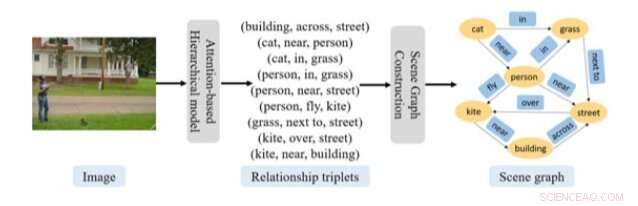
Övergripande procedur för förutsägelse av scendiagram som föreslagits i den senaste artikeln. Kredit:Gao et al.
Forskare vid Shanghai University har nyligen utvecklat ett nytt tillvägagångssätt baserat på återkommande neurala nätverk (RNN) för att förutsäga scengrafer från bilder. Deras tillvägagångssätt inkluderar en modell som består av två uppmärksamhetsbaserade RNN, samt en enhetslokaliseringskomponent.
Under det senaste decenniet eller så, forskare inom artificiell intelligens (AI) har utvecklat en mängd olika automatiska verktyg för att hantera, analysera och hämta digitala bilder. För att representera innehållet i bilder, traditionella tillvägagångssätt använder vanligtvis sökord eller funktioner med flera visningar. Dock, att förlita sig på antingen funktioner eller nyckelord leder ofta till en begränsad förståelse av bilder, misslyckas med att ge omfattande kunskap om dem.
För att åtgärda dessa brister, några år sedan, ett team av forskare vid Stanford University, Max Planck Institute for Informatics, Yahoo Labs och Snapchat föreslog användning av en scengraf, 'en typ av datastruktur för att beskriva visuella begrepp i en bild. Scengrafer kan lagra beskrivningen av en scen som avbildas i bilder som en strukturerad graf där noder representerar objektinformation och kanter ger förutsägelser mellan två noder.
Dessa strukturerade representationer kan hjälpa användare att hantera digitala bilder. Dock, att förutsäga en scengraf är ofta utmanande, eftersom det kräver effektiva verktyg för att känna igen objekt, liksom deras attribut och interaktioner mellan dem.
Även om det finns flera befintliga metoder för att förutsäga scengrafer, de flesta av dessa har betydande begränsningar. I deras studie, forskarna vid Shangai University bestämde sig för att utveckla en neural nätverksbaserad modell för att förutsäga scengrafer från ett visuellt uppmärksamhetsorienterat perspektiv.
"En scengraf ger en kraftfull mellanliggande kunskapsstruktur för olika visuella uppgifter, inklusive semantisk bildhämtning, bildtextning, och visuell frågesvar, "forskarna skrev i sin artikel, som publicerades på Wiley Online Library. "I det här pappret, uppgiften att förutsäga en scengraf för en bild är formulerad som två sammankopplade problem, d.v.s. att känna igen relationen trillingar, strukturerad som, och konstruera scengrafen från de igenkända relationstripletterna. "
Det tillvägagångssätt som detta team av forskare har utarbetat har två nyckelkomponenter, den ena syftade till att känna igen vad de kallar "relationstripletter" och den andra på att konstruera en scengraf. För att känna igen relationstripleter, forskarna använde en modell bestående av två uppmärksamhetsbaserade RNN i en hierarkisk organisation.
"Det första nätverket genererar en ämnesvektor för varje relationstriplett, medan det andra nätverket förutsäger varje ord i denna relationstriplett givet ämnesvektorn, " förklarade forskarna i sin uppsats. "Detta tillvägagångssätt fångar framgångsrikt kompositionsstrukturen och kontextberoendet hos en bild och relationstripletterna som beskriver dess scen."
När denna RNN-baserade modell har extraherat relevant information från en bild, den andra komponenten i deras tillvägagångssätt använder dessa data för att konstruera scengrafer. För detta steg, forskarna använde en metod för lokalisering av enheter, som kan bestämma grafens struktur med hjälp av den uppmärksamhetsinformation som finns tillgänglig. Förutom dessa två komponenter, the researchers used an algorithm to clarify the process through which their approach converts the generated relationship triplet information into a scene graph.
Their approach was evaluated using the popular visual genome (VG) dataset and the visual relationship dataset (VRD). For the purpose of their study, the researchers annotated the images in these datasets with a set of triplets, labeling each subject and object pair with location information.
"The results of experiments on two popular datasets demonstrate that the hierarchical recurrent approach from the visual-attention-oriented perspective inside our model has a distinct improvement in results over baseline models, " the researchers wrote. "In future work, we plan to enrich the scene graph with high-level semantics and more diversified attributes."
© 2019 Science X Network