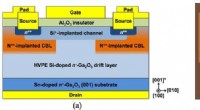
* Till exempel kan vi använda ett binärt kodningsschema där varje informationsbit representeras av två nukleotider (A, T, C, G).
Steg 2:Syntetisera DNA-sekvenserna som innehåller den kodade informationen.
* Detta kan göras med hjälp av automatiserade DNA-syntesmaskiner, som liknar de som används för att skapa DNA-mikroarrayer och genuttrycksanalyser.
Steg 3:Rena och verifiera de syntetiska DNA-sekvenserna.
* Detta är nödvändigt för att säkerställa att sekvenserna är fria från fel och att informationsinnehållet bevaras.
Steg 4:Förvara de syntetiska DNA-sekvenserna i en säker och säker miljö.
* Detta kan inkludera lagring av DNA-sekvenser på flera platser, till exempel i djupfrysanläggningar och/eller i underjordiska valv.
Steg 5:Övervaka och underhålla de lagrade DNA-sekvenserna regelbundet.
* Detta är nödvändigt för att säkerställa att sekvenserna inte försämras över tid och att de förblir tillgängliga för framtida generationer.
Steg 6:Utveckla metoder för att avkoda och hämta informationen från DNA-sekvenserna i framtiden.
* Detta kan innebära utveckling av nya DNA-sekvenserings- och analystekniker.
Utmaningar och överväganden:
* Kostnaden för DNA-syntes och lagring kan vara hög, vilket kan begränsa mängden information som kan bevaras.
* DNA är känsligt för nedbrytning över tid, så det är viktigt att ha lämpliga lagringsförhållanden och redundans för att säkerställa att informationen bevaras på lång sikt.
* Det finns risk för att fel uppstår under kodnings-, syntes- och avkodningsprocesserna, så det är viktigt att ha robusta felkorrigeringsmekanismer på plats.
* Etiska och juridiska överväganden bör också beaktas, till exempel vem som har rätt att få tillgång till den bevarade informationen och hur den kan användas.