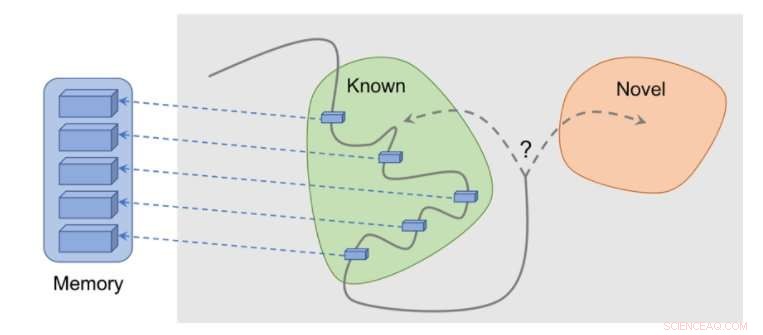
Hur metoden fungerar:observationer läggs till i minnet, belöning beräknas baserat på hur långt vår nuvarande observation är från den mest liknande observation i minnet. Agenten får mer belöning för att se observationer som ännu inte är representerade i minnet. Kredit:Savinov et al.
Flera verkliga uppgifter har glesa belöningar och detta innebär utmaningar för utvecklingen av förstärkningsinlärningsalgoritmer (RL). En lösning på detta problem är att låta en agent självständigt skapa en belöning för sig själv, gör belöningar tätare och mer lämpliga för inlärning.
Till exempel, inspirerad av det nyfikna beteende som djur utforskar sin miljö med, en RL -algoritms observation av något nytt kan belönas med en bonus. Denna bonus, sammanfattade med den verkliga uppgiftsbelöningen, skulle då tillåta RL -algoritmer att lära av en kombinerad belöning.
Forskare på DeepMind, Google Brain och ETH Zurich har nyligen tagit fram en ny nyfikenhetsmetod som använder episodiskt minne för att bilda denna nyhetsbonus. Denna bonus bestäms genom att jämföra aktuella observationer och observationer lagrade i minnet.
"Huvudsyftet med vårt arbete var att undersöka nya minnesbaserade sätt att bygga in förstärkningslärande (RL) agenter med nyfikenhet, 'med vilket vi menar en strävan att utforska miljön även i fullständig frånvaro av belöningar, "Tim Lillicrap på DeepMind och Nikolay Savinov på Google Brain berättade för TechXplore i ett e-postmeddelande." Nyfikenhet har ansökt på olika sätt av forskarsamhället, men vi ansåg att flera idéer kunde ha nytta av ytterligare utforskning. "
De nyckeltankar som utforskas i detta nyligen publicerade dokument är baserade på en tidigare studie utförd av Savinov, som föreslog en ny minnesarkitektur inspirerad av däggdjursnavigering. Denna arkitektur tillåter agenter att upprepa en rutt genom en miljö med endast en visuell genomgång. Den nya metoden som forskarna utvecklat tar detta ett steg längre, försöker uppnå bra utforskning som drivs av nyfikenhet.
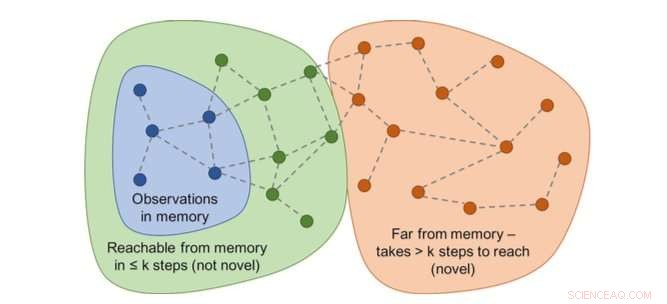
Diagram över räckvidd skulle avgöra nyheten. I praktiken, den här grafen är inte tillgänglig - så en neuronal nätverks approximator är utbildad för att uppskatta ett antal steg mellan observationerna. Kredit:Savinov et al.
"Medan du agerar, agenten lagrar förekomst av observationsrepresentationer i sitt episodiska minne, "Lillicrap och Savinov sa." För att avgöra om den aktuella observationen är ny eller inte, det jämförs med dem i minnet. Om inget liknande hittas, den aktuella observationen anses vara ny och agenten belönas, annars får det en negativ belöning. Detta uppmuntrar agenten att utforska okänt territorium, ungefär som att vara nyfiken. "
Forskarna fann att det kan vara svårt att jämföra par observationer, eftersom det i slutändan är meningslöst att leta efter en exakt matchning i realistiska miljöer. Detta beror på att i verkliga situationer, en agent observerar sällan samma sak två gånger.
"Istället, vi utbildade ett neuralt nätverk för att förutsäga om agenten kan nå den aktuella observationen från dem i minnet genom att vidta färre åtgärder än en fast tröskel; säga, fem åtgärder, "Lillicrap och Savinov förklarade." Observationer inom dessa fem åtgärder anses vara liknande, medan de som kräver fler åtgärder för att göra en övergång anses vara olika. "
Lillicrap, Savinov och deras kollegor testade deras tillvägagångssätt i VizDoom och DMLab, två visuellt rika 3D -miljöer. I VizDoom, agenten lärde sig att framgångsrikt navigera till ett avlägset mål minst två gånger snabbare än toppmodern nyfikenhetsmetod ICM. I DMLab, algoritmen generaliserade väl till ny, procedurmässigt genererade spelnivåer, att nå sitt önskade mål minst två gånger oftare än ICM på testlabyrinter med mycket glesa belöningar.

Surprise-based method (ICM) är att ständigt märka väggar med en laserliknande science fiction-gadget istället för att utforska labyrinten. Detta beteende liknar den kanalväxling som beskrivits tidigare:även om resultatet av taggning är teoretiskt förutsägbart, det är inte lätt och kräver tydligen en djup kunskap om fysik som inte är enkel att skaffa för en allmän agent. Kredit:Savinov et al.
"Vi märkte en intressant nackdel med en av de mest populära metoderna för att genomsyra agenter med nyfikenhet, "Lillicrap och Savinov sa." Vi fann att denna metod, baserad på överraskningen som beräknas av en långsamt föränderlig modell som försöker förutsäga vad som kommer att hända härnäst, kan resultera i ett omedelbart tillfredsställande svar från agenten:istället för att lösa uppgiften, det kommer att utnyttja handlingar som leder till oförutsägbara konsekvenser för att få omedelbar belöning. "
Denna märkliga händelse, även känd som "soffpotatis" -problem, innebär att en agent hittar sätt att omedelbart tillfredsställa sig själv genom att utnyttja handlingar som leder till oförutsägbara konsekvenser. Till exempel, när man får en fjärrkontroll för TV, agenten kanske inte gör något annat än att byta kanal, även om den ursprungliga uppgiften var helt annorlunda, som att söka efter ett mål i en labyrint.
"Denna brist kan lindras med hjälp av episodiskt minne tillsammans med ett rimligt mått på observationslikhet, vilket är vårt bidrag, "Lillicrap och Savinov sa." Detta öppnar ett sätt för mer intelligent utforskning. "

Vår metod visar en rimlig undersökning. Kredit:Savinov et al.
Den nya nyfikenhetsmetoden som Lillicrap tagit fram, Savinov, och deras kollegor kan hjälpa till att replikera nyfikenhetsliknande färdigheter i RL-algoritmer, låta dem självständigt skapa belöningar för sig själva. I framtiden, forskarna skulle vilja använda episodiskt minne inte bara för att bevilja belöningar, men också för att planera åtgärder.
"Till exempel, kan innehåll som hämtats från minnet användas för att tänka på vart du ska gå vidare? "sa Lillicrap och Savinov." Detta är för närvarande en stor vetenskaplig utmaning:om det löses, agenter skulle snabbt kunna anpassa prospekteringsstrategier till nya miljöer, så att inlärning kan ske mycket snabbare. "
© 2018 Tech Xplore














