Kredit:Angewandte Chemie
Databaser som innehåller enorma mängder experimentell data är tillgängliga för forskare inom en mängd olika kemiska discipliner. Ett team av forskare har dock upptäckt att tillgängliga data inte lyckas förutsäga utbytet av nya synteser med hjälp av artificiell intelligens (AI) och maskininlärning. Deras studie publicerad i tidskriften Angewandte Chemie International Edition antyder att detta till stor del beror på forskarnas tendens att inte rapportera misslyckade experiment.
Även om AI-baserade modeller har varit särskilt framgångsrika när det gäller att förutsäga molekylära strukturer och materialegenskaper, returnerar de ganska felaktiga förutsägelser för information om produktutbyte vid syntes, som Frank Glorius och hans team av forskare vid Westfälische Wilhelms-Universität Münster, Tyskland, har upptäckt .
Forskarna tillskriver detta misslyckande till data som används för att träna AI-system. "Intressant nog är förutsägelsen av reaktionsutbyten (reaktivitet) mycket mer utmanande än förutsägelsen av molekylära egenskaper. Reaktanter, reagenser, kvantiteter, förhållanden, det experimentella utförandet - allt bestämmer utbytet, och därmed blir problemet med avkastningsförutsägelse mycket data -intensivt", förklarar Glorius. Så trots de enorma mängderna tillgänglig litteratur och resultat insåg forskarna att data inte är lämpliga för exakta förutsägelser om den förväntade avkastningen.
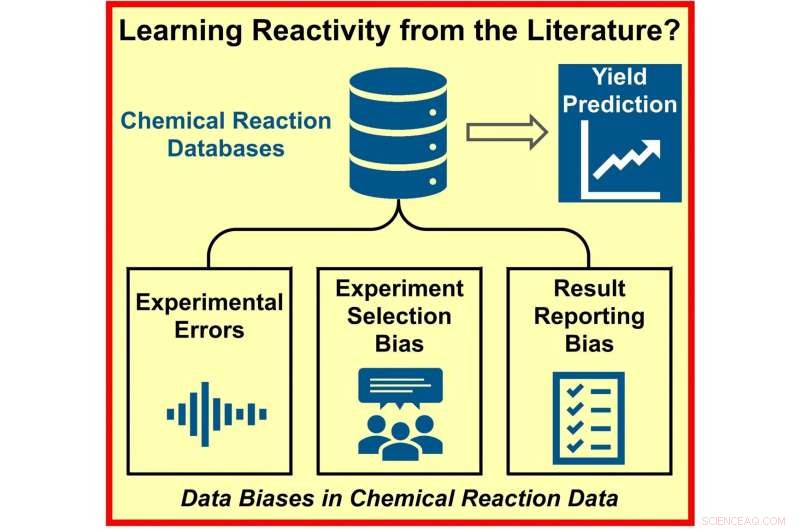
Problemet beror inte bara på bristen på experiment. Däremot identifierade teamet tre möjliga orsaker till partisk data. För det första kan resultaten av kemiska synteser vara felaktiga på grund av experimentella fel. För det andra, när kemister planerar sina experiment, kan de, antingen medvetet eller omedvetet, introducera partiskhet baserad på personlig erfarenhet och beroende av väletablerade metoder. Slutligen, eftersom endast reaktioner med ett positivt utfall tros bidra till framsteg, rapporteras misslyckade reaktioner mer sällan.
För att ta reda på vilken av dessa tre faktorer som hade störst inflytande ändrade Glorius och teamet avsiktligt datamängderna för fyra olika, vanligt förekommande (och därför datarika) organiska reaktioner. De ökade på konstgjord väg det experimentella felet, minskade storleken på datasamplingsuppsättningarna eller tog bort negativa resultat från data. Deras undersökningar visade att det experimentella felet hade den minsta inverkan på modellen, medan bidraget från avsaknaden av negativa resultat var grundläggande.
Gruppen hoppas att dessa fynd kommer att uppmuntra forskare att alltid rapportera misslyckade experiment såväl som deras framgångar. Detta skulle förbättra datatillgängligheten för träning av AI, vilket i slutändan skulle hjälpa till att påskynda planering och göra experimenterandet mer effektivt. Glorius tillägger att "maskininlärning inom (molekylär) kemi kommer att öka effektiviteten dramatiskt och färre reaktioner kommer att behöva köras för att uppnå ett visst mål, till exempel en optimering. Detta kommer att ge kemister kraft och kommer att hjälpa dem att göra kemiska processer - och världen – mer hållbar." + Utforska vidare