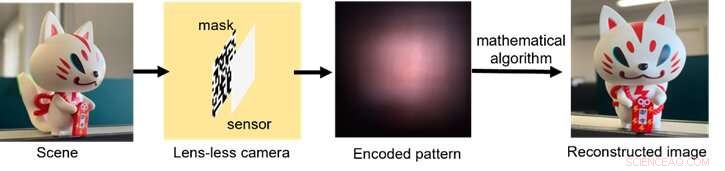
Ett schema över hur den linslösa avbildningsprocessen fungerar, från ljusinsamling via kodning av signalen till efterbehandling med datoralgoritmer. Kredit:Xiuxi Pan från Tokyo Tech
En kamera kräver vanligtvis ett linssystem för att fånga en fokuserad bild, och linskameran har varit den dominerande bildlösningen i århundraden. En kamera med objektiv kräver ett komplext linssystem för att uppnå högkvalitativa, ljusa och aberrationsfria bilder. De senaste decennierna har sett en ökning i efterfrågan på mindre, lättare och billigare kameror. Det finns ett tydligt behov av nästa generations kameror med hög funktionalitet, tillräckligt kompakta för att kunna installeras var som helst. Miniatyriseringen av den objektiverade kameran begränsas dock av linssystemet och det fokuseringsavstånd som krävs av refraktiva linser.
De senaste framstegen inom datorteknik kan förenkla linssystemet genom att ersätta vissa delar av det optiska systemet med datoranvändning. Hela objektivet kan överges tack vare användningen av bildrekonstruktionsdatorer, vilket möjliggör en linslös kamera, som är ultratunn, lätt och låg kostnad. Den objektivfria kameran har fått draghjälp nyligen. Men hittills har bildrekonstruktionstekniken inte etablerats, vilket resulterar i otillräcklig bildkvalitet och tråkig beräkningstid för den objektivfria kameran.
Nyligen har forskare utvecklat en ny bildrekonstruktionsmetod som förbättrar beräkningstiden och ger bilder av hög kvalitet. En kärnmedlem i forskargruppen, prof. Masahiro Yamaguchi från Tokyo Tech, beskriver den initiala motivationen bakom forskningen:"Utan begränsningarna hos en lins skulle den linslösa kameran kunna vara ultraminiatyr, vilket skulle kunna möjliggöra nya tillämpningar som är bortom vår fantasi." Deras arbete har publicerats i Optics Letters .
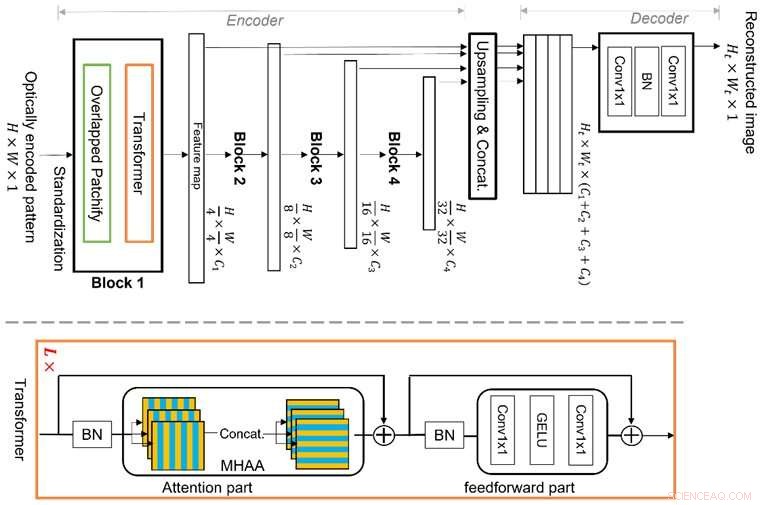
Vision Transformer (ViT) är en ledande maskininlärningsteknik, som är bättre på globala funktionsresonemang på grund av dess nya struktur av flerstegstransformatorblocken med överlappande "patchify"-moduler. Detta gör det möjligt för den att effektivt lära sig bildfunktioner i en hierarkisk representation, vilket gör den i stånd att adressera multiplexeringsegenskapen och undvika begränsningarna med konventionell CNN-baserad djupinlärning, vilket möjliggör bättre bildrekonstruktion. Kredit:Xiuxi Pan från Tokyo Tech
Den typiska optiska hårdvaran för den objektivfria kameran består helt enkelt av en tunn mask och en bildsensor. Bilden rekonstrueras sedan med hjälp av en matematisk algoritm. Masken och sensorn kan tillverkas tillsammans i etablerade halvledartillverkningsprocesser för framtida produktion. Masken kodar optiskt det infallande ljuset och kastar mönster på sensorn. Även om de gjutna mönstren är helt omöjliga att tolka för det mänskliga ögat, kan de avkodas med explicit kunskap om det optiska systemet.
Avkodningsprocessen – baserad på bildrekonstruktionsteknik – är dock fortfarande utmanande. Traditionella modellbaserade avkodningsmetoder approximerar den fysiska processen för den linslösa optiken och rekonstruerar bilden genom att lösa ett "konvext" optimeringsproblem. Detta betyder att rekonstruktionsresultatet är mottagligt för de ofullkomliga approximationerna av den fysiska modellen. Dessutom är beräkningen som behövs för att lösa optimeringsproblemet tidskrävande eftersom den kräver iterativ beräkning. Deep learning kan hjälpa till att undvika begränsningarna med modellbaserad avkodning, eftersom den kan lära sig modellen och avkoda bilden genom en icke-iterativ direkt process istället. Befintliga metoder för djupinlärning för linslös avbildning, som använder ett konvolutionellt neuralt nätverk (CNN), kan dock inte producera bilder av hög kvalitet. De är ineffektiva eftersom CNN bearbetar bilden baserat på relationerna mellan närliggande "lokala" pixlar, medan linslös optik omvandlar lokal information i scenen till överlappande "global" information om alla pixlar i bildsensorn, genom en egenskap som kallas "multiplexing". "

Den linslösa kameran består av en mask och en bildsensor med 2,5 mm separationsavstånd. Masken är tillverkad genom kromavsättning i en platta av syntetiskt kiseldioxid med en öppningsstorlek på 40×40 μm. Kredit:Xiuxi Pan från Tokyo Tech
Tokyo Tech forskargruppen studerar denna multiplexeringsegenskap och har nu föreslagit en ny, dedikerad maskininlärningsalgoritm för bildrekonstruktion. Den föreslagna algoritmen är baserad på en ledande maskininlärningsteknik som kallas Vision Transformer (ViT), som är bättre på globala funktionsresonemang. Det nya med algoritmen ligger i strukturen hos flerstegstransformatorblocken med överlappande "patchify"-moduler. Detta gör att den effektivt kan lära sig bildfunktioner i en hierarkisk representation. Följaktligen kan den föreslagna metoden väl adressera multiplexeringsegenskapen och undvika begränsningarna av konventionell CNN-baserad djupinlärning, vilket möjliggör bättre bildrekonstruktion.
Medan konventionella modellbaserade metoder kräver långa beräkningstider för iterativ bearbetning, är den föreslagna metoden snabbare eftersom den direkta rekonstruktionen är möjlig med en iterativ-fri bearbetningsalgoritm designad av maskininlärning. Inverkan av modellapproximationsfel minskar också dramatiskt eftersom maskininlärningssystemet lär sig den fysiska modellen. Dessutom använder den föreslagna ViT-baserade metoden globala funktioner i bilden och är lämplig för att bearbeta gjutna mönster över ett brett område på bildsensorn, medan konventionella maskininlärningsbaserade avkodningsmetoder huvudsakligen lär sig lokala relationer av CNN.
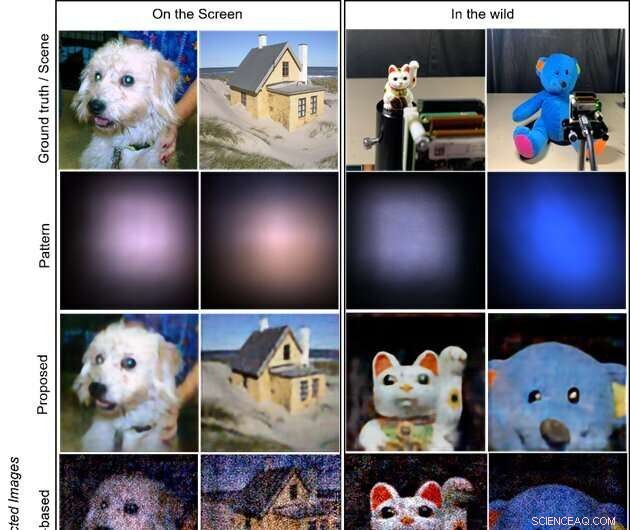
Målen är bilderna som visas på en LCD-skärm (vänster två kolumner) och objekten i det vilda (högra två kolumner; vinkande kattdocka respektive uppstoppad björn). Den första raden visar sanningsbilderna som visas på skärmen och inspelningsscenerna för vilda föremål. Den andra raden visar de fångade mönstren på sensorn. De sista tre raderna illustrerar de rekonstruerade bilderna med de föreslagna, modellbaserade respektive CNN-baserade metoderna. Den föreslagna metoden ger de mest högkvalitativa och visuellt tilltalande bilderna. Kredit:Xiuxi Pan från Tokyo Tech
Sammanfattningsvis löser den föreslagna metoden begränsningarna för konventionella metoder såsom iterativ bildrekonstruktionsbaserad bearbetning och CNN-baserad maskininlärning med ViT-arkitekturen, vilket möjliggör förvärv av högkvalitativa bilder på kort beräkningstid. Forskargruppen utförde vidare optiska experiment – som rapporterats i deras senaste publikation i – som tyder på att den linslösa kameran med den föreslagna rekonstruktionsmetoden kan producera högkvalitativa och visuellt tilltalande bilder samtidigt som hastigheten på efterbehandlingsberäkningen är tillräckligt hög för verklig- tidsfångst.
"Vi inser att miniatyrisering inte borde vara den enda fördelen med den linslösa kameran. Den linslösa kameran kan appliceras på osynligt ljus, där användningen av en lins är opraktisk eller till och med omöjlig. Dessutom är den underliggande dimensionaliteten hos infångad optisk information av den linslösa kameran är större än två, vilket gör en 3D-bildtagning och omfokusering efter fånga möjlig. Vi utforskar fler funktioner hos den linslösa kameran. Det slutliga målet med en linslös kamera är att vara miniatyr-men ändå mäktig. Vi är glada över att vara ledande i denna nya riktning för nästa generations bildbehandlings- och avkänningslösningar", säger huvudförfattaren till studien, Mr. Xiuxi Pan från Tokyo Tech, medan han pratar om sitt framtida arbete. + Utforska vidare