Kredit:Egor Zakharov et al.
Ett papper som diskuterar en konstgjord intelligens som nu finns uppe på arXiv ger teknikbevakare ännu en anledning att känna att detta är en tidsålder av skräck.
"Few-Shot Adversarial Learning of Realistic Neural Talking Head Models" av Egor Zakharov, Aliaksandra Shysheya, Egor Burkov och Victor Lempitsky avslöjar sin teknik som kan förvandla foton och målningar till animerade talking heads. Författartillhörighet inkluderar Samsung AI Center, Moskva och Skolkovo Institute of Science and Technology.
Nyckelspelaren i allt detta? Samsung. Det öppnade forskningscentra i Moskva, Cambridge och Toronto förra året och slutresultatet kan mycket väl bli fler rubriker i AI-historien.
Ja, Mona Lisa kan se ut som om hon berättar för sin TV-värd varför hon föredrar leave-in hårbalsam. Albert Einstein kan se ut som om han talar för inga hårprodukter alls.
De skrev att "vi överväger problemet med att syntetisera fotorealistiska personliga huvudbilder givet en uppsättning landmärken för ansiktet, som driver modellens animering." Ett skott lärande från en enda bildruta, även, är möjligt.
Khari Johnson, VentureBeat , noterade att de kan generera realistiska animerade talking heads från bilder utan förlitar sig på traditionella metoder som 3D-modellering.
Författarna betonade att "avgörande, systemet kan initiera parametrarna för både generatorn och diskriminatorn på ett personspecifikt sätt, så att träningen kan baseras på bara ett fåtal bilder och göras snabbt, trots behovet av att justera tiotals miljoner parametrar."
Vad är deras tillvägagångssätt? Ivan Mehta in Nästa webb gick läsarna genom stegen som formar deras teknik.
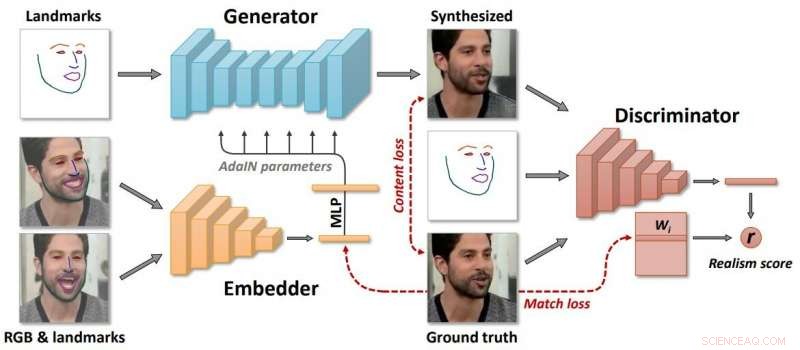
"Samsung sa att modellen skapar tre neurala nätverk under inlärningsprocessen. För det första, det skapar ett inbäddat nätverk som länkar ramar relaterade till landmärken för ansikte med vektorer. Använd sedan dessa uppgifter, systemet skapar ett generatornätverk som kartlägger landmärken i de syntetiserade videorna. Till sist, diskriminatornätverket bedömer realismen och ställningen hos genererade ramar."
Författarna beskrev "långt meta-lärande" på en stor datauppsättning av videor, och kunna rama in få- och engångsinlärning av neurala talande huvudmodeller av tidigare osynliga människor som motstridiga träningsproblem, med högkapacitetsgeneratorer och diskriminatorer.
Vem skulle egentligen använda detta system? Rapporter nämnde telenärvaro, spel för flera spelare och specialeffektsindustrin.
Ändå, Johnson och andra som lämnade in sina rapporter var inte på väg att ignorera risken för tekniska framsteg i fel händer, där de busiga kan producera fejk med dåliga avsikter.
"Sådan teknik skulle helt klart också kunna användas för att skapa djupförfalskningar, " skrev Johnson.
Så, vi kanske vill slå paus vid den tanken. Bara att författare nu så slentrianmässigt hänvisar till de "djupa falska" resultat som kommer ut av vissa artificiell intelligensprojekt. Och skribenter undrar vad detta Samsung-steg i tekniken kan betyda i deepfakes.
Jon Christian hade en överblick i Futurism . "Under de senaste åren, Vi har sett den snabba ökningen av "deepfake"-teknik som använder maskininlärning för att analysera bilder av riktiga människor – och sedan ta fram en övertygande video där de gör saker de aldrig gjort eller säger saker de aldrig har sagt."
Joan Solsman i CNET:"Den snabba utvecklingen av artificiell intelligens innebär att varje gång en forskare delar ett genombrott i deepfake-skapande, dåliga skådespelare kan börja skrapa ihop sina egna jury-riggade verktyg för att efterlikna det."
Intressant, ju mer allmänheten är medveten om AI-falsk, desto lättare kan de acceptera att vissa animationer är falska – eller inte? En tittarkommentar på videosidan:"I framtiden, utpressning är omöjligt eftersom alla vet att du enkelt kan skapa en video av vad som helst."
© 2019 Science X Network