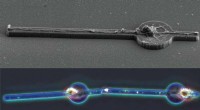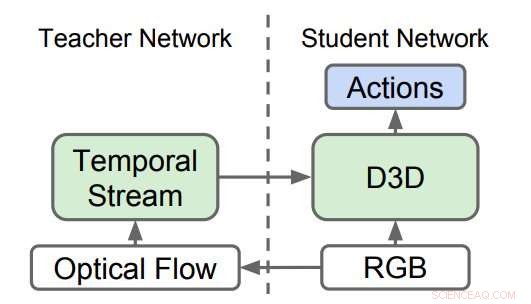
Destillerade 3D-nätverk (D3D). Forskarna tränade en 3D CNN för att känna igen handlingar från RGB-video samtidigt som de destillerade kunskap från ett nätverk som känner igen handlingar från optiska flödessekvenser. Under slutledning, endast D3D används. Kredit:Stroud et al.
Ett team av forskare på Google, University of Michigan och Princeton University har nyligen utvecklat en ny metod för videoaction-igenkänning. Videohandlingsigenkänning innebär att identifiera särskilda åtgärder som utförs i videofilmer, som att öppna en dörr, stänga en dörr, etc.
Forskare har försökt lära datorer att känna igen mänskliga och icke-mänskliga handlingar på video i flera år. De flesta toppmoderna verktyg för videohandlingsigenkänning använder en ensemble av två neurala nätverk:den rumsliga strömmen och den tidsmässiga strömmen.
I dessa tillvägagångssätt, det ena neurala nätverket är tränat att känna igen handlingar i en ström av vanliga bilder baserat på utseende (d.v.s. den "spatiala strömmen") och det andra nätverket är tränad att känna igen handlingar i en ström av rörelsedata (d.v.s. den "temporala strömmen"). Resultaten som uppnås av dessa två nätverk kombineras sedan för att uppnå videohandlingsigenkänning.
Även om empiriska resultat som uppnåtts med "tvåströms"-metoder är bra, dessa metoder förlitar sig på två distinkta nätverk, snarare än en enda. Syftet med studien utförd av forskarna vid Google, University of Michigan och Princeton skulle undersöka sätt att förbättra detta, för att ersätta de två strömmarna av de flesta befintliga tillvägagångssätt med ett enda nätverk som lär sig direkt från data.
I de senaste studierna, både rumsliga och tidsmässiga strömmar består av 3D-konvolutionella neurala nätverk (CNN), som tillämpar spatiotemporala filter på videoklippet innan du försöker klassificera. Teoretiskt sett, dessa tillämpade tidsfilter bör tillåta den rumsliga strömmen att lära sig rörelserepresentationer, därför borde den tidsmässiga strömmen vara onödig.
I praktiken, dock, prestandan hos verktyg för videoåtgärdsigenkänning förbättras när en helt separat tidsström inkluderas. Detta tyder på att den rumsliga strömmen ensam inte kan detektera några av de signaler som fångas av den tidsmässiga strömmen.
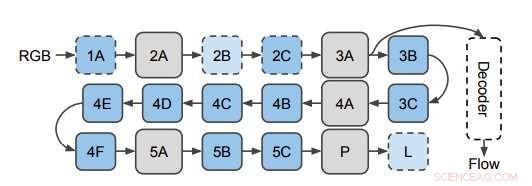
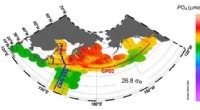
Nätverket som används för att förutsäga optiskt flöde från 3D CNN-funktioner. Forskarna applicerar avkodaren på dolda lager i 3D CNN (avbildad här på lager 3A). Detta diagram visar strukturen för I3D/S3D-G, där blå rutor representerar faltning (streckade linjer) eller startblock (heldragna linjer), och grå rutor representerar poolande block. Lagernamn är samma som de som används i Inception. Kredit:Stroud et al.
För att undersöka denna observation ytterligare, forskarna undersökte om den rumsliga strömmen av 3-D CNN för videoaction-igenkänning verkligen saknar rörelserepresentationer. Senare, de visade att dessa rörelserepresentationer kan förbättras med hjälp av destillation, en teknik för att komprimera kunskap i en ensemble till en enda modell.
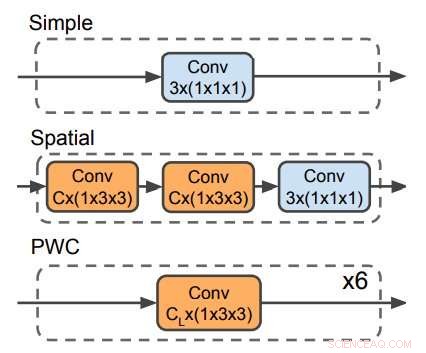
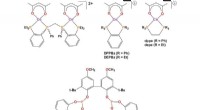
Tre avkodare används för att förutsäga optiskt flöde. PWC-avkodaren liknar det optiska flödespredikteringsnätverket från PWC-net. Ingen avkodare använder tidsfilter. Kredit:Stroud et al.
Forskarna utbildade ett "lärarnätverk" för att känna igen handlingar med tanke på rörelseinmatningen. Sedan, de utbildade ett andra "studentnätverk", som bara matas med strömmen av vanliga bilder, med ett dubbelt mål:klara av uppgiften att identifiera handling och efterlikna resultatet av lärarnätverket. Väsentligen, studentnätverket lär sig att känna igen utifrån både utseende och rörelse, bättre än läraren och samt de större och krångligare tvåströmsmodellerna.
Nyligen, ett antal studier testade också en alternativ metod för videohandlingsigenkänning, vilket innebär att man tränar ett enda nätverk med två olika mål:att prestera bra vid åtgärdsigenkänningsuppgiften och direkt förutsäga lågnivårörelsesignalerna (d.v.s. optiskt flöde) i videon. Forskarna fann att deras destillationsmetod överträffade detta tillvägagångssätt. Detta tyder på att det är mindre viktigt för ett nätverk att effektivt känna igen det optiska flödet på låg nivå i en video än att reproducera den kunskap på hög nivå som lärarnätverket har lärt sig om att känna igen handlingar från rörelse.
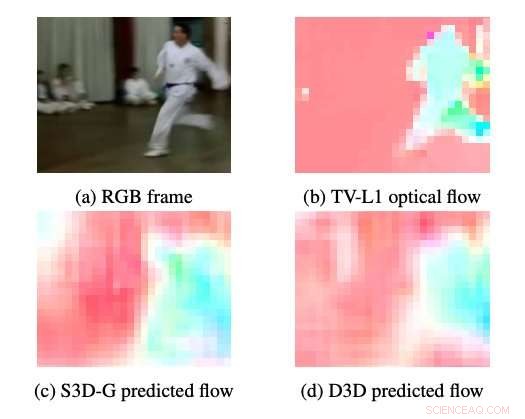
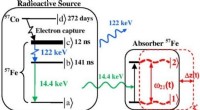
Exempel på optiskt flöde producerat av S3DG och D3D (utan finjustering) med PWC-avkodaren applicerad på lager 3A. Färgen och mättnaden för varje pixel motsvarar rörelsens vinkel och storlek, respektive. TV-L1 optiskt flöde visas i 28 × 28px, utgångsupplösningen för dekodern. Kredit:Stroud et al.
Forskarna visade att det är möjligt att träna ett enströms neuralt nätverk som fungerar lika bra som tvåströmsmetoder. Deras resultat tyder på att prestandan hos nuvarande toppmoderna metoder för videohandlingsigenkänning skulle kunna uppnås med ungefär 1/3 av beräkningen. Detta skulle göra det lättare att köra dessa modeller på datorbegränsade enheter, som smartphones, och i större skala (t.ex. för att identifiera åtgärder, som "slam dunks", i YouTube-videor).
Övergripande, denna senaste studie belyser några av bristerna med befintliga metoder för videohandlingsigenkänning, föreslår ett nytt tillvägagångssätt som innebär utbildning av en lärare och ett studentnätverk. Framtida forskning, dock, skulle kunna försöka uppnå toppmoderna prestationer utan behov av ett lärarnätverk, genom att mata utbildningsdata direkt till studentnätverket.
© 2019 Science X Network