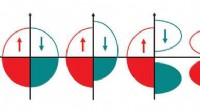
Jämförelse av konceptrankningar för en rapport från Human Rights Watch. Kolumnen "Ground truth" visar de åtta vanligaste personerna i rapporten "Venezuelas humanitära kris", medan de andra kolumnerna visar värden som returneras av olika upptäcktsmetoder. Värden som hör till grundsanningsbegreppen indikeras av mörka rutor. Kontextmetoden returnerar värden som alla är relevanta (även om de saknas i den ursprungliga artikeln), medan co-förekomstmetoden returnerar många populära men irrelevanta begrepp (t.ex. politiker som gör allmänna uttalanden om ämnet). Kredit:IBM
På IBM Research AI, Vi byggde en AI-baserad lösning för att hjälpa analytiker att utarbeta rapporter. Tidningen som beskriver detta arbete vann nyligen det bästa papperspriset vid "In-Use" Track of the 2018 Extended Semantic Web Conference (ESWC).
Analytiker har ofta i uppgift att förbereda omfattande och korrekta rapporter om givna ämnen eller frågor på hög nivå, som kan användas av organisationer, företag, eller myndigheter för att fatta välgrundade beslut, minska risken i samband med deras framtidsplaner. För att förbereda sådana rapporter, analytiker måste identifiera ämnen, människor, organisationer, och händelser relaterade till frågorna. Som ett exempel, för att utarbeta en rapport om Brexits konsekvenser för Londons finansmarknader, en analytiker måste vara medveten om de viktigaste relaterade ämnena (t.ex. finansmarknader, ekonomi, Brexit, Brexit skilsmässoräkning), människor och organisationer (t.ex. Europeiska unionen, beslutsfattare i EU och Storbritannien, personer som är involverade i Brexit -förhandlingar), och händelser (t.ex. Förhandlingsmöten, Riksdagsval inom EU, etc.). En AI-assisterad lösning kan hjälpa analytiker att förbereda fullständiga rapporter och även undvika fördomar baserat på tidigare erfarenhet. Till exempel, en analytiker kan missa en viktig informationskälla om den inte har använts effektivt tidigare.
Kunskapsinduktionsteamet vid IBM Research AI byggde lösningen med hjälp av djupinlärning och strukturerad händelsedata. Laget, ledd av Alfio Gliozzo, vann också det prestigefyllda priset Semantic Web Challenge förra året.
Semantiska inbäddningar från händelsedatabaser
Den viktigaste tekniska nyheten i detta arbete är skapandet av semantiska inbäddningar av strukturerade händelsedata. Ingången till vår semantiska inbäddningsmotor är en stor strukturerad datakälla (t.ex. databastabeller med miljontals rader) och utdata är en stor samling vektorer med en konstant storlek (t.ex. 300) där varje vektor representerar det semantiska sammanhanget för ett värde i de strukturerade data. Kärnidén liknar den populära och mycket använda idén om ordinbäddningar i naturligt språkbehandling, men istället för ord, vi representerar värden i strukturerad data. Resultatet är en kraftfull lösning som möjliggör snabb och effektiv semantisk sökning över olika fält i databasen. En enda sökfråga tar bara några millisekunder men hämtar resultat baserade på att bryta hundratals miljoner poster och miljarder värden.
Medan vi experimenterade med olika neurala nätverksmodeller för att bygga inbäddningar, vi fick mycket lovande resultat med hjälp av en enkel anpassning av den ursprungliga hopp-gram word2vec-modellen. Detta är en effektiv grund modell för neurala nätverk baserad på en arkitektur som förutsäger sammanhanget (omgivande ord) som ges ett ord i ett dokument. I vårt arbete, vi har inte att göra med textdokument utan med strukturerade databasposter. För detta, vi behöver inte längre använda ett skjutfönster med en fast eller slumpmässig storlek för att fånga sammanhanget. I strukturerade data, sammanhanget definieras av alla värden i samma rad oavsett kolumnposition, eftersom två intilliggande kolumner i en databas är lika relaterade som alla andra två kolumner. Den andra skillnaden i våra inställningar är behovet av att fånga olika fält (eller kolumner) i databasen. Vår motor behöver aktivera både allmänna semantiska frågor (dvs. returnera alla databasvärden som är relaterade till det angivna värdet) och fältspecifika värden (dvs. returvärden från ett givet fält relaterat till inmatningsvärdet). För detta, vi tilldelar en typ till vektorerna som byggs ut från varje fält och bygger ett index som stöder typspecifika eller generiska frågor.
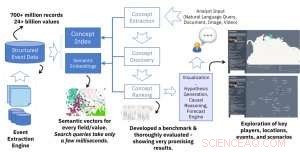
Kredit:IBM
För det arbete som beskrivs i vårt papper, vi använde tre offentligt tillgängliga händelsedatabaser som input:GDELT, ICEWS, och EventRegistry. Övergripande, dessa databaser består av hundratals miljoner poster (JSON -objekt eller databasrader) och miljarder värden i olika fält (attribut). Med vår inbäddningsmotor, varje värde blir till en vektor som representerar sammanhanget i data.
En enkel hämtningsfråga
Man kan se hur väl sammanhanget fångas upp av vår motor med hjälp av en enkel hämtningsfråga. Till exempel, när du frågar efter värdet "Hilary Clinton" (felstavat) i fältet "person" i GDELT GKG, den första träff eller den mest liknande vektorn är "Hilary Clinton" (felstavat) under fältet "namn" och de näst mest liknande vektorerna är "Hillary Clinton" (korrekt stavning) under fälten "person" och "namn". Detta beror på det mycket liknande sammanhanget med det felstavade värdet och rätt stavning, och även värdena över fälten "namn" och "person". Resten av träffarna för ovanstående fråga inkluderar amerikanska politiker, särskilt de som var aktiva under det senaste presidentvalet, liksom närstående organisationer, personer med liknande arbetsroller tidigare, och familjemedlemmar.
Likhetssökning på kombinerade frågor
Självklart, vår lösning kan uppnå mycket mer än en enkel hämtningsfråga. Särskilt, man kan kombinera dessa frågor för att förvandla en uppsättning värden extraherade från en naturlig språkfråga till en vektor och utföra likhetssökning. Vi utvärderade resultatet av detta tillvägagångssätt med hjälp av ett riktmärke byggt på rapporter skrivna av mänskliga experter, och undersökte vår motors förmåga att återge de begrepp som beskrivs i rapporterna med titeln på rapporten som enda ingång. Resultaten visade tydligt överlägsenheten hos våra semantiska inbäddningsbaserade konceptupptäckningsmetoder jämfört med en baslinjemetod som endast förlitar sig på att värdena förekommer samtidigt.
Nya applikationer inom konceptupptäckt
En mycket intressant aspekt av vårt ramverk är att alla värden och alla fält tilldelas en vektor som representerar dess sammanhang, vilket möjliggör nya intressanta applikationer. Till exempel, vi inbäddade latitud- och longitudkoordinater från händelser i databaserna i samma semantiska begreppsrum, och arbetade med Visual AI Lab under ledning av Mauro Martino för att bygga ett visualiseringsramverk som belyser relaterade platser på en geografisk karta med en fråga i naturligt språk. En annan intressant applikation som vi för närvarande undersöker är att använda de hämtade koncepten och deras semantiska inbäddningar som funktioner för en maskininlärningsmodell som analytikern behöver bygga. Detta kan användas i en automatisk maskininlärning och datavetenskap (AutoML) -motor, och stödja analytiker i en annan viktig aspekt av sina jobb. Vi planerar att integrera denna lösning i IBM:s Scenario Planning Advisor, ett beslutsstödssystem för riskanalytiker.
Denna berättelse publiceras på nytt med tillstånd av IBM Research. Läs den ursprungliga historien här.