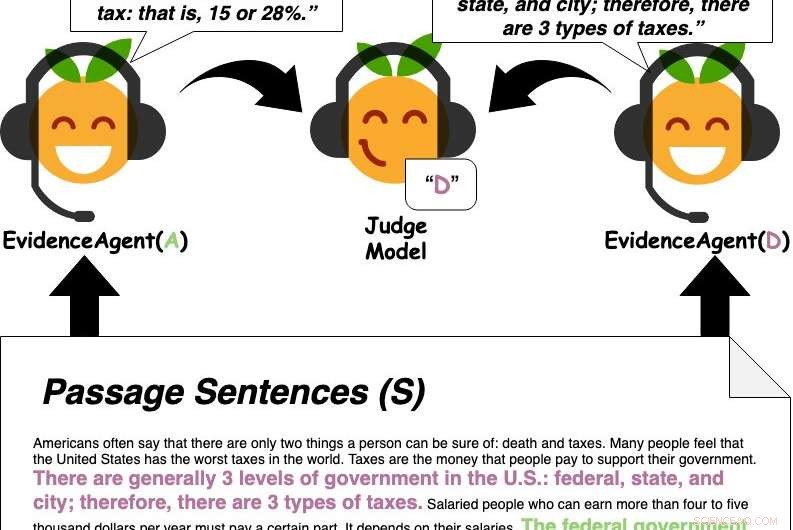
Bevisagenter citerar meningar från avsnittet för att övertyga en frågesvarande domaremodell om ett svar. Kredit:Perez et al.
Att identifiera det korrekta svaret på en fråga innebär ofta att man samlar in stora mängder information och förstår komplexa idéer. I en nyligen genomförd studie, ett team av forskare vid New York University (NYU) och Facebook AI Research (FAIR) undersökte möjligheten att automatiskt avslöja de underliggande egenskaperna hos problem som frågesvar genom att undersöka hur maskininlärningsmodeller lär sig att lösa relaterade uppgifter.
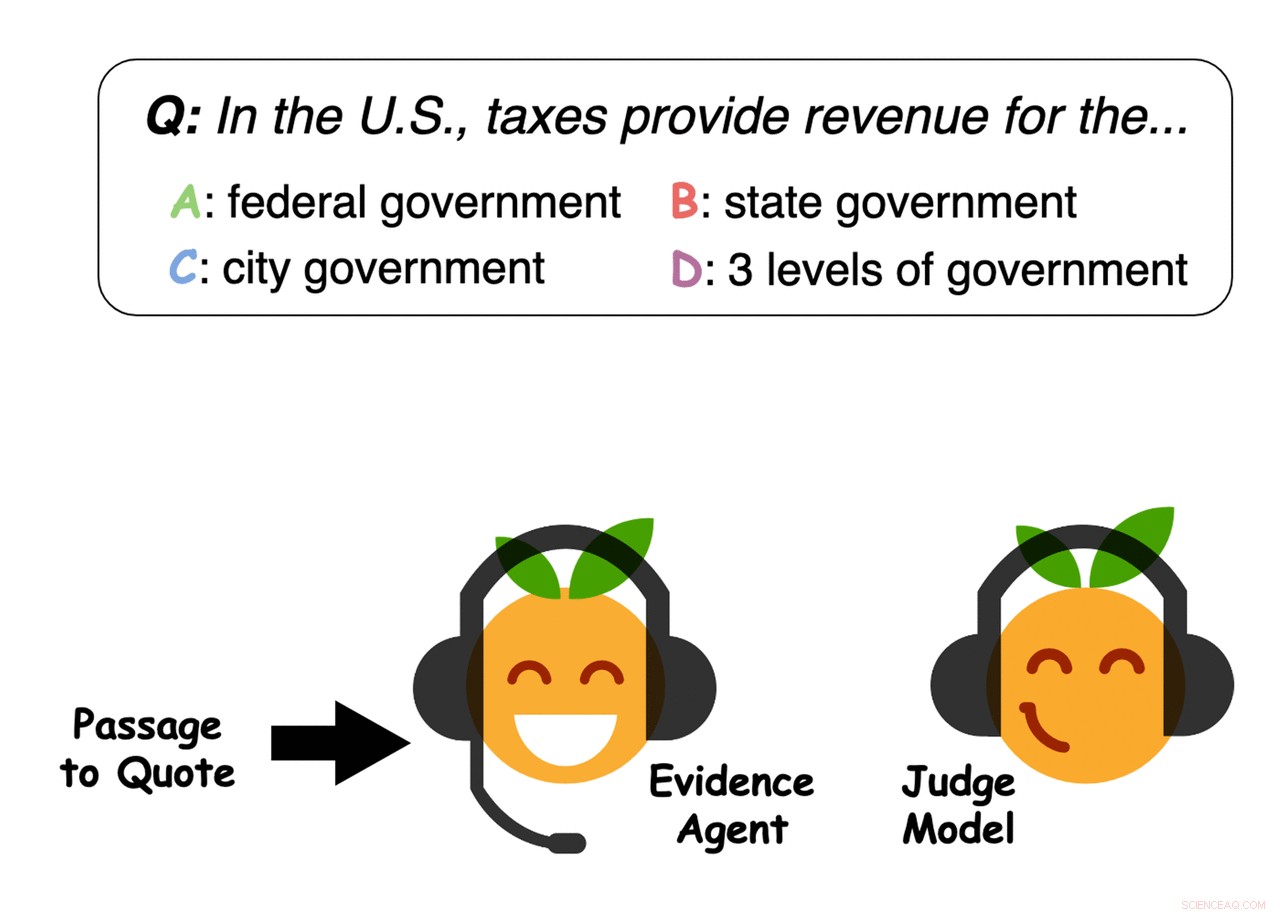
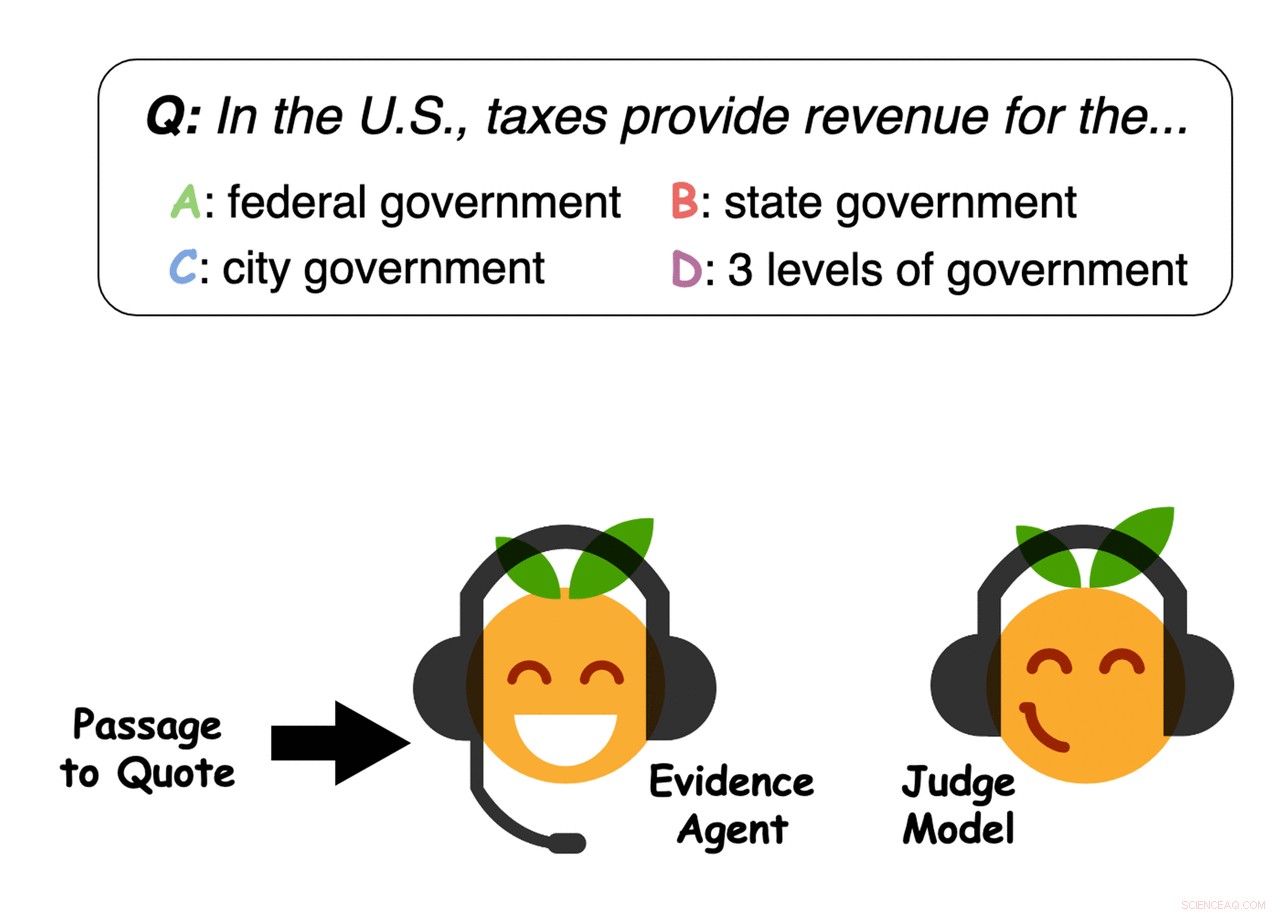
I deras tidning, förpublicerad på arXiv och kommer att presenteras på EMNLP 2019, de introducerade ett tillvägagångssätt för att samla de starkaste stödjande bevisen för ett givet svar på en fråga. De tillämpade specifikt denna metod på uppgifter som involverar passage-baserat frågesvar (QA), vilket innebär att man analyserar stora mängder text för att identifiera det bästa svaret på en given fråga.
"När vi ställer en fråga, vi är ofta inte bara intresserade av svaret, men också varför det svaret är korrekt – vilka bevis stöder det svaret, "Ethan Perez, en av forskarna som genomförde studien, berättade för TechXplore. "Tyvärr, att hitta bevis kan vara tidskrävande om det kräver läsning av många artiklar, forskningspapper, etc. Vårt mål var att utnyttja maskininlärning för att hitta bevis automatiskt."
Först, Perez och hans kollegor tränade en QA-maskininlärningsmodell utformad för att svara på användarfrågor på en stor databas med text som inkluderade nyhetsartiklar, biografier, böcker och annat onlineinnehåll. Senare, de använde "evidensagenter" för att identifiera meningar som skulle "övertyga" maskininlärningsmodellen att svara på en viss fråga med ett specifikt svar, i huvudsak samla bevis för svaret.

Kredit:Perez et al.
"Vårt system kan hitta bevis för vilket svar som helst - inte bara svaret som Q&A-modellen tror är korrekt, som tidigare arbete fokuserat på, sade Perez. Alltså, vårt tillvägagångssätt kan utnyttja en fråge- och svarsmodell för att hitta användbara bevis, även om Q&A-modellen förutsäger fel svar eller om det inte finns ett tydligt rätt svar."
I sina tester, Perez och hans kollegor observerade att maskininlärningsmodeller vanligtvis väljer bevis från textavsnitt som generaliserar väl för att övertyga andra modeller och till och med människor. Med andra ord, deras resultat tyder på att modeller gör bedömningar baserade på liknande bevis som de som vanligtvis anses av människor, och till viss del, det är till och med möjligt att undersöka hur människor tänker genom att svaja hur modeller beaktar bevis.
Forskarna fann också att mer exakta QA-modeller tenderar att hitta bättre stödjande bevis, åtminstone enligt en grupp mänskliga deltagare som de intervjuade. Maskininlärningsmodellers prestanda och kapacitet kan därför starkt förknippas med deras effektivitet när det gäller att samla bevis för att backa upp sina förutsägelser.

Exempel på bevis utvalda av agenterna. Kredit:Perez et al.
Kredit:Perez et al.

Exempel på bevis utvalda av agenterna. Kredit:Perez et al.
Bevisagenter citerar meningar från avsnittet för att övertyga en frågesvarande domaremodell om ett svar. Kredit:Perez et al.
"Från en praktisk synvinkel, att hitta bevis är användbart, ", sa Perez. "Människor kan svara på frågor om långa artiklar bara genom att läsa vårt systems bevis för varje möjligt svar. Därför, i allmänhet, genom att hitta bevis automatiskt, ett system som vårt kan potentiellt hjälpa människor att utveckla välgrundade åsikter snabbare."
Perez och hans kollegor fann att deras tillvägagångssätt för att samla bevis förbättrade frågesvar avsevärt, tillåta människor att svara korrekt på frågor baserat på cirka 20 procent av ett textstycke, som valdes ut av en maskininlärningsagent. Dessutom, deras tillvägagångssätt gjorde det möjligt för QA-modeller att identifiera svar på frågor mer effektivt, generalisera bättre till längre passager och svårare frågor.
I framtiden, det tillvägagångssätt som detta team av forskare utarbetat och de observationer de samlat in skulle kunna ge information om utvecklingen av effektivare och tillförlitligare maskininlärningsverktyg för QA. På senare tid, Perez skrev också ett blogginlägg på Medium som förklarar idéerna som presenteras i tidningen mer djupgående.
"Att hitta bevis är ett första steg mot modeller som debatterar, " sa Perez. "Jämfört med att hitta bevis, debatt är ett ännu mer uttrycksfullt sätt att stödja ett ställningstagande. Att debattera kräver inte bara att man citerar externa bevis utan också att man bygger upp sina egna argument – genererar ny text. Jag är intresserad av att träna modeller för att generera nya argument, samtidigt som man säkerställer att den genererade texten är sann och faktiskt korrekt."
© 2019 Science X Network














