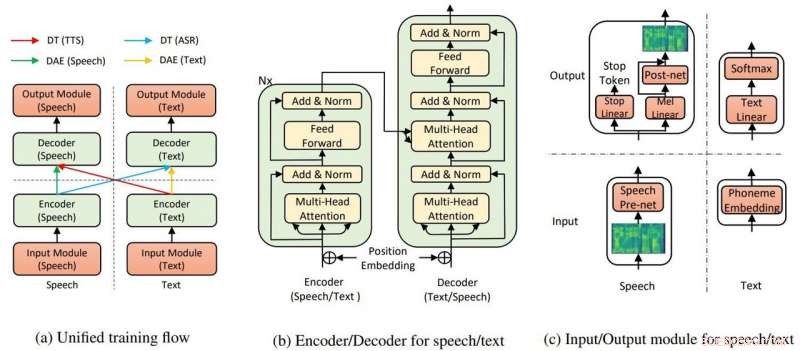
Den övergripande modellstrukturen för TTS och ASR. Kredit:Yi Ren, Xu Tan et al.
Microsoft Research Asia har rönt applåder för att ha dragit av text till tal som kräver lite träning – och visat "otroligt" realistiska resultat.
Kyle Wiggers in VentureBeat sa text-till-tal-algoritmer inte var nya och andra ganska kapabla men, fortfarande, teaminsatsen hos Microsoft har fortfarande en fördel.
Abdullah Matloob in Digital informationsvärld :"Text-till-tal-konvertering blir smart med tiden, men nackdelen är att det fortfarande kommer att ta en överdriven mängd träningstid och resurser att bygga en naturligt klingande produkt."
Letar efter ett sätt att dra på axlarna av träningstid och resurser för att skapa resultat som låter naturligt, Microsoft Research och kinesiska forskare upptäckte ett annat sätt att konvertera text-till-tal.
Fabienne Lang in Intressant teknik :Deras svar visar sig vara en AI text-till-tal som använder 200 röstprover (endast 200) för att skapa realistiskt klingande tal för att matcha transkriptioner. Lang sa, "Detta betyder ungefär 20 minuters värde."
Att kravet endast var 200 ljudklipp och motsvarande transkriptioner imponerade Wiggers i VentureBeat . Han noterade också att forskarna utvecklade ett AI-system "som utnyttjar oövervakad inlärning - en gren av maskininlärning som hämtar kunskap från omärkta, oklassificerad, och okategoriserade testdata."
Deras papper finns uppe på arXiv. "Nästan oövervakad text till tal och automatisk taligenkänning" är av Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu. Författare är Zhejiang University, Microsoft Research och Microsoft Search Technology Center (STC) Asien.
I deras tidning, teamet sa att TTS AI använder två nyckelkomponenter, en transformator och denoising auto-encoder, för att få det hela att fungera.
"Genom transformatorerna, Microsofts text-till-tal AI kunde känna igen tal eller text som antingen input eller output, " sa en artikel i Kantig av Rechelle Fuertes.
Tyler Lee in Ubergizmo gav en definition av transformator:"Transformatorer...är djupa neurala nätverk utformade för att efterlikna neuronerna i vår hjärna.."
MathWorks hade en definition för autoencoder. "En autokodare är en typ av artificiellt neuralt nätverk som används för att lära sig effektiv data (kodningar) på ett oövervakat sätt. Syftet med en autokodare är att lära sig en representation (kodning) för en uppsättning data, denoising autoencoders är vanligtvis en typ av autoencoders tränade att ignorera "brus" i korrupta ingångssampel."
Visade resultaten av deras experiment att deras idé är värd att jaga? "Vår metod uppnår 99,84 % när det gäller ordnivåns begriplig hastighet och 2,68 MOS för TTS, och 11,7 % PER för ASR [automatisk taligenkänning] på LJSpeech-dataset, genom att bara utnyttja 200 parade tal- och textdata (cirka 20 minuters ljud), tillsammans med extra oparad tal- och textdata."
Varför detta är viktigt:Detta tillvägagångssätt kan göra text till tal mer tillgänglig, sa rapporter.
"Forskare arbetar ständigt med att förbättra systemet, och hoppas på att i framtiden, det kommer att krävas ännu mindre arbete för att skapa verklighetstrogen diskurs, sa Lang.
Uppsatsen kommer att presenteras vid den internationella konferensen om maskininlärning, i Long Beach Kalifornien senare i år, och teamet planerar att släppa koden under de kommande veckorna, sa Wiggers.
Under tiden, forskarna går ännu inte ifrån sitt arbete med att presentera transformationer med få parade data.
"I det här arbetet, vi har föreslagit den nästan oövervakade metoden för text till tal och automatisk taligenkänning, som endast utnyttjar få parade tal- och textdata och extra oparade data... För framtida arbete, vi kommer att gå mot gränsen för oövervakad inlärning genom att enbart utnyttja oparade tal- och textdata, med hjälp av andra förträningsmetoder."
© 2019 Science X Network














