Neurala nätverk är maskininlärningsmodeller som används ofta för sådana uppgifter som robotisk objektidentifiering, naturlig språkbehandling, läkemedelsutveckling, medicinsk bildbehandling, och driva förarlösa bilar. Nya optiska neurala nätverk, som använder optiska fenomen för att påskynda beräkningen, kan köra mycket snabbare och mer effektivt än sina elektriska motsvarigheter.
Men när traditionella och optiska neurala nätverk blir mer komplexa, de äter upp massor av kraft. För att ta itu med den frågan, forskare och stora teknikföretag – inklusive Google, IBM, och Tesla – har utvecklat "AI-acceleratorer, " specialiserade chips som förbättrar hastigheten och effektiviteten för att träna och testa neurala nätverk.
För elektriska chips, inklusive de flesta AI-acceleratorer, det finns en teoretisk minimigräns för energiförbrukning. Nyligen, MIT-forskare har börjat utveckla fotoniska acceleratorer för optiska neurala nätverk. Dessa marker utför storleksordningar mer effektivt, men de förlitar sig på några skrymmande optiska komponenter som begränsar deras användning till relativt små neurala nätverk.
I en tidning publicerad i Fysisk granskning X , MIT-forskare beskriver en ny fotonaccelerator som använder mer kompakta optiska komponenter och optiska signalbehandlingstekniker, för att drastiskt minska både strömförbrukning och chiparea. Det gör det möjligt för chipet att skala till neurala nätverk flera storleksordningar större än dess motsvarigheter.
Simulerad träning av neurala nätverk på MNIST-bildklassificeringsdataset antyder att acceleratorn teoretiskt kan bearbeta neurala nätverk mer än 10 miljoner gånger under energiförbrukningsgränsen för traditionella elektriska acceleratorer och cirka 1, 000 gånger under gränsen för fotoniska acceleratorer. Forskarna arbetar nu med ett prototypchip för att experimentellt bevisa resultaten.
"Människor letar efter teknik som kan räkna bortom de grundläggande gränserna för energiförbrukning, " säger Ryan Hamerly, en postdoc vid Forskningslaboratoriet för elektronik. "Fotoniska acceleratorer är lovande ... men vår motivation är att bygga en [fotonisk accelerator] som kan skala upp till stora neurala nätverk."
Praktiska tillämpningar för sådana tekniker inkluderar att minska energiförbrukningen i datacenter. "Det finns en växande efterfrågan på datacenter för att driva stora neurala nätverk, och det blir allt mer beräkningsmässigt svårlöst när efterfrågan växer, säger medförfattaren Alexander Sludds, en doktorand vid forskningslaboratoriet för elektronik. Syftet är "att möta beräkningsefterfrågan med neural nätverkshårdvara ... för att ta itu med flaskhalsen av energiförbrukning och latens."
Med Sludds och Hamerly på tidningen är medförfattaren Liane Bernstein, en RLE doktorand; Marin Soljacic, en MIT-professor i fysik; och Dirk Englund, en MIT docent i elektroteknik och datavetenskap, en forskare inom RLE, och chef för Quantum Photonics Laboratory.
Kompakt design
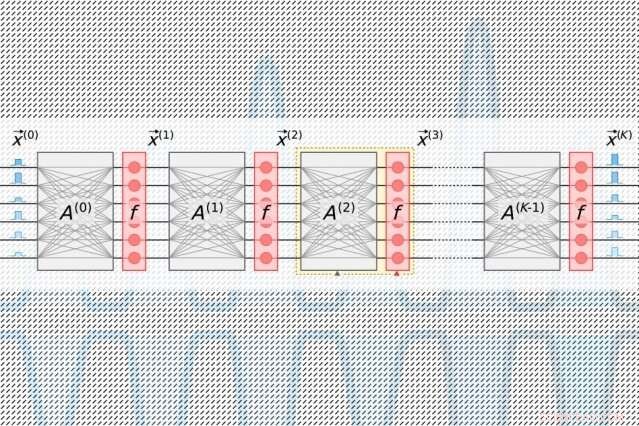
Neurala nätverk bearbetar data genom många beräkningsskikt som innehåller sammankopplade noder, kallas "neuroner, " för att hitta mönster i datan. Neuroner tar emot input från sina uppströmsgrannar och beräknar en utsignal som skickas till neuroner längre nedströms. Varje ingång tilldelas också en "vikt, " ett värde baserat på dess relativa betydelse för alla andra indata. När data sprids "djupare" genom lager, nätverket lär sig allt mer komplex information. I slutet, ett utdatalager genererar en förutsägelse baserat på beräkningarna genom lagren.
Alla AI-acceleratorer syftar till att minska energin som behövs för att bearbeta och flytta runt data under ett specifikt linjärt algebrasteg i neurala nätverk, kallas "matrismultiplikation". Där, neuroner och vikter kodas i separata tabeller med rader och kolumner och kombineras sedan för att beräkna utdata.
I traditionella fotoniska acceleratorer, pulsade lasrar kodade med information om varje neuron i ett lager strömmar in i vågledare och genom stråldelare. De resulterande optiska signalerna matas in i ett rutnät av kvadratiska optiska komponenter, kallade "Mach-Zehnder interferometrar, " som är programmerade att utföra matrismultiplikation. Interferometrarna, som är kodade med information om varje vikt, använda signalinterferenstekniker som bearbetar de optiska signalerna och viktvärdena för att beräkna en utdata för varje neuron. Men det finns ett skalningsproblem:för varje neuron måste det finnas en vågledare och, för varje vikt, det måste finnas en interferometer. Eftersom antalet vikter kvadrat med antalet neuroner, dessa interferometrar tar upp mycket fastigheter.
"Du inser snabbt att antalet ingångsneuroner aldrig kan vara större än 100 eller så, eftersom du inte får plats med så många komponenter på chipet, " säger Hamerly. "Om din fotonaccelerator inte kan bearbeta mer än 100 neuroner per lager, då gör det det svårt att implementera stora neurala nätverk i den arkitekturen."
Forskarnas chip förlitar sig på en mer kompakt, energieffektivt "optoelektroniskt" system som kodar data med optiska signaler, men använder "balanserad homodyndetektion" för matrismultiplikation. Det är en teknik som producerar en mätbar elektrisk signal efter att ha beräknat produkten av amplituder (våghöjder) för två optiska signaler.
Ljuspulser kodade med information om ingångs- och utgångsneuronerna för varje neurala nätverkslager - som behövs för att träna nätverket - flödar genom en enda kanal. Separata pulser kodade med information om hela rader av vikter i matrismultiplikationstabellen flödar genom separata kanaler. Optiska signaler som bär neuron och viktdata fläktar ut till rutnät av homodyna fotodetektorer. Fotodetektorerna använder signalernas amplitud för att beräkna ett utdatavärde för varje neuron. Varje detektor matar en elektrisk utsignal för varje neuron till en modulator, som omvandlar signalen tillbaka till en ljuspuls. Den optiska signalen blir ingången för nästa lager, och så vidare.
Designen kräver bara en kanal per ingångs- och utgångsneuron, och bara så många homodyna fotodetektorer som det finns neuroner, inte vikter. Eftersom det alltid finns mycket färre neuroner än vikter, detta sparar stort utrymme, så chippet kan skalas till neurala nätverk med mer än en miljon neuroner per lager.
Att hitta den söta platsen
Med fotoniska acceleratorer, det finns ett oundvikligt brus i signalen. Ju mer ljus som matas in i chipet, desto mindre brus och större noggrannhet – men det blir ganska ineffektivt. Mindre ingående ljus ökar effektiviteten men påverkar det neurala nätverkets prestanda negativt. Men det finns en "sweet spot, Bernstein säger, som använder minimal optisk effekt samtidigt som noggrannheten bibehålls.
Den söta punkten för AI-acceleratorer mäts i hur många joule som krävs för att utföra en enda operation för att multiplicera två tal – till exempel under matrismultiplikation. Just nu, traditionella acceleratorer mäts i picojoule, eller en biljondels joule. Fotoniska acceleratorer mäter i attojoule, vilket är en miljon gånger effektivare.
I sina simuleringar, forskarna fann att deras fotonaccelerator kunde fungera med sub-attojoule effektivitet. "Det finns en viss minimal optisk effekt du kan skicka in, innan du tappar noggrannheten. Den grundläggande gränsen för vårt chip är mycket lägre än traditionella acceleratorer ... och lägre än andra fotoniska acceleratorer, " säger Bernstein.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.