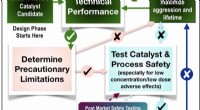
Sida från en fransk version av "Narrenschiff" (Dårarnas skepp). Sådana gamla typsnitt kan på ett tillförlitligt sätt omvandlas till datorläsbar text med OCR4all. Kredit:Dresdens stats- och universitetsbibliotek, CC BY-SA 4.0
Historiker och andra humanistiska forskare har ofta att göra med svåra forskningsobjekt:månghundraåriga tryckta verk som är svåra att tyda och ofta i ett otillfredsställande bevarandetillstånd. Många av dessa dokument har nu digitaliserats – vanligtvis fotograferade eller skannade – och finns tillgängliga online över hela världen. För forskningsändamål, detta är redan ett steg framåt.
Dock, Det finns fortfarande en utmaning att övervinna:att föra de digitaliserade gamla typsnitten till en modern form med textigenkänningsprogram som är läsbar för icke-specialister såväl som för datorer. Forskare vid Centrum för filologi och digitalitet vid Julius-Maximilians-Universität Würzburg (JMU) i Bayern, Tyskland, har gjort ett betydande bidrag till den fortsatta utvecklingen inom detta område.
Med OCR4all, forskargruppen från JMU gör ett nytt verktyg tillgängligt för forskarvärlden. Den omvandlar digitaliserade historiska utskrifter med en felfrekvens på mindre än en procent till datorläsbara texter. Och det erbjuder ett grafiskt användargränssnitt som inte kräver någon IT-expertis. Med tidigare verktyg av detta slag, användarvänlighet var inte alltid självklart, eftersom användarna mestadels fick arbeta med programmeringskommandon.
Utvecklad i samarbete med humaniora
Det nya OCR4all-verktyget utvecklades under ledning av Christian Reul tillsammans med sina datavetenskapskollegor professor Frank Puppe (ordförande för artificiell intelligens och tillämpad datavetenskap) och Christoph Wick samt Uwe Springmann (expert på digital humaniora) och ett flertal studenter och assistenter.
OCR4all kommer från JMU Kallimachos-projektet, som finansieras av det tyska förbundsministeriet för utbildning och forskning. Detta samarbete mellan humaniora och datavetenskap kommer att fortsätta och institutionaliseras i det nygrundade JMU Centrum för filologi och digitalitet.
Vid utvecklingen av OCR4all, datavetare har samarbetat med humaniora vid JMU – inklusive tyska och romanska studier och litteraturstudier i projektet "Narragonien digital". Syftet var att digitalisera "Narrenschiff, "en moralisk satir av Sebastian Brant, en storsäljare från 1400-talet som översattes till många språk. Vidare, OCR4all har använts ofta i JMU:s Kolleg "Medieval and Early Modern Times."
OCR4all är fritt tillgängligt för allmänheten på GitHub-plattformen (med instruktioner och exempel):https://github.com/OCR4all
Varje tryckeri hade sitt eget typsnitt
Christian Reul förklarar utmaningarna i utvecklingen av OCR4all:Automatisk textigenkänning (OCR =Optical Character Recognition) har fungerat mycket bra för moderna typsnitt sedan en tid tillbaka. Dock, detta har ännu inte varit fallet för historiska typsnitt.
"Ett av de största problemen var typografi, " säger Reul. En av anledningarna till detta är att de första tryckerierna på 1400-talet inte använde enhetliga typsnitt. "Deras tryckstämplar var alla snidade av dem själva, varje tryckeri hade praktiskt taget sina egna bokstäver."
Felfrekvenser under en procent
Oavsett om "e" eller "c, "om "v" eller "r" - det är ofta inte lätt att särskilja i gamla tryck, men programvara kan lära sig att känna igen sådana finesser. Att göra så, den måste tränas på provmaterial. I sitt arbete, Reul har utvecklat metoder för att effektivisera träningen. I en fallstudie med sex historiska tryck från åren 1476 till 1572, den genomsnittliga felfrekvensen vid automatisk textigenkänning minskade från 3,9 till 1,7 procent.
Metodiken förbättrades inte bara, JMU-datavetaren Christoph Wick har också på ett avgörande sätt ytterligare förfinat den tekniska komponenten genom att utveckla verktyget Calamari OCR, som också är fritt tillgänglig och har sedan dess integrerats helt i OCR4all, lovar ännu bättre resultat. Nu, även för de äldsta tryckta verken, felfrekvenser på mindre än en procent kan generellt uppnås.
Lexikala projekt
Reul har också övertygat externa partners om kvaliteten på Würzburgs OCR-forskning. I samarbete med "Zentrum für digitale Lexikographie der deutschen Sprache" (Berlin), Daniel Sanders "Wörterbuch der deutschen Sprache" (Dictionary of the German Language) har indexerats digitalt, och en vetenskaplig publikation om detta arbete håller för närvarande på att utarbetas. De olika raderna i denna text innehåller ofta olika typsnitt, representerar olika semantisk information. Här, det befintliga förhållningssättet till teckenigenkänning utökades på ett sådant sätt att inte bara texten utan också typografin och därmed lexikonets komplexa innehållsstruktur kan återges mycket exakt.
Datavetaren från Würzburg kommer snart att slutföra sin doktorsavhandling, men han är också villig att fortsätta arbeta med OCR i framtiden:"Datavetenskapen bakom OCR är extremt spännande, " säger han. Ett möjligt projekt inom en snar framtid:skaparna av "Idiotikon, "en ordbok över det schweizisk-tyska språket, har visat sitt intresse för samarbete eftersom de mycket väl kan behöva Würzburgs specialistkunskaper.