En forskare har precis skrivit klart en vetenskaplig artikel. Hon vet att hennes arbete kan dra nytta av ett annat perspektiv. Förbisåg hon något? Eller kanske finns det en tillämpning av hennes forskning som hon inte hade tänkt på. En andra uppsättning ögon skulle vara bra, men även de vänligaste av samarbetspartners kanske inte kan avvara tid för att läsa alla nödvändiga bakgrundspublikationer för att komma ikapp.
Kevin Yager – ledare för gruppen för elektroniska nanomaterial vid Center for Functional Nanomaterials (CFN), ett US Department of Energy (DOE) Office of Science User Facility vid DOE:s Brookhaven National Laboratory – har föreställt sig hur de senaste framstegen inom artificiell intelligens (AI) och maskininlärning (ML) kan hjälpa vetenskaplig brainstorming och idéer. För att åstadkomma detta har han utvecklat en chatbot med kunskap inom den typ av vetenskap han har varit engagerad i.
Snabba framsteg inom AI och ML har gett vika för program som kan generera kreativ text och användbar mjukvarukod. Dessa allmänna chatbots har nyligen fångat allmänhetens fantasi. Befintliga chatbots – baserade på stora, olika språkmodeller – saknar detaljerad kunskap om vetenskapliga underdomäner.
Genom att utnyttja en metod för att hämta dokument är Yagers bot kunnig inom områden av nanomaterialvetenskap som andra botar inte är. Detaljerna om detta projekt och hur andra forskare kan utnyttja denna AI-kollega för sitt eget arbete har nyligen publicerats i Digital Discovery .
"CFN har under lång tid letat efter nya sätt att utnyttja AI/ML för att påskynda upptäckten av nanomaterial. För närvarande hjälper det oss att snabbt identifiera, katalogisera och välja prover, automatisera experiment, kontrollera utrustning och upptäcka nya material. Esther Tsai, en vetenskapsman i gruppen för elektroniska nanomaterial vid CFN, utvecklar en AI-kompanjon för att påskynda materialforskningsexperiment vid National Synchrotron Light Source II (NSLS-II)." NSLS-II är en annan DOE Office of Science User Facility vid Brookhaven Lab.
På CFN har det varit mycket arbete med AI/ML som kan hjälpa till att driva experiment genom användning av automation, kontroller, robotik och analys, men att ha ett program som var skickligt med vetenskaplig text var något som forskare inte hade utforskat lika djupt. Att snabbt kunna dokumentera, förstå och förmedla information om ett experiment kan hjälpa till på flera sätt – från att bryta ner språkbarriärer till att spara tid genom att sammanfatta större delar av arbetet.
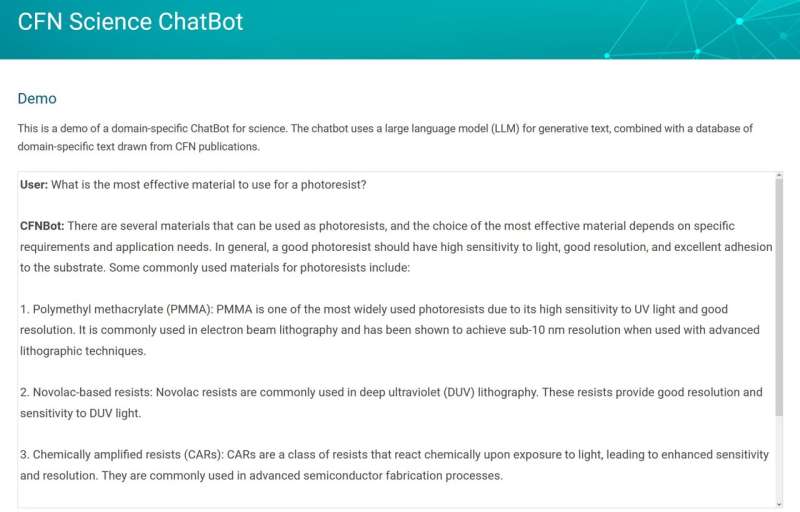
Titta på ditt språk
För att bygga en specialiserad chatbot krävde programmet domänspecifik text – språk hämtat från områden som boten är avsedd att fokusera på. I det här fallet är texten vetenskapliga publikationer. Domänspecifik text hjälper AI-modellen att förstå ny terminologi och definitioner och introducerar den till gränsöverskridande vetenskapliga begrepp. Viktigast av allt är att denna utvalda uppsättning dokument gör det möjligt för AI-modellen att grunda sina resonemang med hjälp av pålitliga fakta.
För att efterlikna det naturliga mänskliga språket tränas AI-modeller på befintlig text, vilket gör det möjligt för dem att lära sig språkets struktur, memorera olika fakta och utveckla en primitiv sorts resonemang. Istället för att mödosamt träna om AI-modellen på nanovetenskaplig text, gav Yager den möjligheten att slå upp relevant information i en utvald uppsättning publikationer. Att förse den med ett bibliotek med relevant data var bara halva striden. För att använda den här texten korrekt och effektivt skulle boten behöva ett sätt att dechiffrera det korrekta sammanhanget.
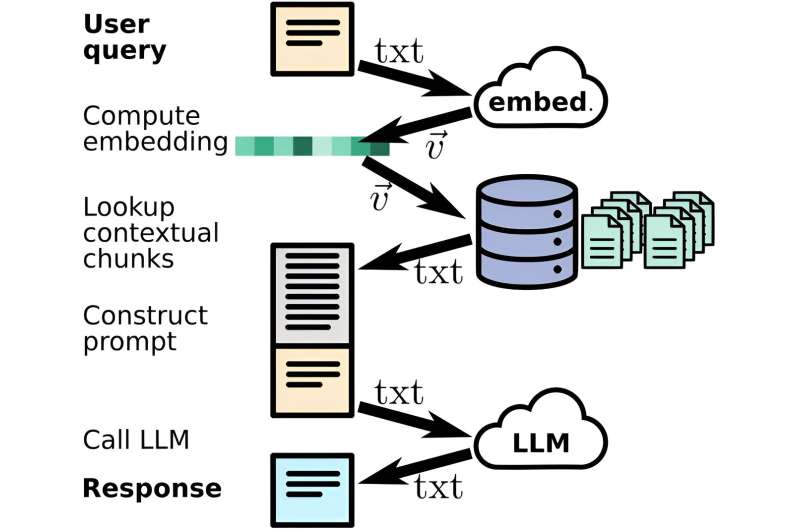
"En utmaning som är vanlig med språkmodeller är att de ibland "hallucinerar" trovärdiga men osanna saker," förklarade Yager. "Det här har varit en kärnfråga att lösa för en chatbot som används i forskning i motsats till en som gör något som att skriva poesi. Vi vill inte att den ska fabricera fakta eller citat. Detta behövde åtgärdas. Lösningen för detta var något vi kalla "inbäddning", ett sätt att kategorisera och länka information snabbt bakom kulisserna."
Inbäddning är en process som omvandlar ord och fraser till numeriska värden. Den resulterande "inbäddningsvektorn" kvantifierar innebörden av texten. När en användare ställer en fråga till chatboten skickas den också till ML-inbäddningsmodellen för att beräkna dess vektorvärde. Denna vektor används för att söka igenom en förberäknad databas med textbitar från vetenskapliga artiklar som var inbäddade på liknande sätt. Boten använder sedan textavsnitt den hittar som är semantiskt relaterade till frågan för att få en mer fullständig förståelse av sammanhanget.
Användarens fråga och textsnuttarna kombineras till en "prompt" som skickas till en stor språkmodell, ett expansivt program som skapar text modellerad på naturligt mänskligt språk, som genererar det slutliga svaret. Inbäddningen säkerställer att texten som dras är relevant i sammanhanget med användarens fråga. Genom att tillhandahålla textbitar från huvuddelen av betrodda dokument genererar chatboten svar som är sakliga och hämtade.
"Programmet måste vara som en referensbibliotekarie", sa Yager. "Det måste i hög grad förlita sig på dokumenten för att ge svar från källor. Det måste kunna tolka vad folk frågar på ett korrekt sätt och kunna effektivt sammanställa sammanhanget för dessa frågor för att hämta den mest relevanta informationen. Även om svaren kanske inte vara perfekt ännu, den kan redan svara på utmanande frågor och väcka några intressanta tankar när du planerar nya projekt och forskning."
Bots som stärker människor
CFN utvecklar AI/ML-system som verktyg som kan befria mänskliga forskare att arbeta med mer utmanande och intressanta problem och att få ut mer av sin begränsade tid medan datorer automatiserar repetitiva uppgifter i bakgrunden. Det finns fortfarande många okända saker om detta nya sätt att arbeta, men dessa frågor är början på viktiga diskussioner som forskare för just nu för att säkerställa att AI/ML-användning är säker och etisk.
"Det finns ett antal uppgifter som en domänspecifik chatbot som denna skulle kunna klara av en forskares arbetsbelastning. Klassificering och organisering av dokument, sammanfatta publikationer, peka ut relevant information och få fart på ett nytt aktuellt område är bara några av möjligheter ansökningar", anmärkte Yager. "Jag är dock spänd på att se vart allt detta kommer att ta vägen. Vi hade aldrig kunnat föreställa oss var vi är nu för tre år sedan, och jag ser fram emot var vi kommer att vara om tre år."
För forskare som är intresserade av att prova den här programvaran själva, kan källkoden för CFN:s chatbot och tillhörande verktyg hittas i detta GitHub-förråd.
Mer information: Kevin G. Yager, domänspecifika chatbotar för vetenskap som använder inbäddningar, Digital Discovery (2023). DOI:10.1039/D3DD00112A
Tillhandahålls av Brookhaven National Laboratory