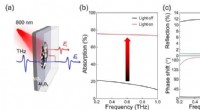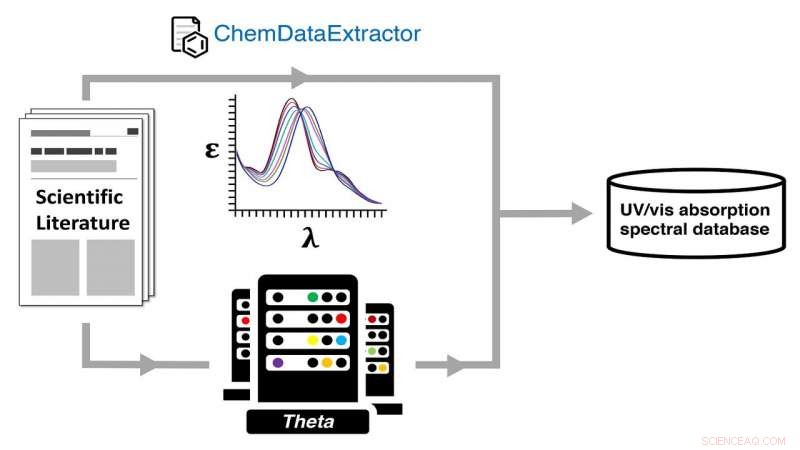
Automatisk generering av en ultraviolett synlig (UV-vis) absorptionsspektraldatabas via en dubbel experimentell och beräknad kemisk dataväg med hjälp av ALCF:s Theta-superdator. Upphovsman:Jacqueline Cole och Ulrich Mayer / University of Cambridge
Ett samarbete mellan University of Cambridge och Argonne har utvecklat en teknik som genererar automatiska databaser för att stödja specifika vetenskapsområden med hjälp av AI och högpresterande datorer.
Att leta igenom bitar av vetenskaplig litteratur efter bitar och byte av information för att stödja en idé eller hitta nyckeln till att lösa ett specifikt problem har länge varit en tråkig affär för forskare, även efter gryningen av datadriven upptäckt.
Jacqueline Cole känner till övningen, alltför väl. Chef för molekylär teknik vid University of Cambridge, Storbritannien, hon har tillbringat mycket av sin karriär med att leta efter material med optiska egenskaper som lämpar sig för effektivare ljusinsamling, som färgmolekyler som en dag kan driva solfönster.
"Jag visste att mycket information fanns i mycket fragmenterad form i litteraturen, "minns hon." Men om du samlade på tusentals och tusentals dokument, då kan du bilda din egen databas. "
Så Cole och kollegor vid Cambridge och US Department of Energy's (DOE) Argonne National Laboratory gjorde just det, redogör för processen i journalen Vetenskapliga data .
Pappret, säger Cole, är en beskrivning av hur man bygger en databas med hjälp av naturligt språkbehandling (NLP) och högpresterande datorer, mycket av det senare utfördes vid Argonne Leadership Computing Facility (ALCF), en DOE Office of Science User Facility.
Bland de faktorer som gör databasen unik är projektets skala och det faktum att den omfattar både experimentella och beräknade data om båda materialstrukturer, som beskriver en atomens eller kemiska grund, och materialegenskaper, funktionaliteten från de olika strukturerna.
"Det är förmodligen den första sammanställningen av en databas i så stor skala, med 5, 380 liknande-för-liknande par experimentella och beräknade data, "säger Cole." Och eftersom det är en så stor mängd, det fungerar som ett förråd i sig och öppnar verkligen dörren för att förutsäga nya material. "
Många nya, stora databaser är enbart byggda på beräkningar, en inneboende nackdel är att de inte valideras av experimentella data. Den senare, kanske viktigast, ger en exakt bild av materialets upphetsade tillstånd, som definierar elektronernas dynamiska tillstånd och används för att beräkna ett materials funktionella egenskaper - optiska egenskaper, I detta fall.
Denna spirande katalog över upphetsade tillstånd kan sedan hjälpa till att beräkna egenskaperna hos material som ännu inte är tänkta, ytterligare utbyggnad av databasen.
"Tänk dig att man vill upptäcka en ny typ av optiskt material som passar en skräddarsydd funktionell applikation, och vår databas inte innehåller den specifika optiska egenskapen, "förklarar Cole." Vi beräknar den optiska egenskapen av intresse från de upphetsade tillstånd som är tillgängliga för varje fastighet i vår databas, och skapa ett material med skräddarsydda funktioner. "
Teamet utförde kvantkemiska beräkningar på varje struktur för vilken de hade extraherat data om optiska material, med hjälp av ALCF:s Theta -superdator, sålunda skapas databasen över parade experimentella och beräknade strukturer och deras optiska egenskaper.
"En av de största utmaningarna var att utvinna kemiska kandidater som kan fungera som färgämnen för solceller från 400, 000 vetenskapliga artiklar, "säger Álvaro Vázquez-Mayagoitia, en beräkningsvetare i Argonnes division Computational Science. "Vi utvecklade ett distribuerat ramverk för att tillämpa metoder för artificiell intelligens, som de som används vid bearbetning av naturligt språk, på ALCF:s superdatorer i världsklass. "
För att automatiskt extrahera den informationen och sätta in den i databasen, laget vände sig till den nya data mining -applikationen som heter ChemDataExtractor. Ett NLP -verktyg, den var utformad för att utvinna text specifikt från kemi och materiallitteratur, var, Cole säger, "informationen ströms ut i många tusentals papper och finns i mycket fragmenterade och ostrukturerade former."
Inte en för manuella artikelsökningar, Cole beskriver drivkraften att utveckla applikationen som innovation från frustration. Initialt, hon försökte mer generiska NLP -paket, men noterade att "de misslyckas inte bara, de misslyckas spektakulärt. "
Problemet ligger i översättningen, inte så mycket från ett mänskligt språk, men från vetenskapens språk, även om det finns vissa likheter.
En författare, till exempel, kan använda ett taligenkänningsprogram, en form av NLP, för att transkribera anteckningar eller intervjuer. Programmet tränar främst på författarens röst, plocka upp mönster och nyanser, och börjar transkribera ganska exakt. Släng nu in en intervju med ett ämne med utländsk accent och det börjar bli knasigt.
I Coles värld, främmande språk är vetenskap, varje domän ett annat land. För närvarande, du måste träna programmet på bara ett "språk, "säg kemi, och även då, du måste lära dig vetenskapens särskilda dialekter.
Oorganiska kemister kan utgöra en formel med okända representationer av de välkända kemiska grundsymbolerna, medan organiska kemister föredrar kemiska skisser numrerade i en illustrationsruta. Informationen från antingen visar sig vanligtvis vara för svår för de flesta gruvprogram att extrahera.
"Och det är bara i lite kemi, "konstaterar Cole." Eftersom hur människor beskriver saker är så olika, mångfald i domänspecificitet är helt avgörande. "
För detta ändamål, lagets databas är en av ultraviolett -synliga (UV/vis) absorptionsspektrala attribut, som ger en öppet tillgänglig resurs för användare som vill hitta material med föredragna spektrala färger.
Medan teamet använder den nya databasen för att iller ut organiska färgämnen som kan ersätta traditionella metall-organiska färgämnen i solceller, de har redan riktat sig mot bredare fronter för dess användning.
Användbar som källa för utbildningsdata för maskininlärningsmetoder som förutsäger nya optiska material, det kan också bevisa ett enkelt datahämtningsalternativ för användare av UV/vis absorptionsspektroskopi, ett verktyg som ofta används i forskningslaboratorier runt om i världen som en kärnteknik för att karakterisera nya material.
"Protokollen som används i detta projekt används redan för liknande typer av projekt, "lägger till Vázquez-Mayagoitia." Till exempel, laget utnyttjade nyligen ChemDataExtractor och ALCF -datorresurser för att producera expansiva databaser över potentiella batterikemikalier, och magnetiska och supraledande föreningar. "
Den optiska materialdatabasforskningen visas i artikeln "Jämförande dataset för experimentella och beräkningsattribut för UV/vis absorptionsspektra" i vetenskapliga data. Ytterligare författare inkluderar Edward J. Beard vid University of Cambridge, och Ganesh Sivaraman och Venkatram Vishwanath från Argonne National Laboratory.
Ett papper som beskriver deras arbete med magnetiska och supraledande material har publicerats i npj Beräkningsmaterial . Batterimaterialdatabasen som innehåller över 290, 000 dataposter har publicerats i Vetenskapliga data .