Kvantoptik och statistik. Kredit:University of Freiburg
Kvantdatorer kan en dag lösa algoritmiska problem som inte ens de största superdatorer idag kan hantera. Men hur testar du en kvantdator för att säkerställa att den fungerar pålitligt? Beroende på den algoritmiska uppgiften, detta kan vara ett enkelt eller ett mycket svårt certifieringsproblem. Ett internationellt team av forskare har tagit ett viktigt steg mot att lösa en svår variation av detta problem, med hjälp av ett statistiskt tillvägagångssätt utvecklat vid universitetet i Freiburg. Resultaten av deras studie publiceras i den senaste upplagan av Nature Photonics .
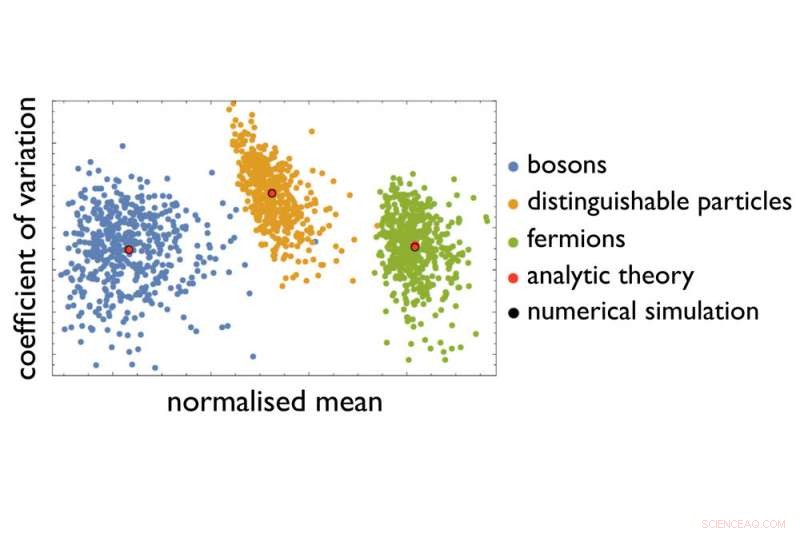
Deras exempel på ett svårt certifieringsproblem är att sortera ett definierat antal fotoner efter att de har gått igenom ett definierat arrangemang av flera optiska element. Arrangemanget ger varje foton ett antal överföringsvägar - beroende på om fotonen reflekteras eller sänds av ett optiskt element. Uppgiften är att förutsäga sannolikheten för att fotoner lämnar arrangemanget vid definierade punkter, för en given positionering av fotonerna vid ingången till arrangemanget. Med ökande storlek på det optiska arrangemanget och ökande antal fotoner som skickas på väg, antalet möjliga vägar och fördelningar av fotonerna i slutet stiger kraftigt till följd av osäkerhetsprincipen som ligger till grund för kvantmekaniken - så att det inte kan finnas någon förutsägelse av den exakta sannolikheten med hjälp av de datorer som är tillgängliga för oss idag. Fysiska principer säger att olika typer av partiklar - såsom fotoner eller elektroner - bör ge olika sannolikhetsfördelningar. Men hur kan forskare skilja på dessa fördelningar och olika optiska arrangemang när det inte finns något sätt att göra exakta beräkningar?
Ett tillvägagångssätt som utvecklats i den aktuella studien gör det nu möjligt för första gången att identifiera karakteristiska statistiska signaturer över omätbara sannolikhetsfördelningar. Istället för ett komplett "fingeravtryck, "de kunde destillera informationen från datamängder som reducerades för att göra dem användbara. Med hjälp av den informationen, de kunde särskilja olika partikeltyper och särdrag hos optiska arrangemang. Teamet visade också att denna destillationsprocess kan förbättras, bygger på etablerade tekniker för maskininlärning, varigenom fysiken ger den viktigaste informationen om vilken datamängd som ska användas för att söka efter relevanta mönster. Och eftersom denna metod blir mer exakt för större antal partiklar, forskarna hoppas att deras resultat tar oss ett viktigt steg närmare att lösa certifieringsproblemet.