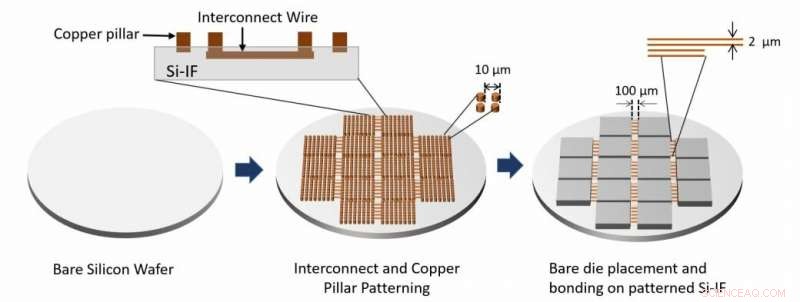
Processflödet för systemmontering visas. Sammankopplingsskikt och kopparpelare tillverkas genom att bearbeta den blotta kiselskivan. Nakna formar fästs sedan på skivan med hjälp av TCB. Kredit:Architecting Waferscale Processors - A GPU Case Study, HPCA 19.
Forskare vid University of Illinois i Urbana-Champaign och University of California, Los Angeles, ligger bakom den senaste utvecklingen av en dator i wafer-skala som syftar till att vara snabbare, mer energieffektiv, än nutida motsvarigheter.
Ingenjörer siktar på att använda något som kallas "silikon interconnect fabric" för att bygga en dator med 40 GPU:er på en enda kiselskiva. TechSpot och andra webbplatser som rapporterat om deras arbete och deras papper, presenteras denna månad.
Lite bakgrund om Si-IF:"Under de senaste två decennierna, kiselchips har minskat i storlek med 1000x, medan paket på kretskort bara har krympt med 4x, " sa UCLA Technology Development Group. En lösning är "kisel sammankopplingsväv (Si-IF)."
Samuel Moore kl IEEE spektrum har en mycket citerad artikel om ämnet där han noterade resultat:"Simuleringar av denna multiprocessor-monsterhastighetsberäkningar nästan 19 gånger och minskar kombinationen av energiförbrukning och signalfördröjning mer än 140 gånger."
Nämligen, forskningssatsningen är bland medlemmar av avdelningen för el- och datateknik, University of California, Los Angeles, och avdelningen för el- och datateknik, University of Illinois i Urbana-Champaign. Deras uppsats har titeln "Architecting Waferscale Processors—A GPU Case Study."
lllinois docent i datorteknik Rakesh Kumar och hans kollegor har redan påbörjat arbetet med att bygga ett prototypsystem för prototypprocessorer i waferscale. Gruppen kommer att utforska det ytterligare för insikter om eventuella problem som kan uppstå. De trodde att tiden var mogen att återbesöka waferscale arkitekturer.
Mark Tyson in Hexus :"Ingenjörer vid University of Illinois Urbana-Champaign och University of California Los Angeles tycker att det är dags att göra ett nytt försök att skapa en dator i wafer-skala."
Accenten kan läggas på ordet återbesök . Teamet skrev i sin tidning, "Inte överraskande, waferscale-processorer studerades hårt på 80-talet. Det gjordes också flera kommersiella försök att bygga waferscale-processorer. Tyvärr, trots löftet, sådana processorer kunde inte hitta framgång i mainstream på grund av avkastningsproblem."
De sa "ju större storleken på processorn, ju lägre utbyte - avkastningen i waferscale på den tiden var försvagande. Vi hävdar att avsevärda framsteg inom tillverknings- och förpackningsteknologi har gjorts sedan dess och att det kan vara dags att se över genomförbarheten av waferscale-processorer."
Docenten i datorteknik i Illinois, Rakesh Kumar, och hans medarbetare är inställda på att göra fallet för en dator i waferscale som består av så många som 40 GPU:er. Den bästa rubriken för att påminna oss om varför detta är intressant finns på IEEE spektrum . "Vad är bättre än 40 GPU-baserade servrar? En server med 40 GPU:er."
Vad är speciellt:De har standard GPU-chips som klarade kvalitetstestning – de skapar en teknik som de kallar silicon interconnect fabric (SiIF) för att bättre ansluta dem.
Shawn Knight in TechSpot skrev om detta. "Med en så snäv integration, sade riddaren, "ur programmerarens perspektiv, det skulle se ut som en gigantisk GPU snarare än 40 individuella GPU:er."
SiIF ersätter kretskortet med kisel; det behövs inget chippaket, sa Moore. Han rapporterade att de i en design kunde klämma in 41 GPU:er. "De testade en simulering av den här designen och fann att den påskyndade både beräkningen och rörelsen av data samtidigt som de förbrukade mindre energi än 40 standard GPU-servrar skulle ha."
Tyson skrev att "som många HEXUS-läsare vet, vanligtvis sprider superdatorer applikationer över hundratals GPU:er på separata PCB:er, kommunicerar över långdistanslänkar. Sådana länkar är långsamma och energiineffektiva jämfört med sammankopplingar inom chiparkitekturen." Han noterade att Kumar talade om att få data från en GPU till en annan som att skapa en otrolig mängd overhead.
IEEE spektrum 's Moore förklarade deras arbete mer detaljerat.
"SiIF-skivan är mönstrad med ett eller flera lager av 2 mikrometer breda kopparkopplingar med så lite som 4 mikrometers mellanrum. Det är jämförbart med den översta nivån av sammankopplingar på ett chip. På de ställen där GPU:erna är tänkta att anslutas , kiselskivan är mönstrad med korta kopparpelare placerade med cirka 5 mikrometers mellanrum. GPU:n är justerad ovanför dessa, nedtryckt, och uppvärmd. Denna väletablerade process, kallas termisk kompressionsbindning, gör att kopparpelarna smälter ihop med GPU:ns kopparanslutningar. "
Deras arbete fick positiva kommentarer. Tyson kallade det ett modigt men möjligen lägligt drag för branschen.
Vad kommer härnäst? Teamet kommer att presentera sina resultat vid IEEE International Symposium on High-Performance Computer Architecture. Evenemanget är från 16 till 20 februari i Washington DC.
© 2019 Science X Network