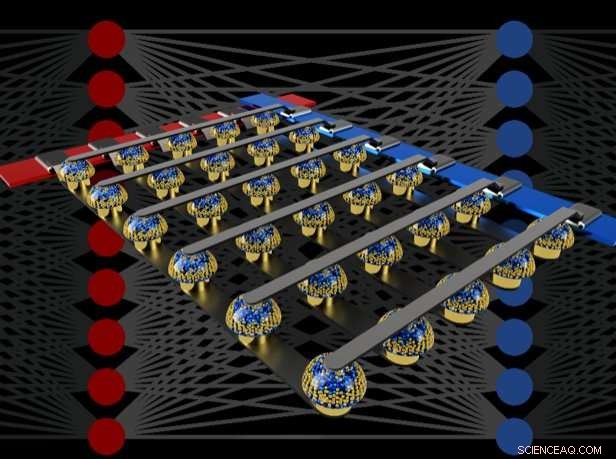
Tvärstångsarrayer med icke-flyktiga minnen kan påskynda utbildningen av fullt anslutna neurala nätverk genom att utföra beräkning på platsen för data. Kredit:IBM
Tänk dig personlig artificiell intelligens (AI), där din smartphone blir mer som en intelligent assistent - känner igen din röst även i ett bullrigt rum, förstå sammanhanget i olika sociala situationer eller bara presentera den information som verkligen är relevant för dig, plockade ur floden av data som kommer varje dag. Sådana förmågor kan snart vara inom räckhåll - men att komma dit kommer att krävas snabbt, kraftfull, energieffektiva AI-hårdvaruacceleratorer.
I en ny tidning publicerad i Natur , vårt IBM Research AI-team demonstrerade djup neuralt nätverk (DNN) utbildning med stora matriser av analoga minnesenheter med samma noggrannhet som ett grafiskt bearbetningsenhet (GPU) -baserat system. Vi tror att detta är ett stort steg på vägen till den typ av hårdvaruacceleratorer som är nödvändiga för nästa AI -genombrott. Varför? För att leverera AI:s framtid kommer att kräva en omfattande utbyggnad av AI -beräkningar.
DNN måste bli större och snabbare, både i molnet och vid kanten-och det betyder att energieffektiviteten måste förbättras dramatiskt. Även om bättre GPU:er eller andra digitala acceleratorer kan hjälpa till i viss mån, sådana system lägger oundvikligen mycket tid och energi på att flytta data från minne till bearbetning och tillbaka. Vi kan förbättra både hastighet och energieffektivitet genom att utföra AI-beräkningar i den analoga domänen precis vid platsen för datan-men det är bara vettigt att göra om de resulterande neurala nätverken är lika smarta som de som implementeras med konventionell digital hårdvara.
Analoga tekniker, som involverar kontinuerligt variabla signaler snarare än binära 0s och 1s, har inneboende gränser för deras precision - varför moderna datorer i allmänhet är digitala datorer. Dock, AI -forskare har börjat inse att deras DNN -modeller fortfarande fungerar bra även när digital precision reduceras till nivåer som skulle vara alldeles för låga för nästan alla andra datorprogram. Således, för DNN, det är möjligt att analog beräkning också kan fungera.
Dock, tills nu, ingen hade slutgiltigt bevisat att sådana analoga metoder kan göra samma jobb som dagens programvara som körs på konventionell digital hårdvara. Det är, kan DNN verkligen tränas till ekvivalent hög noggrannhet med dessa tekniker? Det finns ingen mening med att vara snabbare eller mer energieffektiv vid utbildning av ett DNN om de resulterande klassificeringsnoggrannheterna alltid kommer att vara oacceptabelt låga.
I vårt papper, Vi beskriver hur analoga icke-flyktiga minnen (NVM) effektivt kan påskynda "backpropagation" -algoritmen i hjärtat av många senaste AI-framsteg. Dessa minnen gör att "multiplicera-ackumulera" -operationerna som används genom dessa algoritmer kan parallelliseras i den analoga domänen, på platsen för viktdata, med underliggande fysik. Istället för stora kretsar för att multiplicera och lägga till digitala nummer tillsammans, vi passerar helt enkelt en liten ström genom ett motstånd till en tråd, och anslut sedan många sådana trådar för att låta strömmarna byggas upp. Detta gör att vi kan utföra många beräkningar samtidigt, snarare än den ena efter den andra. Och istället för att skicka digital data på långa resor mellan digitala minneschips och processchips, vi kan utföra all beräkning inuti det analoga minneskretsen.
Dock, på grund av olika brister i dagens analoga minnesenheter, tidigare demonstrationer av DNN-utbildning som utförts direkt på stora matriser med riktiga NVM-enheter lyckades inte uppnå klassificeringsnoggrannheter som matchade de för mjukvarutränade nätverk.
Genom att kombinera långtidslagring i fasändringsminne (PCM) -enheter, nära-linjär uppdatering av konventionella CMOS-kondensatorer (Complementary Metal-Oxide Semiconductor) och nya tekniker för att avbryta variation från enhet till enhet, vi finesserade dessa brister och uppnådde mjukvaruekvivalenta DNN-noggrannheter på en mängd olika nätverk. Dessa experiment använde en blandad hårdvara-programvara, kombinera mjukvarusimuleringar av systemelement som är enkla att modellera exakt (t.ex. CMOS -enheter) tillsammans med fullständig hårdvaruimplementering av PCM -enheterna. Det var viktigt att använda riktiga analoga minnesenheter för varje vikt i våra neurala nätverk, eftersom modelleringsmetoder för sådana nya enheter ofta inte lyckas fånga hela utbudet av enhet-till-enhet-variabilitet som de kan uppvisa.
Med denna metod, vi verifierade att hela chips verkligen borde erbjuda motsvarande noggrannhet, och därmed göra samma jobb som en digital accelerator - men snabbare och med lägre effekt. Med tanke på dessa uppmuntrande resultat, vi har redan börjat utforska designen av prototyp hårdvaruacceleratorchips, som en del av ett IBM Research Frontiers Institute -projekt.
Från dessa tidiga designansträngningar kunde vi tillhandahålla, som en del av vårt naturpapper, initiala uppskattningar för potentialen hos sådana NVM-baserade marker för utbildning av fullt anslutna lager, när det gäller beräkningseffektivitet (28, 065 GOP/sek/W) och genomströmning per område (3,6 TOP/sek/mm2). Dessa värden överstiger specifikationerna för dagens GPU:er med två storleksordningar. Vidare, fullt anslutna lager är en typ av neuralt nätverkslager för vilket den verkliga GPU-prestandan ofta ligger långt under de angivna specifikationerna.
Det här dokumentet indikerar att vårt NVM-baserade tillvägagångssätt kan leverera mjukvaruekvivalenta träningsnoggrannheter samt storleksförbättringar i acceleration och energieffektivitet trots brister i befintliga analoga minnesenheter. Nästa steg blir att visa samma mjukvaruekvivalens på större nätverk som kräver stora, helt anslutna lager-till exempel återkommande anslutna Long Short Term Memory (LSTM) och Gated Recurrent Unit (GRU) nätverk bakom de senaste framstegen inom maskinöversättning, textning och textanalys - och att designa, implementera och förfina dessa analoga tekniker på prototyp NVM-baserade hårdvaruacceleratorer. Nya och bättre former av analogt minne, optimerad för denna applikation, kan hjälpa till att förbättra både arealens densitet och energieffektivitet.