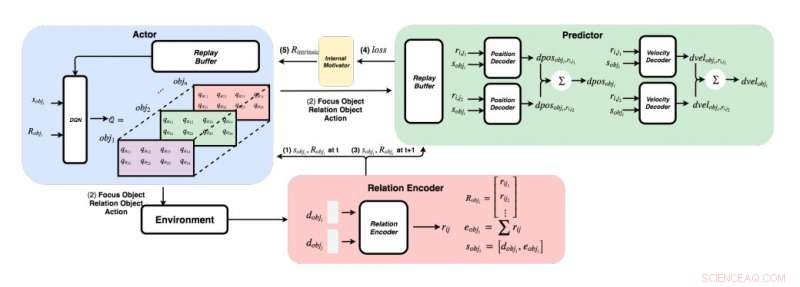
Ett detaljerat diagram över tillvägagångssättet utvecklat av forskarna. (Nederst till höger) För varje par objekt, forskarna matar in sina funktioner i en relationskodare för att få relation rij och object i’s state sobji. (Överst till vänster) Med den giriga metoden, för varje objekt, de hittar det maximala Q -värdet för att få vårt fokusobjekt, relationsobjekt, och handling. (Överst till höger) När de samlat sitt fokusobjekt och relationsobjekt, de matar sina tillstånd och alla deras relationer till sina avkodare för att förutsäga förändringen i position och förändring i hastighet. Upphovsman:Choi &Yoon.
Från deras första levnadsår, människor har den medfödda förmågan att kontinuerligt lära sig och bygga mentala modeller av världen, helt enkelt genom att observera och interagera med saker eller människor i sin omgivning. Kognitiva psykologiska studier tyder på att människor i stor utsträckning använder denna tidigare förvärvade kunskap, särskilt när de stöter på nya situationer eller när de fattar beslut.
Trots de betydande senaste framstegen inom artificiell intelligens (AI), de flesta virtuella agenter kräver fortfarande hundratals timmar av utbildning för att uppnå prestanda på mänsklig nivå i flera uppgifter, medan människor kan lära sig att slutföra dessa uppgifter på några timmar eller mindre. Nyligen genomförda studier har belyst två viktiga bidragande faktorer till människors förmåga att förvärva kunskap så snabbt - nämligen intuitiv fysik och intuitiv psykologi.
Dessa intuitionsmodeller, som har observerats hos människor från tidiga utvecklingsstadier, kan vara kärnan underlättare för framtida lärande. Baserat på denna idé, forskare vid Korea Advanced Institute of Science and Technology (KAIST) har nyligen utvecklat en inneboende belöningsnormaliseringsmetod som gör att AI -agenter kan välja åtgärder som mest förbättrar deras intuitionsmodeller. I deras papper, förpublicerad på arXiv, forskarna föreslog specifikt ett grafiskt fysiknätverk integrerat med djupförstärkande inlärning inspirerad av inlärningsbeteendet som observerats hos spädbarn.
"Föreställ dig mänskliga spädbarn i ett rum med leksaker som ligger på nåbart avstånd, "förklarar forskarna i sitt papper." De tar ständigt tag, kasta och utföra handlingar på föremål; ibland, de observerar efterdyningarna av sina handlingar, men ibland, de tappar intresset och går vidare till ett annat föremål. "Barnet som en forskares" uppfattning antyder att mänskliga spädbarn är i sig motiverade att genomföra sina egna experiment, upptäck mer information, och så småningom lära sig att skilja olika objekt och skapa rikare interna representationer av dem. "
Psykologiska studier tyder på att under de första åren av livet, människor experimenterar kontinuerligt med sin omgivning, och detta gör att de kan bilda en viktig förståelse för världen. Dessutom, när barn observerar resultat som inte uppfyller deras tidigare förväntningar, som kallas förväntningsbrott, de uppmuntras ofta att experimentera vidare för att uppnå en bättre förståelse av situationen de befinner sig i.
Teamet av forskare på KAIST försökte reproducera dessa beteenden hos AI-agenter med hjälp av ett förstärkande-lärande tillvägagångssätt. I deras studie, de introducerade först ett grafiskt fysiknätverk som kan extrahera fysiska relationer mellan objekt och förutsäga deras efterföljande beteenden i en 3D-miljö. Senare, de integrerade detta nätverk med en djupförstärkande inlärningsmodell, introducerar en teknik för normalisering av belöningsnormalisering som uppmuntrar en AI -agent att utforska och identifiera åtgärder som kontinuerligt kommer att förbättra sin intuitionsmodell.
Med hjälp av en 3D-fysikmotor, forskarna visade att deras grafiska fysiknätverk effektivt kan utläsa positioner och hastigheter för olika objekt. De fann också att deras tillvägagångssätt gjorde det möjligt för nätverket för djupförstärkning att kontinuerligt förbättra sin intuitionsmodell, uppmuntra den att interagera med objekt enbart baserat på inneboende motivation.
I en rad utvärderingar, den nya tekniken som utvecklats av detta team av forskare uppnådde anmärkningsvärd noggrannhet, med AI -agenten som utför ett större antal olika undersökande åtgärder. I framtiden, det kan informera utvecklingen av maskininlärningsverktyg som kan lära av sina tidigare erfarenheter snabbare och mer effektivt.
"Vi har testat vårt nätverk på både stationära och icke-stationära problem i olika scener med sfäriska föremål med varierande massor och radier, "förklarar forskarna i sitt papper." Vår förhoppning är att dessa förutbildade intuitionsmodeller senare ska användas som förkunskaper för andra målorienterade uppgifter som ATARI-spel eller videoförutsägelser. "
© 2019 Science X Network