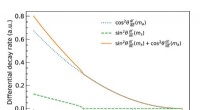
Dessa är detektorpixlarna för elektroner och kvarkstrålar som produceras av en simulerad protonkollision, mätt av ATLAS-detektorn. Kredit:Taylor Childers
Medan högenergifysik och kosmologi verkar vara världar åtskilda i termer av ren skala, fysiker och kosmologer vid Argonne använder liknande maskininlärningsmetoder för att ta itu med klassificeringsproblem för både subatomära partiklar och galaxer.
Högenergifysik och kosmologi tycks vara världar åtskilda i termer av ren skala, men de osynliga komponenterna som utgör fältet för den ena informerar om sammansättningen och dynamiken hos den andra - kollapsande stjärnor, stjärnfödande nebulosor och, kanske, mörk materia.
I årtionden, de tekniker med vilka forskare inom båda områdena studerade sina domäner verkade nästan oförenliga, också. Högenergifysik förlitade sig på acceleratorer och detektorer för att få lite insikt från partiklarnas energetiska interaktioner, medan kosmologer tittade genom alla möjliga teleskop för att avslöja universums hemligheter.
Även om ingen av dem har gett upp den grundläggande utrustningen inom sitt område, fysiker och kosmologer vid det amerikanska energidepartementets (DOE) Argonne National Laboratory attackerar komplexa flerskaliga problem med hjälp av olika former av en artificiell intelligensteknik som kallas maskininlärning.
Används redan inom många områden, maskininlärning kan hjälpa till att identifiera dolda mönster genom att lära sig av indata och successivt förbättra förutsägelser om ny data. Det kan tillämpas på visuella klassificeringsuppgifter eller i snabb reproduktion av komplicerade och beräkningsmässigt dyra beräkningar.
Med potential att radikalt förändra hur vetenskap bedrivs, Dessa AI-tekniker kommer att hjälpa oss att få en bättre förståelse av fördelningen av galaxer i universum eller bättre visualisera bildandet av nya partiklar som vi kan dra slutsatser av ny fysik från.
"Under decennierna, vi har utvecklat traditionella algoritmer som rekonstruerar signaturerna för de olika partiklarna som vi är intresserade av, sa Taylor Childers, en partikelfysiker och en datavetare med Argonne Leadership Computing Facility (ALCF), en DOE Office of Science User Facility.
"Det har tagit väldigt lång tid att utveckla dem och de är väldigt exakta, " tillade han. "Men samtidigt, det skulle vara intressant att veta om bildklassificeringstekniker från maskininlärning som har använts framgångsrikt av Google och Facebook kan förenkla eller förkorta utvecklingen av algoritmer som identifierar partikelsignaturer i våra 3-D-detektorer."
Childers arbetar med Argonne högenergifysiker, som alla är medlemmar i ATLAS experimentella samarbete vid CERNs Large Hadron Collider (LHC), den största och mest kraftfulla partikelkollideraren i världen. Funderar på att lösa ett brett spektrum av fysikproblem, ATLAS-detektorn är åtta våningar hög och 150 fot lång vid en punkt runt LHC:s kolliderring på 17 mils omkrets, där den mäter produkterna från protoner som kolliderar med hastigheter nära ljusets hastighet.
Enligt ATLAS webbplats, "över en miljard partikelinteraktioner äger rum i ATLAS-detektorn varje sekund, en datahastighet som motsvarar 20 samtidiga telefonsamtal som hålls av varje människa på jorden."
Även om bara en liten procent av dessa kollisioner anses värda att studera - ungefär en miljon per sekund - ger det fortfarande ett berg av data för forskare att undersöka.
Dessa höghastighetspartikelkollisioner skapar nya partiklar i deras kölvatten, som elektroner eller kvarkskurar, var och en lämnar en unik signatur i detektorn. Det är dessa signaturer som Childers skulle vilja identifiera genom maskininlärning.
En av utmaningarna är att fånga dessa energisignaturer som bilder i ett komplext 3D-rum. Ett foto, till exempel, är i huvudsak en 2D-representation av 3D-data med vertikala och horisontella positioner. Pixeldata, färgerna i bilden, är spatialt orienterade och har rumslig information kodad i sig – till exempel, ögonen på en katt är bredvid näsan, och öronen är ovanför till vänster och höger.
"Så deras rumsliga orientering är viktig. Detsamma gäller bilderna som vi tar vid LHC. När en partikel passerar vår detektor, det lämnar en energisignatur i rumsliga mönster som är specifika för de olika partiklarna, " förklarade Childers.
Lägg till det mängden data som kodas i inte bara signaturerna, men 3D-utrymmet runt dem. Där traditionella maskininlärningsexempel för bildigenkänning—de där katterna, återigen – hantera hundratusentals pixlar, ATLAS bilder innehåller hundratals miljoner detektorpixlar.
Så idén, han sa, är att behandla detektorbilderna som traditionella bilder. Genom att använda en maskininlärningsteknik som kallas konvolutionella neurala nätverk – som lär sig hur data är rumsligt relaterad – kan de extrahera 3D-utrymmet för att lättare identifiera specifika partikelegenskaper.

Bilden visar en Einstein-ring (mitten till höger) bildad av gravitationslinser av en stjärnbildande galax (blå) av en massiv lysande röd galax (orange). Detta system upptäcktes först av Sloan Digital Sky Survey 2007; bilderna är från rymdteleskopet Hubble. Kredit:NASA
Childers hoppas att dessa maskininlärningsalgoritmer så småningom kommer att ersätta de traditionella handgjorda algoritmerna, vilket avsevärt minskar tiden det tar att bearbeta liknande mängder data samt förbättrar precisionen i de uppmätta resultaten.
"Vi kan också ersätta den decennielånga utvecklingen som behövs för nya detektorer och minska den med nya träningsmodeller för framtida detektorer, " han sa.
Ett större utrymme
Argonne-kosmologer använder liknande maskininlärningsmetoder för att ta itu med klassificeringsproblem, men i mycket större skala.
"Problemet med kosmologi är att objekten vi tittar på är komplicerade och luddiga, sa Salman Habib, Divisionsdirektör för Argonnes Computational Science-avdelning och tillfällig biträdande direktör för dess High Energy Physics-division. "Så att beskriva data på ett enklare sätt blir väldigt svårt."
Han och hans kollegor använder superdatorer vid Argonne och andra nationella DOE-laboratorier för att rekonstruera universums detaljer, galax för galax. De skapar mycket detaljerade simulerade galaxkataloger som kan användas för jämförelse med verkliga data tagna från undersökningsteleskop, som Large Synoptic Survey Telescope, ett partnerskap mellan DOE och National Science Foundation.
Men för att göra dessa tillgångar värdefulla för forskare, de måste vara så nära verkligheten som möjligt.
Maskininlärningsalgoritmer, Habib sa, är mycket bra på att välja ut egenskaper som lätt kan karakteriseras av geometri - som de där katterna. Än, liknande varningen på fordonsspeglar, objekt i himlen är inte alltid som de ser ut.
Ta fenomenet stark gravitationslinsning; förvrängningen av en bakgrundsljuskälla – en galax eller en galaxhop – av en mellanliggande massa. Avböjningen av ljusstrålars banor från källan på grund av gravitationen leder till en förvrängning av bakgrundskällans form, position och orientering; denna distorsion ger information om massfördelningen av det mellanliggande objektet. Den faktiska observationssituationen är inte så enkel, dock.
En helt rund blob som är linsad, till exempel, kan verka utsträckt i en eller annan riktning, under en runda, Ett diskformat föremål utan lins kan se elliptiskt ut om det ses delvis på kanten.
"Så hur vet du om föremålet du tittar på inte är ett runt föremål som har roterats, eller en som har objektivats?" frågade Habib. "Det här är sådana knepiga saker som maskininlärning måste kunna lista ut."
Att göra detta, forskare skapar ett träningsprov av miljontals realistiska objekt, varav hälften är linsade. Maskininlärningsalgoritmerna går sedan igång med att försöka lära sig skillnaderna mellan de linsade och olinsade objekten. Resultaten verifieras mot en känd uppsättning syntetiska linser och objekt utan lins.
Men resultaten berättar bara halva historien – hur väl algoritmerna fungerar på testdata. För att ytterligare förbättra deras noggrannhet för riktiga data, forskare blandar en viss procentandel av syntetisk data med tidigare observerade data och kör algoritmerna, på nytt, jämföra hur väl de valde linsobjekt i träningsprovet kontra kombinationsdata.
"I slutet, du kanske upptäcker att det fungerar ganska bra, men kanske inte så bra som du vill, " förklarade Habib. "Du kanske säger 'OK, denna information i sig kommer inte att vara tillräcklig, Jag måste samla in mer.' Det är en ganska lång och komplex process."
Två primära mål för modern kosmologi, han sa, är att förstå varför universums expansion accelererar och vad den mörka materiens natur är. Mörk materia är ungefär fem gånger så riklig som normal materia, men dess yttersta ursprung förblir mystiskt. För att komma nära ett svar, vetenskapen måste vara mycket medveten, mycket exakt.
"I det nuvarande skedet, Jag tror inte att vi kan lösa alla våra problem med maskininlärningsapplikationer, " medgav Habib. "Men jag skulle säga att maskininlärning kommer att vara mycket viktig för alla aspekter av precisionskosmologi inom en snar framtid."
När maskininlärningstekniker utvecklas och förfinas, deras användbarhet för både högenergifysik och kosmologi kommer säkerligen att växa exponentiellt, ger hoppet om nya upptäckter eller nya tolkningar som förändrar vår förståelse av världen på flera skalor.