Kredit:IBM
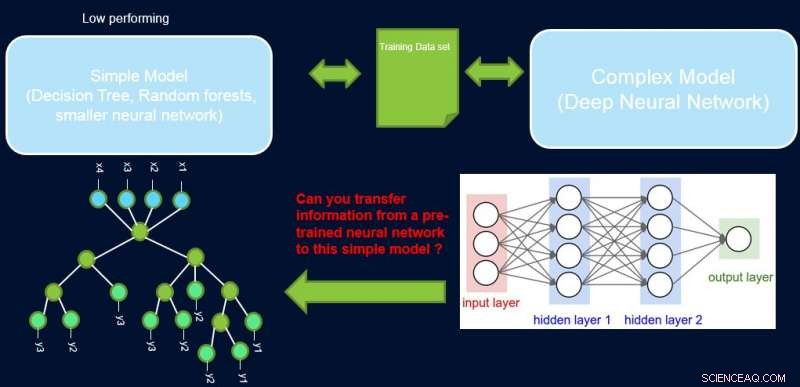
Tolkbarhet och prestanda i ett system är vanligtvis i strid med varandra, eftersom många av de bäst presterande modellerna (dvs djupa neurala nätverk) har en svart låda. I vårt arbete, Förbättra enkla modeller med konfidensprofiler, vi försöker överbrygga detta gap genom att föreslå en metod för att överföra information från ett högpresterande neuralt nätverk till en annan modell som domänexperten eller applikationen kan kräva. Till exempel, inom beräkningsbiologi och ekonomi, glesa linjära modeller är ofta att föredra, medan i komplexa instrumenterade områden som halvledartillverkning, ingenjörerna kanske föredrar att använda beslutsträd. Sådana enklare tolkningsbara modeller kan bygga upp förtroende hos experten och ge användbar insikt som leder till upptäckt av nya och tidigare okända fakta. Vårt mål visas bildmässigt nedan, för ett specifikt fall där vi försöker förbättra ett beslutsträds prestanda.
Antagandet är att vårt nätverk är en högpresterande lärare, och vi kan använda en del av dess information för att lära ut det enkla, tolkningsbar, men i allmänhet lågpresterande studentmodell. Att väga prover efter deras svårighetsgrad kan hjälpa den enkla modellen att fokusera på enklare prover som den framgångsrikt kan modellera vid träning, och därmed uppnå bättre övergripande prestanda. Vår inställning skiljer sig från att öka:i det tillvägagångssättet, svåra exempel med avseende på en tidigare ”svag” elev lyfts fram för efterföljande träning för att skapa mångfald. Här, svåra exempel är med avseende på en exakt komplex modell. Det betyder att dessa etiketter är nära slumpmässiga. Dessutom, om en komplex modell inte kan lösa dessa, det finns lite hopp om den enkla modellen med fast komplexitet. Därav, det är viktigt i vår installation att lyfta fram enkla exempel som den enkla modellen kan lösa.
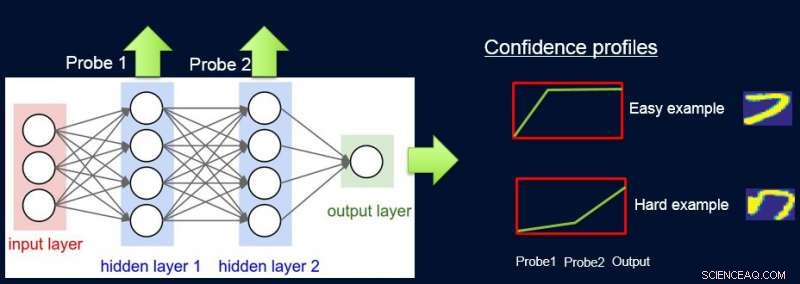
Att göra detta, vi tilldelar vikter till prover beroende på nätverkets svårighet att klassificera dem, och vi gör detta genom att introducera sonder. Varje sond tar sin input från ett av de dolda lagren. Varje sond har ett enda fullt anslutet lager med ett softmax -lager i storleken på nätverksutmatningen ansluten till den. Sonden i lager i fungerar som en klassificerare som endast använder prefixet för nätverket upp till lager i. Antagandet är att enkla instanser kommer att klassificeras korrekt med hög tillförlitlighet även med prover i första lagret, och så får vi förtroendenivåer s i från alla sonder för var och en av instanserna. Vi använder alla sid i att beräkna instanssvårigheter w i , t.ex. som arean under kurvan (AUC) på sid i 's.
Nu kan vi använda vikterna för att träna om den enkla modellen på den slutliga vägda datamängden. Vi kallar denna pipeline av sondering, få förtroendevikter, och omskolning av ProfWeight.
Kredit:IBM
Vi presenterar två alternativ för hur vi beräknar vikter för exempel i datamängden. I AUC -metoden som nämns ovan, vi noterar valideringsfelet/noggrannheten hos den enkla modellen när den tränas på den ursprungliga träningssatsen. Vi väljer prober som har en noggrannhet på minst α (> 0) större än den enkla modellen. Varje exempel är viktat baserat på den genomsnittliga konfidenspoängen för den sanna etiketten som beräknas med hjälp av de individuella mjuka förutsägelserna från sonderna.
Ett andra alternativ innebär optimering med hjälp av ett neuralt nätverk. Här lär vi oss optimala vikter för träningsuppsättningen genom att optimera följande mål:
S*=min w min β E [λ (Swβ (x), y)], sub. till. E [w] =1
där w är vikterna för varje instans, β betecknar parameterutrymmet för den enkla modellen S, och λ är dess förlustfunktion. Vi måste begränsa vikterna, eftersom den triviala lösningen för alla vikter som går till noll annars är optimal för ovanstående mål. Vi visar i tidningen att vår begränsning av E [w] =1 har en koppling till att hitta den optimala viktprovtagningen.
Kredit:IBM
Mer allmänt kan ProfWeight användas för att överföra till ännu enklare men ogenomskinliga modeller som mindre neurala nätverk, vilket kan vara användbart i domäner med allvarliga minnes- och strömbegränsningar. Sådana begränsningar upplevs vid användning av modeller på kantenheter i IoT -system eller på mobila enheter eller på obemannade flygbilar.
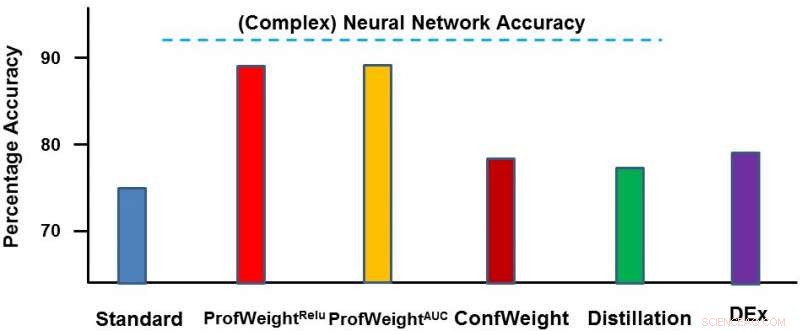
Vi testade vår metod på två domäner:en offentlig bilddataset CIFAR-10 och en egen tillverkningsdataset. På den första datamängden, våra enkla modeller var mindre neurala nätverk som skulle följa strikta minnes- och strömbegränsningar och där vi såg 3-4 procent förbättring. På den andra datauppsättningen, vår enkla modell var ett beslutsträd och vi förbättrade den avsevärt med ~ 13 procent, vilket ledde till praktiska resultat av ingenjören. Nedan visar vi ProfWeight i jämförelse med de andra metoderna i denna dataset. Vi observerar här att vi överträffar de andra metoderna med ganska stor marginal.
I framtiden skulle vi vilja hitta nödvändiga/tillräckliga förutsättningar när överföring med vår strategi skulle resultera i förbättring av enkla modeller. Vi skulle också vilja utveckla mer sofistikerade metoder för informationsöverföring än vad vi redan har åstadkommit.
Vi kommer att presentera detta arbete i ett dokument med titeln "Förbättra enkla modeller med konfidensprofiler" vid 2018 -konferensen om neural informationsbehandlingssystem, på onsdag, 5 december kl. under kvällens affischpass från 17.00 - 19.00 i rum 210 &230 AB (#90).
Denna berättelse publiceras på nytt med tillstånd av IBM Research. Läs den ursprungliga historien här.














