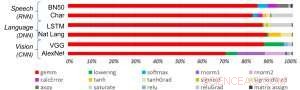
Figur 1. Algoritmer för djupinlärning består av ett spektrum av operationer. Även om matrismultiplikation är dominant, För att optimera prestandaeffektiviteten samtidigt som noggrannheten bibehålls krävs kärnarkitekturen för att effektivt stödja alla hjälpfunktioner. Kredit:IBM
De senaste framstegen inom djupinlärning och exponentiell tillväxt i användningen av maskininlärning över applikationsdomäner har gjort AI-acceleration av avgörande betydelse. IBM Research har byggt en pipeline av AI-hårdvaruacceleratorer för att möta detta behov. Vid 2018 VLSI Circuits Symposium, vi presenterade en kärnbyggsten för multi-TeraOPS accelerator som kan skalas över ett brett utbud av AI-hårdvarusystem. Denna digitala AI-kärna har en parallell arkitektur som säkerställer mycket hög användning och effektiva beräkningsmotorer som noggrant utnyttjar minskad precision.
Ungefärlig datoranvändning är en central grundsats i vår strategi för att utnyttja "fysiken i AI", där mycket energieffektiva datorvinster uppnås med specialbyggda arkitekturer, initialt med digitala beräkningar och senare inklusive analog och in-memory beräkning.
Historiskt sett, beräkning har förlitat sig på högprecision 64- och 32-bitars flyttalsaritmetik. Detta tillvägagångssätt ger korrekta beräkningar till n:te decimalkomma, en noggrannhetsnivå som är avgörande för vetenskapliga beräkningsuppgifter som att simulera det mänskliga hjärtat eller beräkna rymdfärjans banor. Men behöver vi denna nivå av noggrannhet för vanliga djupinlärningsuppgifter? Kräver vår hjärna en högupplöst bild för att känna igen en familjemedlem, eller en katt? När vi skriver in en texttråd för sökning, kräver vi precision i den relativa rankningen av 50, 002:a mest användbara svaret jämfört med 50, 003:e? Svaret är att många uppgifter inklusive dessa exempel kan utföras med ungefärlig beräkning.
Eftersom full precision sällan krävs för vanliga arbetsbelastningar för djupinlärning, minskad precision är en naturlig riktning. Beräkningsbyggstenar med 16-bitars precisionsmotorer är 4x mindre än jämförbara block med 32-bitars precision; denna vinst i områdeseffektivitet blir en ökning av prestanda och energieffektivitet för både AI-träning och slutledningsarbete. Enkelt uttryckt, i ungefärlig beräkning, vi kan byta numerisk precision för beräkningseffektivitet, förutsatt att vi också utvecklar algoritmiska förbättringar för att behålla modellens noggrannhet. Det här tillvägagångssättet kompletterar också andra ungefärliga beräkningstekniker – inklusive nyare arbeten som beskrev nya träningskompressionsmetoder för att minska kommunikationsoverhead, vilket leder till 40-200 gånger snabbare än befintliga metoder.
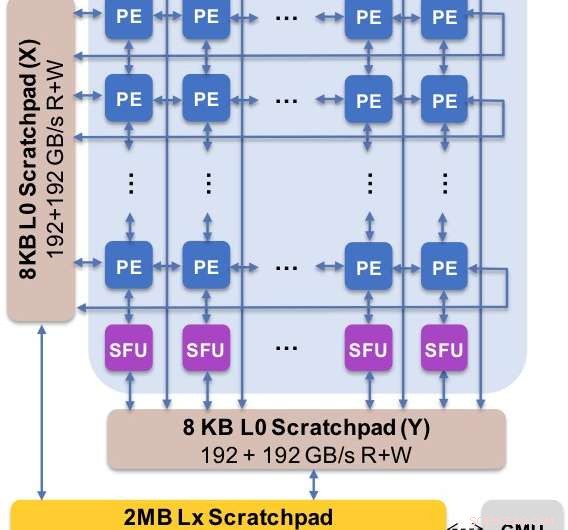
Figur 2. Kärnarkitekturen fångar det anpassade dataflödet med scratchpad-hierarki. Bearbetningselementet (PE) utnyttjar reducerad precision för matrismultiplikationsoperationer och vissa aktiveringsfunktioner medan specialfunktionsenheterna (SFU) behåller 32-bitars flyttalsprecision för de återstående vektoroperationerna. Kredit:IBM
Vi presenterade experimentella resultat av vår digitala AI-kärna vid 2018 års symposium om VLSI-kretsar. Utformningen av vår nya kärna styrdes av fyra mål:
Vår nya arkitektur har optimerats för inte bara matrismultiplikation och faltningskärnor, som tenderar att dominera djupinlärningsberäkningar, men också ett spektrum av aktiveringsfunktioner som är en del av beräkningsarbetet för djupinlärning. Vidare, vår arkitektur erbjuder stöd för inhemska faltningsoperationer, gör att djupinlärningsträning och slutledningsuppgifter på bilder och taldata kan köras med exceptionell effektivitet i grunden.
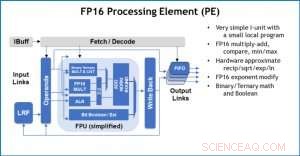
Figur 3. Processing Element (PE) med 16-bitars flyttalsfunktioner (FP16) för matrismultiplikationsoperationer, binär och ternär matematik, aktiveringsfunktioner och booleska operationer. Kredit:IBM
Som en illustration av hur kärnarkitekturen har optimerats för en mängd olika funktioner för djupinlärning, Figur 1 visar uppdelningen av operationstyper inom djupinlärningsalgoritmer över ett spektrum av applikationsdomäner. De dominerande matrismultiplikationskomponenterna beräknas i kärnarkitekturen genom att använda en anpassad dataflödesorganisation av bearbetningselementen som visas i figurerna 2 och 3 där beräkningar med reducerad precision kan utnyttjas effektivt, medan de återstående vektorfunktionerna (alla icke-röda staplar i figur 1) exekveras i antingen bearbetningselementen eller specialfunktionsenheterna som visas i figur 3 eller 4, beroende på precisionsbehoven för den specifika funktionen.
På symposiet, vi visade hårdvaruresultat som bekräftar att denna metod med en enda arkitektur är kapabel till både träning och slutledning och stöder modeller inom flera domäner (t.ex. Tal, syn, naturlig språkbehandling). Medan andra grupper pekar på "toppprestanda" för sina specialiserade AI-chips, men har bibehållna prestationsnivåer vid en liten bråkdel av topp, vi har fokuserat på att maximera hållbar prestanda och utnyttjande, eftersom ihållande prestanda direkt översätts till användarupplevelse och svarstider.
Vårt testchip visas i figur 5. Med detta testchip, inbyggd 14LPP-teknik, vi har framgångsrikt visat både träning och slutledning, över ett brett bibliotek för djupinlärning, utöva alla operationer som vanligtvis används i djupinlärningsuppgifter, inklusive matrismultiplikationer, faltningar och olika icke-linjära aktiveringsfunktioner.
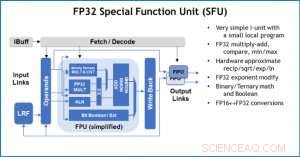
Figur 4. Specialfunktionsenhet (SFU) med 32-bitars flyttal (FP32) för vissa vektorberäkningar. Kredit:IBM
Vi lyfte fram flexibiliteten och multifunktionaliteten hos den digitala AI-kärnan och inbyggt stöd för flera dataflöden i VLSI-papperet, men detta tillvägagångssätt är helt modulärt. Denna AI-kärna kan integreras i SoCs, CPU:er, eller mikrokontroller och används för träning, slutledning, eller båda. Chips som använder kärnan kan distribueras i datacentret eller vid kanten.
Drivs av en grundläggande förståelse för algoritmer för djupinlärning vid IBM Research, vi förväntar oss att precisionskraven för utbildning och slutsatser kommer att fortsätta att skalas – vilket kommer att driva fram kvanteffektivitetsförbättringar i hårdvaruarkitekturer som behövs för AI. Stay tuned for more research from our team.
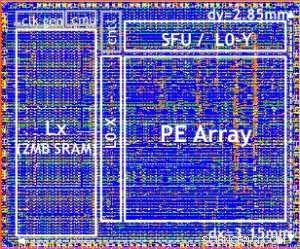
Figure 5. Digital AI Core testchip, based on 14LPP technology, including 5.75M gates, 1.00 flip-flops, 16KB L0 and 16KB of PE local registers. This chip was used to demonstrate both training and inferencing, across a wide range of AI workloads. Credit:IBM