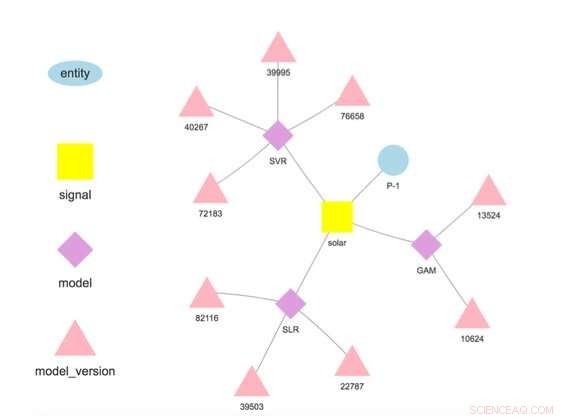
Figur 1. Modellhierarki för en vald enhet och signal. Kredit:IBM
Denna vecka på den internationella konferensen om datautvinning, IBM Research-Ireland-forskaren Francesco Fusco demonstrerade IBM Research Castor, ett system för att hantera tidsseriedata och modeller i stor skala och i molnet. Dagens företag kör på prognoser. Oavsett om en aning om vad vi tror kommer att hända eller produkten av noggrant finslipad analys, vi har en bild av vad som kommer att hända och vi agerar därefter. IBM Research Castor är för IoT-drivna företag som behöver hundratals eller tusentals olika prognoser för tidsserier. Även om modellen för en enskild prognos kan vara liten, Det kan vara en utmaning att hålla jämna steg med ursprunget och prestanda för detta antal modeller. I motsats till AI-drivna fall som använder ett litet antal stora modeller för bildbehandling eller naturligt språk, detta arbete syftar till att IoT-applikationer behöver ett stort antal mindre modeller.
Vårt system tillhandahåller en rik men selektiv uppsättning funktioner för tidsseriedata och modeller. Den matar in data från IoT-enheter eller andra källor. Det ger tillgång till data med hjälp av semantik, tillåter användare att hämta data så här:getTimeseries( myServer, "Store1234", "timintäkter").
Den lagrar modeller skrivna i R eller Python för träning och poäng. Varje modell är associerad med en enhet som beskriver var data härrör från, som "Store1234" ovan, och en signal som beskriver vad som mäts, som "timintäkter". Modeller tränas och poängsätts vid användardefinierade frekvenser, och i motsats till många andra erbjudanden, prognoserna lagras automatiskt.
Dataforskare distribuerar modeller genom att implementera ett arbetsflöde i fyra steg:
När modellen väl har implementerats, systemet utför träningen och poängsättningen, automatiskt lagra den tränade modellen och prognosresultat. Data som används vid träning och poängsättning behöver inte komma från plattformen, tillåter modeller att använda data från flera källor. Faktiskt, detta är en viktig motivering för vårt arbete – att göra mervärdesprognoser baserade på flera datakällor. Till exempel, ett företag kan kombinera vissa av sina egna uppgifter med data som köpts från en tredje part, som väderprognoser, att förutsäga en mängd av intresse.
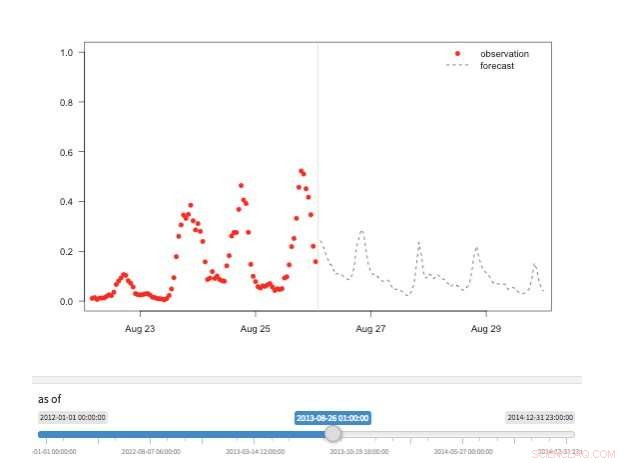
Figur 2. "Tidsmaskin"-vy som visar tillgängliga observationer och prognoser för olika punkter i historien. Kredit:IBM
Vårt system lagrar modeller separat från konfigurations- och körtidsparametrar. Denna separation tillåter ändring av vissa detaljer i en modell, såsom API-nyckeln för åtkomst av tredjepartsdata eller poängfrekvensen, utan omplacering. Flera modeller för samma målvariabel stöds och uppmuntras för att möjliggöra jämförelser av prognoser från olika algoritmer. Modeller kan kedjas samman så att utdata från en modell bildar input till en annan som i en ensemble. En modell tränad på en specifik datauppsättning representerar en modellversion, som också spåras. Således är det möjligt att fastställa härkomsten av modeller och prognoser (Figur 1).
Det finns flera vyer för att utforska prognosvärden. Självklart kan själva värdena hämtas och visualiseras. Vi stöder också en "tidsmaskin"-vy som visar de senaste prognoserna och de senaste observationerna (Figur 2). I denna interaktiva vy, användaren kan välja olika punkter i historien och se vilken information som var tillgänglig vid den tidpunkten. Vi stöder också en syn på prognosutveckling som visar successiva prognoser för samma tidpunkt (Figur 3). På så sätt kan användarna se hur prognoserna förändrades när måltiden närmade sig.
Under huven, IBM Research Castor använder mycket serverlös datoranvändning för att ge resurselasticitet och kostnadskontroll. Typiska installationer ser att modeller tränas varje vecka eller varje månad och får poäng varje timme. Vid träning eller poängtid, en serverlös funktion skapas för varje modell, låter hundratals modeller träna eller göra poäng parallellt vid önskad tidpunkt. Efter detta arbete är över, datorresursen försvinner tills den behövs igen. I ett mer konventionellt arbetsflöde, virtuella maskiner eller molnbehållare är inaktiva när de inte används men drar fortfarande till sig kostnader.
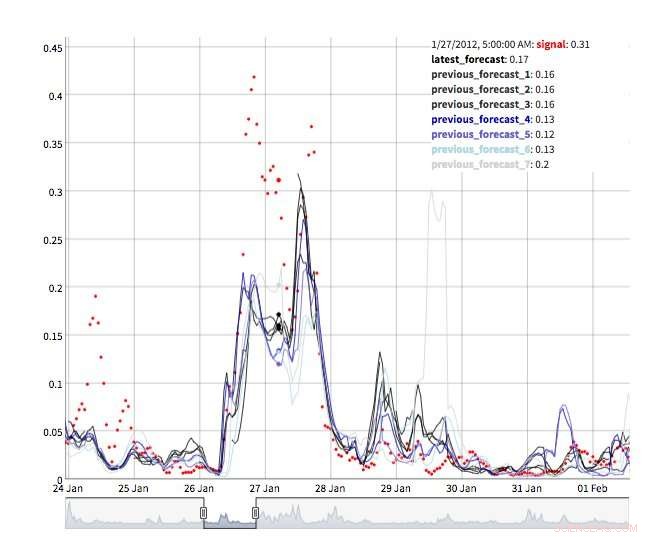
Figur 3. Prognos för utveckling. Kredit:IBM
IBM Research Castor distribueras inbyggt på IBM Cloud med de senaste tjänsterna som IBM:s DashDB, Komponera, Molnfunktioner, och Kubernetes för att tillhandahålla ett robust och pålitligt system. Med ett berättigat konto på IBM Cloud, IBM Research Castor distribueras på några minuter, vilket gör den idealisk för proof-of-concept såväl som längre pågående projekt. Klientpaket/SDK:er för Python och R tillhandahålls så att datavetare kan komma igång snabbt i en bekant miljö och visualiseringsteam kan utnyttja välbekanta ramverk som Django och Shiny. Om de inte passar din ansökan, det JSON-baserade meddelande-API:et är också tillgängligt.
Den här historien återpubliceras med tillstånd av IBM Research. Läs originalberättelsen här.