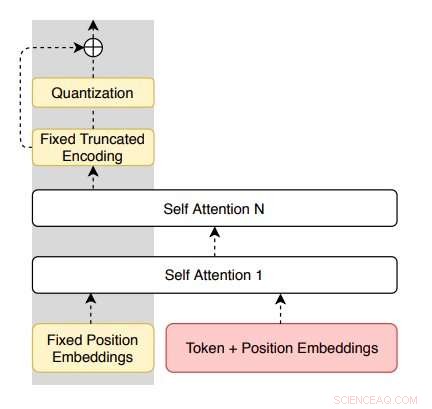
Arkitektur av kodaren föreslagen av forskarna. Kredit:Roy &Grangier.
På senare år har forskare har försökt utveckla metoder för automatisk omskrivning, vilket i huvudsak innebär automatiserad abstraktion av semantiskt innehåll från text. Än så länge, metoder som bygger på maskinöversättningstekniker (MT) har visat sig vara särskilt populära på grund av bristen på tillgängliga märkta datamängder av parafraserade par.
Teoretiskt sett, översättningstekniker kan verka som effektiva lösningar för automatisk parafrasering, eftersom de abstraherar semantiskt innehåll från dess språkliga förverkligande. Till exempel, att tilldela samma mening till olika översättare kan resultera i olika översättningar och en rik uppsättning tolkningar, vilket kan vara användbart vid omskrivning av uppgifter.
Även om många forskare har utvecklat översättningsbaserade metoder för automatiserad parafrasering, människor behöver inte nödvändigtvis vara tvåspråkiga för att parafrasera meningar. Baserat på denna observation, två forskare vid Google Research har nyligen föreslagit en ny parafraseringsteknik som inte är beroende av maskinöversättningsmetoder. I deras tidning, förpublicerad på arXiv, de jämförde sitt enspråkiga tillvägagångssätt med andra tekniker för parafrasering:en övervakad översättning och en oövervakad översättningsmetod.
"Detta arbete föreslår att man bara ska lära sig parafraserande modeller från en omärkt enspråkig korpus, "Aurko Roy och David Grangier, de två forskarna som genomförde studien, skrev i deras tidning. "För detta ändamål, vi föreslår en restvariant av vektorkvantiserad variationsautokodare."
Modellen som introducerats av forskarna är baserad på vektorkvantiserade autokodare (VQ-VAE) som kan parafrasera meningar i en rent enspråkig miljö. Den har också en unik egenskap (dvs kvarvarande anslutningar parallellt med den kvantiserade flaskhalsen), vilket möjliggör bättre kontroll över avkodarentropin och underlättar optimeringen.
"Jämfört med kontinuerliga automatiska kodare, vår metod tillåter generering av olika, men semantiskt stäng meningar från en inmatad mening, " förklarade forskarna i sin uppsats.
I deras studie, Roy och Grangier jämförde deras modells prestanda med andra MT-baserade metoder för parafrasidentifiering, generations- och utbildningsförstärkning. De jämförde det specifikt med en övervakad översättningsmetod tränad på parallella tvåspråkiga data och en oövervakad översättningsmetod som tränades på icke-parallell text på två olika språk. Deras modell, å andra sidan, kräver endast omärkta data på ett enda språk, den som den parafraserar meningar i.
Forskarna fann att deras enspråkiga tillvägagångssätt överträffade oövervakade översättningstekniker i alla uppgifter. Jämförelser mellan deras modell och övervakade översättningsmetoder, å andra sidan, gav blandade resultat:det enspråkiga tillvägagångssättet fungerade bättre i identifierings- och förstärkningsuppgifter, medan den övervakade översättningsmetoden var överlägsen för parafrasgenerering.
"Övergripande, vi visade att enspråkiga modeller kan överträffa tvåspråkiga modeller för parafrasidentifiering och dataökning genom parafrasering, " drog forskarna slutsatsen. "Vi rapporterade också att generationskvaliteten från enspråkiga modeller kan vara högre än modeller baserade på oövervakad översättning, men inte övervakad översättning."
Roy och Grangiers resultat tyder på att användning av tvåspråkiga parallella data (dvs. texter och deras möjliga översättningar på andra språk) är särskilt fördelaktigt när man genererar omskrivningar och leder till enastående prestanda. I situationer där tvåspråkig data inte är lättillgänglig, dock, den enspråkiga modell som de föreslår skulle kunna vara en användbar resurs eller alternativ lösning.
© 2019 Science X Network