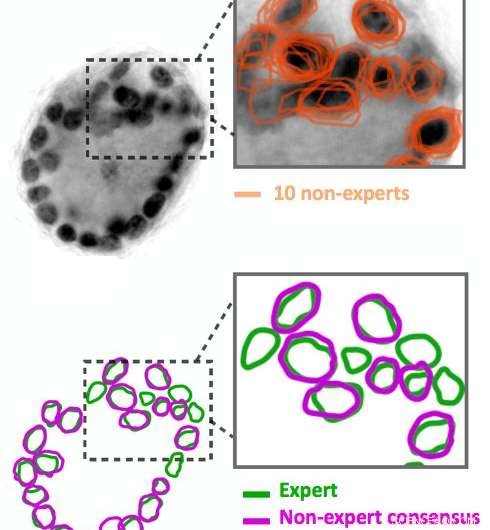
Icke-expert bildannoteringar är bullriga. Tio icke-experter beskrev de mörka svarta cirklarna i bilden, som är cellkärnor. Deras resultat (visas i orange) stämmer inte exakt överens. Våra algoritmer kan härleda en samsynskontur (visas i lila) från de bullriga data. Jämför detta samförstånd med expertkommentar av samma bild (visas i grönt). Kredit:IBM
Idag rapporterade mitt IBM -team och mina kollegor vid UCSF Gartner -labbet Naturmetoder ett innovativt tillvägagångssätt för att generera datamängder från icke-experter och använda dem för utbildning i maskininlärning. Vår strategi är utformad för att göra det möjligt för AI-system att lära sig lika bra av icke-experter som de gör av expertgenererade utbildningsdata. Vi utvecklade en plattform, kallad Quanti.us, som gör det möjligt för icke-experter att analysera bilder (en vanlig uppgift inom biomedicinsk forskning) och skapa en kommenterad dataset. Plattformen kompletteras med en uppsättning algoritmer som är speciellt utformade för att tolka denna typ av "bullriga" och ofullständiga data korrekt. Används tillsammans, dessa tekniker kan utöka tillämpningar av maskininlärning inom biomedicinsk forskning.
Icke-experter och bullriga data
Den begränsade tillgängligheten av högkvalitativa kommenterade datamängder är en flaskhals för att främja maskininlärning. Genom att skapa algoritmer som kan leverera exakta resultat från annoteringar av lägre kvalitet-och ett system för att snabbt samla in sådan information-kan vi hjälpa till att lindra flaskhalsen. Att analysera bilder för funktioner av intresse är ett bra exempel. Expertbildannotering är korrekt men tidskrävande, och automatiserade analystekniker som kontrastbaserad segmentering och kantdetektering fungerar bra under definierade förhållanden men är känsliga för förändringar i experimentell installation och kan ge opålitliga resultat.
Ange publik-sourcing. Med Quanti.us, vi fick bildannoteringar från publiken 10–50 gånger snabbare än det skulle ha tagit en enda expert att analysera samma bilder. Men, som man kan förvänta sig, kommentarer från icke-experter var bullriga:vissa identifierade en funktion korrekt och andra var utanför målet. Vi utvecklade algoritmer för att bearbeta bullriga data, härleda den korrekta placeringen av en funktion från aggregeringen av både on- och off-target träffar. När vi utbildade ett djupt konvolutionellt regressionsnätverk med hjälp av datamängden, det fungerade nästan lika bra som ett nätverk som utbildats i expertkommentarer, med avseende på precision och återkallelse. Tillsammans med artikeln som beskriver vårt tillvägagångssätt och strategi, vi släppte källkoden för vår algoritm.
Applikationer inom cellteknik
Bildanalys är central för många områden inom kvantitativ biologi och medicin. För några år sedan tillkännagav vi och våra samarbetspartners det NSF-finansierade Center for Cellular Construction (CCC), ett vetenskaps- och teknikcenter som är banbrytande inom den nya vetenskapliga disciplinen cellteknik. CCC underlättar nära samarbete mellan experter från olika discipliner, som maskininlärning, fysik, datavetenskap, cell- och molekylärbiologi, och genomik, att driva framsteg inom cellteknik. Vi strävar efter att studera och skapa celler som kan användas som automatiserade maskiner, eller ad hoc -sensorer, för att lära sig ny och viktig information om en mängd olika biologiska enheter och deras förhållande till miljön de lever i. Vi använder bildanalys för att identifiera positionen och storleken på inre cellkomponenter. Men även med avancerad bildteknik, exakt slutsats av cellulära substrukturer kan vara otroligt bullriga, vilket gör det svårt att arbeta på cellens komponenter. Vår teknik kan använda denna bullriga data för att korrekt förutsäga var de relevanta cellulära strukturerna kan vara, möjliggör bättre identifiering av organeller som är involverade i produktionen av viktiga kemikalier eller potentiella läkemedelsmål i en sjukdom.
Vi tror att våra algoritmer är ett viktigt första steg mot mer komplexa AI -plattformar. Sådana system kan använda ytterligare "human in the loop" -paradigm, genom att involvera en biolog för att rätta till misstag under utbildningsfasen, till exempel, för att ytterligare förbättra prestanda. Vi ser också en möjlighet att tillämpa vår metod bortom biologin på andra områden där högkvalitativa kommenterade datamängder kan vara knappa.
Denna berättelse publiceras på nytt med tillstånd av IBM Research. Läs den ursprungliga historien här.