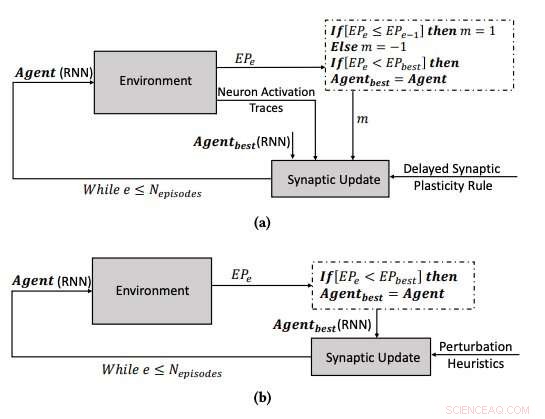
(a) Inlärningsprocessen som använder den fördröjda synaptiska plasticiteten, och (b) inlärningsprocessen genom att optimera parametrarna för RNN:erna med användning av backklättringsalgoritmen. Kredit:Yaman et al.
Den mänskliga hjärnan förändras kontinuerligt över tiden, skapa nya synaptiska kopplingar baserade på erfarenheter och information som lärts under en livstid. Under de senaste åren, Forskare med artificiell intelligens (AI) har försökt att återskapa denna fascinerande förmåga, känd som 'plasticitet, ' i artificiella neurala nätverk (ANN).
Forskare vid Eindhoven University of Technology (Tu/e) och University of Trento har nyligen föreslagit ett nytt tillvägagångssätt inspirerat av biologiska mekanismer som skulle kunna förbättra inlärningen i ANN. Deras studie, beskrivs i en tidning som förpublicerats på arXiv, finansierades av Europeiska unionens forsknings- och innovationsprogram Horisont 2020.
"En av de fascinerande egenskaperna hos biologiska neurala nätverk (BNN) är deras plasticitet, som låter dem lära sig genom att ändra sin konfiguration baserat på erfarenhet, "Anil Yaman, en av forskarna som genomförde studien, berättade för TechXplore. "Enligt den nuvarande fysiologiska förståelsen, dessa förändringar utförs på individuella synapser baserat på de lokala interaktionerna mellan neuroner. Dock, uppkomsten av ett sammanhängande globalt inlärningsbeteende från dessa individuella interaktioner är inte särskilt väl förstådd."
Inspirerad av plasticiteten hos BNN och dess evolutionära process, Yaman och hans kollegor ville härma biologiskt rimliga inlärningsmekanismer i artificiella system. För att modellera plasticitet i ANN, forskare använder vanligtvis något som kallas hebbiska inlärningsregler, som är regler som uppdaterar synapser baserat på neurala aktiveringar och förstärkningssignaler som tas emot från omgivningen.

Flera oberoende körningar av inlärningsprocesserna genom att använda olika utvecklade regler för fördröjd synaptisk plasticitet (den bästa DSP-regeln visas i grönt). Kredit:Yaman et al.
När förstärkningssignaler inte är tillgängliga omedelbart efter varje nätverksutgång, dock, vissa problem kan uppstå, vilket gör det svårare för nätverket att associera relevanta neuronaktiveringar med förstärkningssignalen. För att övervinna detta problem, känt som det "distala belöningsproblemet", ' forskarna utökade hebbiska plasticitetsregler så att de skulle möjliggöra inlärning i distala belöningsfall. Deras tillvägagångssätt, kallas fördröjd synaptisk plasticitet (DSP), använder något som kallas neuronaktiveringsspår (NAT) för att ge ytterligare lagring i varje synaps, samt att hålla reda på neuronaktiveringar när nätverket utför en viss uppgift.
"Synaptiska plasticitetsregler är baserade på de lokala aktiveringen av neuroner och en förstärkningssignal, " förklarade Yaman. "Men, i de flesta inlärningsproblem, förstärkningssignalerna tas emot efter en viss tidsperiod snarare än omedelbart efter varje åtgärd av nätverket. I detta fall, det blir problematiskt att associera förstärkningssignalerna med aktiveringen av neuroner. I det här arbetet, vi föreslog att vi skulle använda vad vi kallade "neuronaktiveringsspår, ' att lagra statistik över neuronaktiveringar i varje synaps och informera synaptiska plasticitetsregler om hur man utför fördröjda synaptiska förändringar."
En av de mest meningsfulla aspekterna av tillvägagångssättet som utformats av Yaman och hans kollegor är att det inte utgår från global information om problemet som det neurala nätverket kommer att lösa. Vidare, det beror inte på den specifika ANN-arkitekturen och det är därför mycket generaliserbart.
"I praktiska termer, vår studie kan lägga grunden för nya inlärningsscheman som kan användas i ett antal neurala nätverkstillämpningar, såsom robotik och autonoma fordon, och i allmänhet i alla fall där en agent måste utföra adaptivt beteende i avsaknad av en omedelbar belöning som erhålls från dess handlingar, " Giovanni Iacca, en annan forskare involverad i studien, berättade för TechXplore. "Till exempel, i AI för videospel, en åtgärd vid det aktuella tidssteget kanske inte nödvändigtvis leder till en belöning just nu, men först efter en tid; en agent som visar personliga annonser kan få en "belöning" från användarens beteende först efter en tid, etc.)."
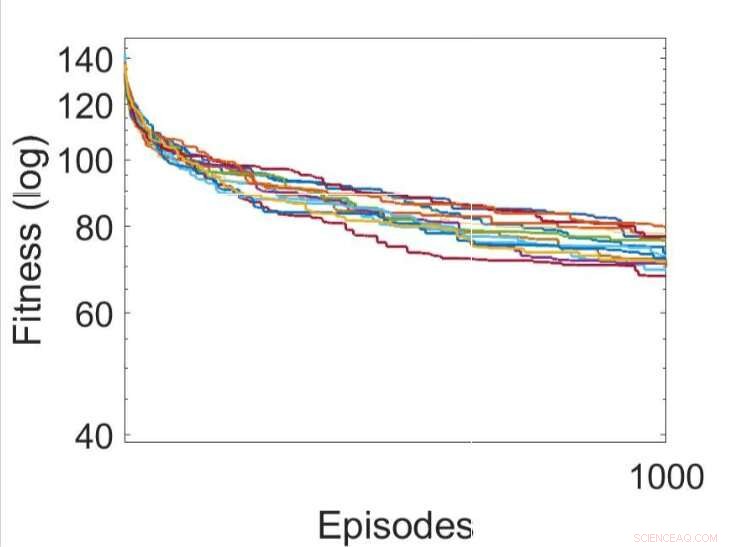
Flera oberoende körningar av inlärningsprocesserna genom att optimera parametrarna för RNN:erna med hjälp av backklättringsalgoritmen. Kredit:Yaman et al.
Forskarna testade sina nyligen anpassade hebbiska plasticitetsregler i en simulering av en trippel T-labyrintmiljö. I denna miljö, en agent som kontrolleras av ett enkelt återkommande neuralt nätverk (RNN) måste lära sig att hitta en av åtta möjliga målpositioner, från en slumpmässig nätverkskonfiguration.
Yaman, Iacca och deras kollegor jämförde prestandan som uppnåddes med deras tillvägagångssätt med den som uppnåddes när en agent utbildades med en analog iterativ lokal sökalgoritm, kallas hill climbing (HC). Den viktigaste skillnaden mellan HC-klättringsalgoritmen och deras tillvägagångssätt är att den förra inte använder någon domänkunskap (dvs lokala aktivering av neuroner), medan den senare gör det.
Resultaten som samlats in av forskarna tyder på att de synaptiska uppdateringarna som utförs av deras DSP-regler leder till effektivare träning och i slutändan bättre prestanda än HC-algoritmen. I framtiden, deras tillvägagångssätt skulle kunna bidra till att förbättra långsiktigt lärande i ANN, tillåta konstgjorda system att effektivt bygga nya kopplingar baserat på deras erfarenheter.
"Vi är främst intresserade av att förstå det framväxande beteendet och inlärningsdynamiken hos artificiella neurala nätverk, och utveckla en sammanhängande modell för att förklara hur synaptisk plasticitet uppstår i olika inlärningsscenarier, " sa Yaman. "Jag tror att det finns stora möjligheter för framtida forskning inom detta område, Det kommer till exempel att vara intressant att skala det föreslagna tillvägagångssättet för storskaliga komplexa problem (liksom djupa nätverk) och uppnå biologiskt inspirerade inlärningsmekanismer som kräver minsta möjliga övervakning (eller ingen alls).
© 2019 Science X Network