Vad vet din telefon om dig? Kredit:Rawpixel.com/Shutterstock.com
Sextiosju procent av smartphoneanvändarna förlitar sig på Google Maps för att hjälpa dem att snabbt och effektivt komma dit de är på väg.
En viktig egenskap hos Google Maps är dess förmåga att förutsäga hur lång tid olika navigeringsrutter kommer att ta. Det är möjligt eftersom mobiltelefonen för varje person som använder Google Maps skickar data om dess plats och hastighet tillbaka till Googles servrar, där den analyseras för att generera ny data om trafikförhållanden.
Information som denna är användbar för navigering. Men exakt samma data som används för att förutsäga trafikmönster kan också användas för att förutsäga andra typer av information – information som människor kanske inte är bekväma med att avslöja.
Till exempel, data om en mobiltelefons tidigare position och rörelsemönster kan användas för att förutsäga var en person bor, vem är deras arbetsgivare, där de går på gudstjänster och deras barns åldersintervall baserat på var de lämnar dem till skolan.
Dessa förutsägelser märker vem du är som person och gissa vad du sannolikt kommer att göra i framtiden. Forskning visar att människor i stort sett inte är medvetna om att dessa förutsägelser är möjliga, och, om de blir medvetna om det, gillar det inte. Från min synvinkel, som någon som studerar hur prediktiva algoritmer påverkar människors integritet, det är ett stort problem för digital integritet i USA.
Hur är allt detta möjligt?
Varje enhet du använder, varje företag du gör affärer med, varje onlinekonto du skapar eller lojalitetsprogram du går med i, och till och med regeringen samlar in data om dig.
De typer av data de samlar in inkluderar saker som ditt namn, adress, ålder, personnummer eller körkortsnummer, köptransaktionshistorik, surfaktivitet, röstregistreringsinformation, oavsett om du har barn som bor hos dig eller talar ett främmande språk, bilderna du har lagt upp på sociala medier, noteringspriset för ditt hem, om du nyligen har haft en livshändelse som att gifta dig, din kreditpoäng, vilken typ av bil kör du, hur mycket du spenderar på matvaror, hur mycket kreditkortsskuld du har och platshistoriken från din mobiltelefon.
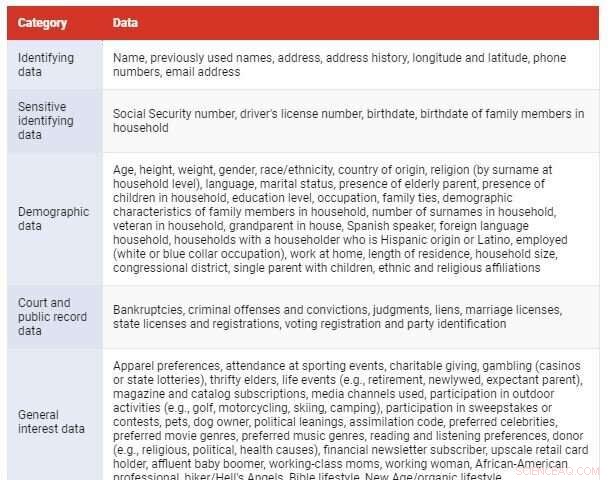
Kredit:The Conversation
Det spelar ingen roll om dessa datauppsättningar har samlats in separat av olika källor och inte innehåller ditt namn. Det är fortfarande lätt att matcha dem efter annan information om dig som de innehåller.
Till exempel, det finns identifierare i offentliga registerdatabaser, som ditt namn och hemadress, som kan matchas med GPS-platsdata från en app på din mobiltelefon. Detta gör det möjligt för en tredje part att koppla din hemadress till den plats där du tillbringar större delen av dina kvälls- och nattetid – förmodligen där du bor. Detta innebär att apputvecklaren och dess partners har tillgång till ditt namn, även om du inte direkt gav det till dem.
I USA., företagen och plattformarna du interagerar med äger den data de samlar in om dig. Detta innebär att de lagligt kan sälja denna information till datamäklare.
Datamäklare är företag som är i branschen med att köpa och sälja datamängder från ett brett spektrum av källor, inklusive platsdata från många mobiltelefonoperatörer. Datamäklare kombinerar data för att skapa detaljerade profiler för enskilda personer, som de säljer till andra företag.
Kombinerade datauppsättningar som denna kan användas för att förutsäga vad du vill köpa för att rikta in annonser. Till exempel, ett företag som har köpt data om dig kan göra saker som att koppla dina konton i sociala medier och din webbhistorik till vägen du tar när du är i ärenden och din köphistorik i din lokala livsmedelsbutik.
Arbetsgivare använder stora datamängder och prediktiva algoritmer för att fatta beslut om vem som ska intervjuas för jobb och förutsäga vem som kan sluta. Polisavdelningar gör listor över personer som kan vara mer benägna att begå våldsbrott. FICO, samma företag som beräknar kreditpoäng, beräknar också ett "läkemedelsefterlevnadspoäng" som förutsäger vem som kommer att sluta ta sina receptbelagda mediciner.
Hur medvetna är folk om detta?
Även om folk kanske är medvetna om att deras mobiltelefoner har GPS och att deras namn och adress finns i en offentlig registerdatabas någonstans, det är mycket mindre troligt att de inser hur deras data kan kombineras för att göra nya förutsägelser. Det beror på att integritetspolicyer vanligtvis bara innehåller vagt språk om hur data som samlas in kommer att användas.
I en januariundersökning, Pew Internet and American Life-projektet frågade vuxna Facebook-användare i USA om de förutsägelser som Facebook gör om deras personliga egenskaper, baserat på data som samlats in av plattformen och dess partners. Till exempel, Facebook tilldelar en kategori "mångkulturell affinitet" till vissa användare, gissa hur lika de är människor från olika ras eller etnisk bakgrund. Denna information används för att rikta in annonser.
Undersökningen visade att 74 procent av människorna inte kände till dessa förutsägelser. Ungefär hälften sa att de inte är bekväma med att Facebook förutsäger information som denna.
I min forskning, Jag har upptäckt att människor bara är medvetna om förutsägelser som visas för dem i en apps användargränssnitt, och det är vettigt med tanke på anledningen till att de valde att använda appen. Till exempel, en studie från 2017 av användare av träningsspårare visade att människor är medvetna om att deras spårningsenhet samlar in deras GPS-position när de tränar. Men detta översätts inte till medvetenhet om att aktivitetsspårningsföretaget kan förutsäga var de bor.
I en annan studie, Jag upptäckte att Google Search-användare vet att Google samlar in data om deras sökhistorik, och Facebook-användare är medvetna om att Facebook vet vilka deras vänner är. Men folk vet inte att deras Facebook-"gillar" kan användas för att exakt förutsäga deras politiska partitillhörighet eller sexuella läggning.
Vad kan man göra åt detta?
Dagens internet är till stor del beroende av att människor hanterar sin egen digitala integritet.
Företag ber människor i förväg att samtycka till system som samlar in data och gör förutsägelser om dem. Detta tillvägagångssätt skulle fungera bra för att hantera integritet, om människor vägrade att använda tjänster som har sekretesspolicyer de inte gillar, och om företag inte skulle bryta mot sin egen integritetspolicy.
Men forskning visar att ingen läser eller förstår dessa sekretesspolicyer. Och, även när företag möter konsekvenser för att bryta sina integritetslöften, det hindrar dem inte från att göra det igen.
Att kräva att användarna samtycker utan att förstå hur deras data kommer att användas gör det också möjligt för företag att lägga skulden på användaren. Om en användare börjar känna att deras data används på ett sätt som de faktiskt inte är bekväma med, de har inte utrymme att klaga, för att de samtyckte, höger?
Från min synvinkel, det finns inget realistiskt sätt för användare att vara medvetna om vilka typer av förutsägelser som är möjliga. Människor förväntar sig naturligtvis att företag endast använder sin data på ett sätt som är relaterade till de skäl de hade för att interagera med företaget eller appen i första hand. Men företag är vanligtvis inte juridiskt skyldiga att begränsa sättet de använder människors data till att bara gälla sådant som användarna kan förvänta sig.
Ett undantag är Tyskland, där Federal Cartel Office beslutade den 7 februari att Facebook specifikt måste be sina användare om tillåtelse att kombinera data som samlats in om dem på Facebook med data som samlats in från tredje part. I domen står det också att om människor inte ger sitt tillstånd till detta, de borde fortfarande kunna använda Facebook.
Jag tror att USA behöver starkare integritetsrelaterad reglering, så att företag blir mer transparenta och ansvariga gentemot användarna om inte bara den data de samlar in, men också vilka typer av förutsägelser de genererar genom att kombinera data från flera källor.
Den här artikeln är återpublicerad från The Conversation under en Creative Commons-licens. Läs originalartikeln.