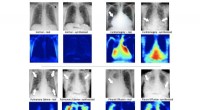
Jämförelse av djupprediktionsmodeller med ett videoklipp med rörliga kameror och människor. Kredit:Google
Vem sa att den virala vurm som heter Mannequin Challenge (MC) är klar och dammad? Inte så. Forskare har vänt sig till utmaningen som fick uppmärksamhet 2016 för att tjäna sitt mål. De använde MC för att träna ett neuralt nätverk som kan rekonstruera djupinformation från videorna.
"Learning the Depths of Moving People by Watching Frozen People" är namnet på deras tidning, nu uppe på arXiv, författad av Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu och William Freeman. Uppsatsen lämnades in i april i år.
Mannequin Challenge? Vem kan glömma? Det här var en YouTube-trend som blivit viral. Anthony Alford in InfoQ förde läsarna tillbaka till 2016, när ett internetmeme fick folk att slå sig samman i grupper som efterliknade mannekänger. De var "frusna" men en videofotograf gjorde rörelser runt scenen och tog en video från olika vinklar.
Alford skrev, eftersom kameran rör sig och resten av scenen är statisk, parallaxmetoder kan enkelt rekonstruera exakta djupkartor av mänskliga figurer i en mängd olika poser.
Som författarna sa, videorna involverade frysning i olika, naturliga poser, medan en handhållen kamera turnerade platsen.
För att träna det neurala nätverket, laget konverterade 2, 000 av videorna till 2D-bilder med högupplösta djupdata.
Alford sa att av de 2, 000 YouTube MC-videor, en datauppsättning producerades av 4, 690 sekvenser med totalt mer än 170K giltiga bilddjuppar. Målet för inlärningssystemet var den kända djupkartan för inmatningsbilden, beräknat från MC-videorna. DNN lärde sig att ta ingångsbilden, initial djupkarta, och mänsklig mask, och mata ut en "förfinad" djupkarta där människors djupvärden fylldes i.
Christine Fisher, Engadget :"För att träna det neurala nätverket, forskarna konverterade klippen till 2D-bilder, uppskattade kamerapositionen och skapade djupkartor. AI kunde sedan förutsäga djupet av rörliga objekt i videor med högre noggrannhet än vad som tidigare varit möjligt."
Att anta utmaningen beskrevs av två av tidningens medförfattare redan i maj i en Google-blogg.
"Eftersom hela scenen är stillastående (endast kameran rör sig), trianguleringsbaserade metoder – som multi-view-stereo (MVS) – fungerar, och vi kan få exakta djupkartor för hela scenen inklusive människorna i den. Vi samlade cirka 2000 sådana videor, spänner över ett brett utbud av realistiska scener med människor som naturligt poserar i olika gruppkonfigurationer." Tali Dekel, forskare och Forrester Cole, mjukvaruingenjör, maskinuppfattning, skrev mer om utmaningen de tog sig an.
"Det mänskliga visuella systemet har en anmärkningsvärd förmåga att förstå vår 3D-värld från dess 2D-projektion. Även i komplexa miljöer med flera rörliga objekt, människor kan upprätthålla en genomförbar tolkning av objektens geometri och djupordning. Området datorseende har länge studerat hur man uppnår liknande möjligheter genom att beräkningsmässigt rekonstruera en scens geometri från 2D-bilddata, men robust återuppbyggnad är fortfarande svårt i många fall."
Varför detta är viktigt:"Medan det nyligen har skett en ökning av användningen av maskininlärning för djupförutsägelse, detta arbete är det första att skräddarsy ett lärande-baserat tillvägagångssätt för fallet med samtidiga kamera och mänskliga rörelser, " sa de i majbloggen. "I detta arbete, vi fokuserar specifikt på människor eftersom de är ett intressant mål för augmented reality och 3D-videoeffekter."
På tal om resultat, Karen Hao, MIT Technology Review , sa forskarna konverterade 2, 000 av videorna till 2D-bilder med högupplösta djupdata och använde dem för att träna ett neuralt nätverk. Den kunde sedan förutsäga djupet av rörliga objekt i en video med mycket högre noggrannhet än vad som var möjligt med tidigare toppmoderna metoder.
© 2019 Science X Network