Ljus, som ett elektromagnetiskt fält, har två väsentliga komponenter:amplitud och fas. Optiska detektorer, som vanligtvis förlitar sig på foton-till-elektronkonvertering (som laddningskopplade enhetssensorer och det mänskliga ögat), kan dock inte fånga ljusfältets fas på grund av deras begränsade samplingsfrekvens.
Lyckligtvis, när ljusfältet fortplantar sig, orsakar fasfördröjningen också förändringar i amplitudfördelningen; därför kan vi registrera amplituden för det fortplantade ljusfältet och sedan beräkna motsvarande fas, kallad fasåterställning.
Några vanliga fasåterställningsmetoder inkluderar holografi/interferometri, Shack-Hartmann vågfrontsavkänning, transport av intensitetsekvation och optimeringsbaserade metoder (fashämtning). De har sina egna brister i termer av rums-temporal upplösning, beräkningskomplexitet och tillämpningsområde.
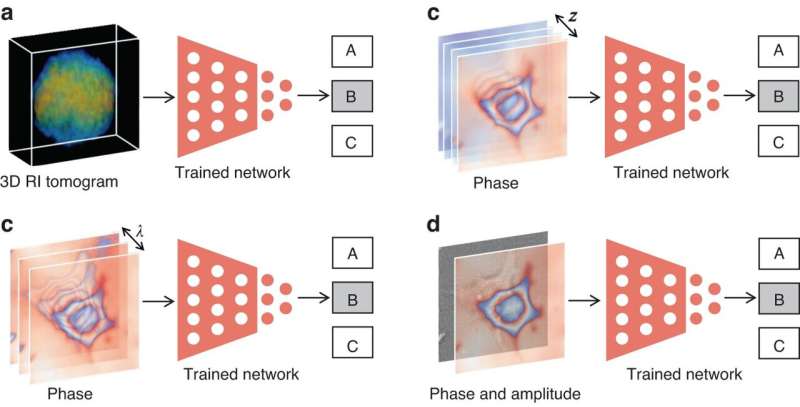
Under de senaste åren, som ett viktigt steg mot sann artificiell intelligens (AI), har djupinlärning, ofta implementerad genom djupa neurala nätverk, uppnått oöverträffad prestanda i fasåterställning.
I en recensionsartikel publicerad i Light:Science &Applications , har forskare från University of Hong Kong, Northwestern Polytechnical University, The Chinese University of Hong Kong, Guangdong University of Technology och Massachusetts Institute of Technology granskat olika metoder för återhämtning i djupinlärningsfas ur följande fyra perspektiv:
För att låta läsarna lära sig mer om fasåterställning presenterade de också en resurs för liveuppdatering (https://github.com/kqwang/phase-recovery).
När djupinlärning tillämpas på olika processer av fasåterhämtning, ger det inte bara oöverträffade effekter utan introducerar också några oförutsägbara risker. Vissa metoder kan se likadana ut, men det finns skillnader som är svåra att upptäcka. Dessa forskare pekar på skillnaderna och sambanden mellan några liknande metoder och gav förslag på hur man kan få ut det mesta av djupinlärning och fysiska modeller för fasåterhämtning:
"Det bör noteras att uPD-schemat (otränad fysikdrivet) är fritt från många intensitetsbilder som en förutsättning, men kräver många iterationer för varje slutledning; medan tPD-schemat (tränad fysikdrivet) slutför slutsatsen endast genom att tränade neurala nätverk en gång, men kräver ett stort antal intensitetsbilder för förträning."
"zf är en fast vektor, vilket innebär att ingången från det neurala nätverket är oberoende av provet, och därför kan det neurala nätverket inte förtränas som PD-metoden", sa de när de introducerade strategin för strukturellt tidigare nätverk i fysik. .
"Inlärningsbaserade djupa neurala nätverk har enorm potential och effektivitet, medan konventionella fysikbaserade metoder är mer tillförlitliga. Vi uppmuntrar därför inkorporeringen av fysiska modeller med djupa neurala nätverk, särskilt för de som väl modellerar från den verkliga världen, snarare än att låta djupa neurala nätverk utför alla uppgifter som en "svart låda", sa forskarna.
Mer information: Kaiqiang Wang et al, Om användningen av djupinlärning för fasåterställning, Light:Science &Applications (2024). DOI:10.1038/s41377-023-01340-x
Journalinformation: Ljus:Vetenskap och tillämpningar
Tillhandahålls av Light Publishing Center, Changchun Institute of Optics, Fine Mechanics And Physics, CAS