
Winterfell. Kredit:mauRÍCIO santos (Unsplash, allmängods)
Forskare från Vrije Universiteit Amsterdam och Dutch Royal Academy's Humanities Cluster utvärderade fyra toppmoderna verktyg för att känna igen namn i text, att bedöma och förbättra deras prestationer på populär fiktion. De hittar lösningar för att öka verktygens förmåga att känna igen namn i en roman från en noggrannhet på 7 % till 90 %.
Natural Language Processing (NLP)-verktyg används ofta i många dagliga applikationer som Siri och Google, men effektiviteten av dessa tekniker är inte helt klarlagd. Forskare från Vrije Universiteit Amsterdam och Dutch Royal Academy's Humanities Cluster har utfört en grundlig utvärdering av fyra olika namnigenkänningsverktyg på populära 40 romaner, inklusive A Game of Thrones. Deras analyser, publiceras i PeerJ datavetenskap , lyfta fram typer av namn och texter som är särskilt utmanande för dessa verktyg att identifiera samt lösningar för att mildra detta. Dessutom, de extraherade sociala nätverk från romanerna för att utforska skillnader i berättelsens struktur. Dessa insikter kan hjälpa till att göra sådan teknik mer robust mot genreskillnader, och kan till exempel hjälpa till att göra denna teknik mer användbar för journalister som vill analysera stora datamängder som Panama Papers.
Många NLP-verktyg är baserade på maskininlärning; det är, ett datorprogram är tränat att identifiera mönster i text baserat på tidigare matade exempel. För att känna igen namn i text, den matas till exempel med många tidningsartiklar där människor noggrant har markerat namnen. Programmet får sedan i uppdrag att "lära sig" hur ett namn ser ut baserat på sammanhang (som, det föregås av Mr) eller formen på ordet (som att namn i allmänhet börjar med en stor bokstav på engelska). Nu, problemet med att tillämpa ett sådant system tränat på tidningar på romaner, är att författare till romaner har mycket mer frihet i sitt berättande än journalister som behöver hålla sig till fakta. Skönlitterära författare kan hitta på sina egna namn, som Tywin eller R'hllor, eller använd beskrivande karaktärsnamn direkt från ordboken, till exempel Grey Worm. Dessa namn beter sig inte som "normala" namn, sålunda har NLP-system svårt att känna igen dem i en text.
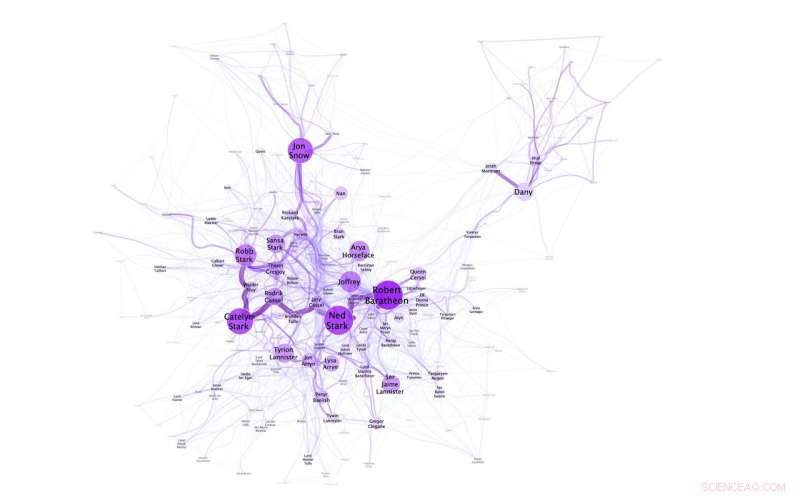
Nätverksvisualisering som visar att Dany/Daenerys inte är i närheten av andra huvudkaraktärer i "A Game of Thrones". Kredit:N.M. Dekker, CC BY-SA 4.0
Experimenten utförda av Niels Dekker (Trifork B.V.), Tobias Kuhn (Vrije Universiteit Amsterdam) och Marieke van Erp (KNAW Humanities Cluster) lyfter också fram språkets flexibilitet och hur namn kontextualiseras i berättelser. Det är till exempel möjligt att referera till Daenerys Targaryen som Daenerys och hon, men hon är också känd som Dany, Daenerys Stormborn, Drakarnas mor, Khaleesi, den oförbrända och Mhysa. Det sociala nätverket skapat för A Game of Thrones, illustrerar till exempel att Dany används av sina vänner, och hennes fullständiga namn Daenerys endast av hennes fiender (i hennes frånvaro).
Forskningen som beskrivs i denna publikation visar att mer uppmärksamhet bör ägnas åt prestandan hos NLP-verktyg och att det fortfarande finns arbete att göra innan "text" kan förstås fullt ut av datorer.














