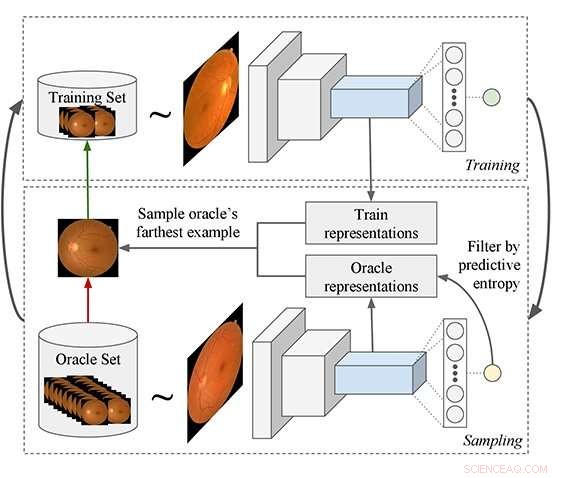
Föreslagen Active Learning-pipeline:Processen börjar med att träna en modell och använda den för att söka efter exempel från en omärkt datauppsättning som sedan läggs till i träningsuppsättningen. En ny frågefunktion föreslås som är bättre lämpad för Deep Learning (DL)-modeller. DL-modellen används för att extrahera funktioner från både orakel- och träningsexemplen, och sedan filtrerar algoritmen bort orakelexemplen som har låg prediktiv entropi. Till sist, Orakelexemplet väljs som i genomsnitt ligger längst bort i funktionsutrymme till alla träningsexempel. Kredit:Asim Smailagic
När system för artificiell intelligens lär sig att bättre känna igen och klassificera bilder, de blir mycket pålitliga när det gäller att diagnostisera sjukdomar, som hudcancer, från medicinska bilder. Men lika bra som de är på att upptäcka mönster, AI kommer inte att ersätta din läkare inom kort. Även när det används som verktyg, bildigenkänningssystem kräver fortfarande en expert för att märka data, och mycket data därtill:det behöver bilder av både friska patienter och sjuka patienter. Algoritmen hittar mönster i träningsdata och när den tar emot ny data, den använder vad den har lärt sig för att identifiera den nya bilden.
En utmaning är att det är tidskrävande och kostsamt för en expert att skaffa och märka varje bild. För att lösa detta problem, en grupp forskare från Carnegie Mellon University's College of Engineering, inklusive professorerna Hae Young Noh och Asim Smailagic, gick ihop för att utveckla en aktiv inlärningsteknik som använder en begränsad datauppsättning för att uppnå en hög grad av noggrannhet vid diagnostisering av sjukdomar som diabetisk retinopati eller hudcancer.
Forskarnas modell börjar arbeta med en uppsättning omärkta bilder. Modellen bestämmer hur många bilder som ska märkas för att få en robust och korrekt uppsättning träningsdata. Den väljer en första uppsättning slumpmässiga data att märka. När den informationen är märkt, den plottar dessa data över en distribution eftersom bilderna kommer att variera beroende på ålder, kön, fysikalisk egenskap, etc. För att kunna fatta ett bra beslut baserat på dessa data, proverna behöver täcka ett stort distributionsutrymme. Systemet bestämmer sedan vilken ny data som ska läggas till datamängden, med tanke på den nuvarande distributionen av uppgifter.
"Systemet mäter hur optimal denna distribution är, " sa nej, en docent i civil- och miljöteknik, "och sedan beräknar mätvärden när en viss uppsättning ny data läggs till den, och väljer den nya datamängden som maximerar dess optimalitet."
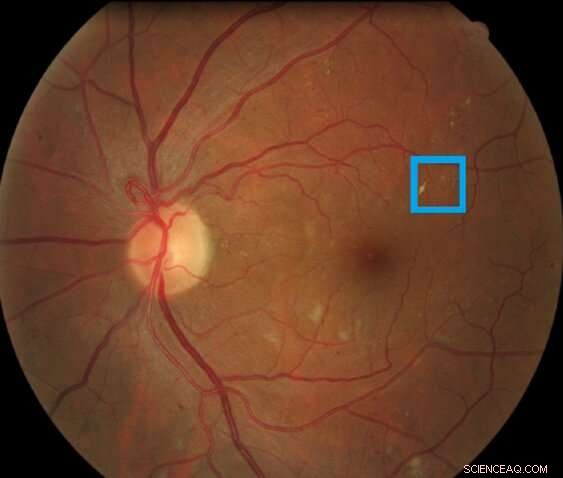
Bild av en näthinna som innehåller en retinal lesion associerad med diabetisk retinopati markerad i rutan. Denna typ av lesion kallas mikroaneurysm. Kredit:Asim Smailagic
Processen upprepas tills datauppsättningen har en tillräckligt bra fördelning för att användas som träningsuppsättning. Deras metod, kallas MedAL (för medicinskt aktivt lärande), uppnådde 80 % noggrannhet vid upptäckt av diabetisk retinopati, använder endast 425 märkta bilder, vilket är en minskning med 32 % av antalet obligatoriska märkta exempel jämfört med standardmetoden för osäkerhetsprovtagning, och en minskning med 40 % jämfört med slumpmässigt urval.
De testade också modellen på andra sjukdomar, inklusive bilder på hudcancer och bröstcancer, för att visa att det kan gälla en mängd olika medicinska bilder. Metoden är generaliserbar, eftersom dess fokus ligger på hur man använder data strategiskt snarare än att försöka hitta ett specifikt mönster eller särdrag för en sjukdom. Det kan också tillämpas på andra problem som använder djupinlärning men som har databegränsningar.
"Vår aktiva inlärningsmetod kombinerar prediktiv entropibaserad osäkerhetssampling och en distansfunktion på ett inlärt funktionsutrymme för att optimera urvalet av omärkta prover, sa Smailagic, en forskningsprofessor i Carnegie Mellons Engineering Research Accelerator. "Metoden övervinner begränsningarna hos de traditionella tillvägagångssätten genom att effektivt välja endast de bilder som ger mest information om den övergripande datadistributionen, minskar beräkningskostnaderna och ökar både hastighet och noggrannhet."
I teamet ingick civil- och miljöingenjör Ph.D. studenter Mostafa Mirshekari, Jonathan Fagert, och Susu Xu, och magisterstudenter i el- och datateknik Devesh Walawalkar och Kartik Khandelwal. De presenterade sina resultat vid 2018 IEEE internationella konferens om maskininlärning och applikationer i december, där de fick ett pris för bästa papper för sitt romanarbete.














