En modell av forskare från MIT och Microsoft identifierar fall där autonoma bilar har "lärt sig" från träningsexempel som inte matchar vad som faktiskt händer på vägen, som kan användas för att identifiera vilka inlärda åtgärder som kan orsaka verkliga fel. Kredit:MIT News
En ny modell utvecklad av MIT och Microsofts forskare identifierar fall där autonoma system har "lärt sig" från träningsexempel som inte stämmer överens med vad som faktiskt händer i den verkliga världen. Ingenjörer skulle kunna använda den här modellen för att förbättra säkerheten för system för artificiell intelligens, som förarlösa fordon och autonoma robotar.
AI-systemen som driver förarlösa bilar, till exempel, utbildas omfattande i virtuella simuleringar för att förbereda fordonet för nästan varje händelse på vägen. Men ibland gör bilen ett oväntat fel i den verkliga världen eftersom en händelse inträffar som borde, men gör det inte, ändra bilens beteende.
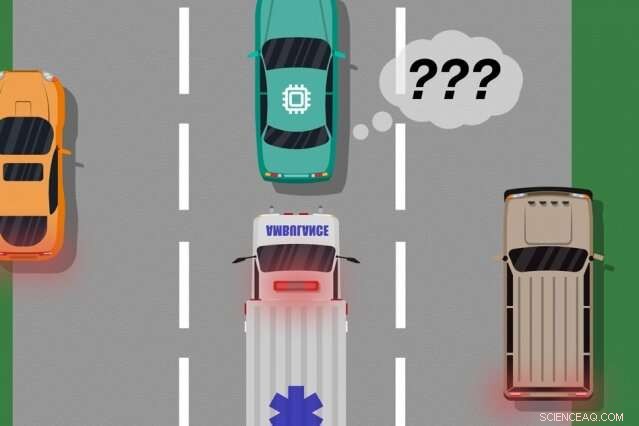
Tänk på en förarlös bil som inte var utbildad, och ännu viktigare inte har de sensorer som behövs, att skilja mellan distinkt olika scenarier, som stora, vita bilar och ambulanser med rött, blinkande ljus på vägen. Om bilen kör nerför motorvägen och en ambulans slår på sirenerna, bilen kanske inte vet att sakta ner och köra, eftersom den inte uppfattar ambulansen som annorlunda än en stor vit bil.
I ett par artiklar – som presenterades vid förra årets konferens för Autonomous Agents and Multiagent Systems och den kommande konferensen Association for the Advancement of Artificial Intelligence – beskriver forskarna en modell som använder mänsklig input för att avslöja dessa tränings-"blinda fläckar".
Som med traditionella metoder, forskarna satte ett AI-system genom simuleringsträning. Men då, en människa övervakar noga systemets handlingar när det agerar i den verkliga världen, ge feedback när systemet skapades, eller var på väg att göra, eventuella misstag. Forskarna kombinerar sedan träningsdata med mänsklig feedback, och använda maskininlärningstekniker för att ta fram en modell som pekar ut situationer där systemet med största sannolikhet behöver mer information om hur det ska agera korrekt.
Forskarna validerade sin metod med hjälp av videospel, med en simulerad människa som korrigerar den inlärda vägen för en karaktär på skärmen. Men nästa steg är att införliva modellen med traditionella tränings- och testmetoder för autonoma bilar och robotar med mänsklig feedback.
"Modellen hjälper autonoma system att bättre veta vad de inte vet, " säger första författaren Ramya Ramakrishnan, en doktorand i datavetenskap och artificiell intelligenslaboratoriet. "Många gånger, när dessa system distribueras, deras tränade simuleringar matchar inte den verkliga miljön [och] de kan göra misstag, som att råka ut för olyckor. Tanken är att använda människor för att överbrygga klyftan mellan simulering och den verkliga världen, på ett säkert sätt, så vi kan minska några av dessa fel."
Medförfattare på båda tidningarna är:Julie Shah, en docent vid institutionen för flyg- och astronautik och chef för CSAIL:s Interactive Robotics Group; och Ece Kamar, Debadeepta Dey, och Eric Horvitz, allt från Microsoft Research. Besmira Nushi är ytterligare en medförfattare på den kommande tidningen.
Tar emot feedback
Vissa traditionella träningsmetoder ger mänsklig feedback under verkliga testkörningar, men bara för att uppdatera systemets åtgärder. Dessa tillvägagångssätt identifierar inte blinda fläckar, vilket kan vara användbart för säkrare exekvering i den verkliga världen.
Forskarnas tillvägagångssätt sätter först ett AI-system genom simuleringsträning, där det kommer att producera en "policy" som i huvudsak kartlägger varje situation till den bästa åtgärden den kan vidta i simuleringarna. Sedan, systemet kommer att distribueras i den verkliga världen, där människor ger felsignaler i regioner där systemets handlingar är oacceptabla.
Människor kan tillhandahålla data på flera sätt, som genom "demonstrationer" och "korrigeringar". I demonstrationer, mänskliga handlingar i den verkliga världen, medan systemet observerar och jämför människans handlingar med vad den skulle ha gjort i den situationen. För förarlösa bilar, till exempel, en människa skulle manuellt styra bilen medan systemet producerar en signal om dess planerade beteende avviker från människans beteende. Matchningar och felmatchningar med människans handlingar ger bullriga indikationer på var systemet kan agera acceptabelt eller oacceptabelt.
Alternativt människan kan ge korrigeringar, med människan som övervakar systemet när det agerar i den verkliga världen. En människa skulle kunna sitta i förarsätet medan den autonoma bilen kör sig själv längs sin planerade rutt. Om bilens åtgärder är korrekta, människan gör ingenting. Om bilens åtgärder är felaktiga, dock, människan kan ta ratten, vilket sänder en signal om att systemet inte agerade oacceptabelt i den specifika situationen.
När återkopplingsdata från människan har sammanställts, systemet har i huvudsak en lista över situationer och, för varje situation, flera etiketter som säger att dess åtgärder var acceptabelt eller oacceptabelt. En enskild situation kan ta emot många olika signaler, eftersom systemet uppfattar många situationer som identiska. Till exempel, en autonom bil kan ha åkt tillsammans med en stor bil många gånger utan att sakta ner och köra. Men, i bara ett fall, en ambulans, som ser exakt likadant ut för systemet, kryssningar förbi. Den autonoma bilen kör inte och får en återkopplingssignal om att systemet vidtog en oacceptabel åtgärd.
"Vid det tillfället, systemet har fått flera motstridiga signaler från en människa:några med en stor bil bredvid sig, och det gick bra, och en där det fanns en ambulans på exakt samma plats, men det var inte bra. Systemet noterar lite att det gjorde något fel, men den vet inte varför, " säger Ramakrishnan. "Eftersom agenten får alla dessa motsägelsefulla signaler, nästa steg är att sammanställa informationen att fråga, "Hur sannolikt är det att jag gör ett misstag i den här situationen där jag fick de här blandade signalerna?"
Intelligent aggregering
Slutmålet är att få dessa tvetydiga situationer märkta som blinda fläckar. Men det går längre än att bara räkna ihop de acceptabla och oacceptabla handlingarna för varje situation. Om systemet utförde korrekta åtgärder nio gånger av 10 i ambulanssituationen, till exempel, en omröstning med enkel majoritet skulle märka den situationen som säker.
"Men eftersom oacceptabla handlingar är mycket sällsynta än acceptabla handlingar, systemet kommer så småningom att lära sig att förutsäga alla situationer som säkra, vilket kan vara extremt farligt, " säger Ramakrishnan.
För detta ändamål, forskarna använde Dawid-Skene-algoritmen, en maskininlärningsmetod som ofta används för crowdsourcing för att hantera etikettljud. Algoritmen tar som indata en lista över situationer, var och en har en uppsättning bullriga "acceptabla" och "oacceptabelt" etiketter. Sedan aggregerar den all data och använder vissa sannolikhetsberäkningar för att identifiera mönster i etiketterna för förutspådda döda fläckar och mönster för förutspådda säkra situationer. Med hjälp av den informationen, den matar ut en enda aggregerad "säker" eller "dödvinkel"-etikett för varje situation tillsammans med dess konfidensnivå för den etiketten. I synnerhet, Algoritmen kan lära sig i en situation där den kan ha, till exempel, presterade acceptabelt 90 procent av tiden, situationen är fortfarande tillräckligt tvetydig för att förtjäna en "blind fläck".
I slutet, Algoritmen producerar en typ av "värmekarta, " där varje situation från systemets ursprungliga träning tilldelas låg till hög sannolikhet att vara en blind fläck för systemet.
"När systemet distribueras i den verkliga världen, den kan använda denna inlärda modell för att agera mer försiktigt och intelligent. Om den inlärda modellen förutsäger att ett tillstånd är en blind fläck med hög sannolikhet, systemet kan fråga en människa om den acceptabla åtgärden, möjliggör säkrare utförande, " säger Ramakrishnan.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.