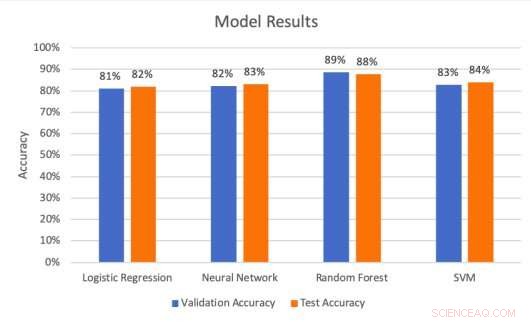
Modell Resultat på validerings- och testset. Kredit:Middlebrook &Sheik.
Två studenter och forskare vid University of San Francisco (USF) har nyligen försökt förutsäga anslagstavlor med hjälp av maskininlärningsmodeller. I deras studie, förpublicerad på arXiv, de tränade fyra modeller på låtrelaterad data extraherad med Spotify Web API, och sedan utvärderade deras prestation i att förutsäga vilka låtar som skulle bli hits.
"Jag är ett stort musikfan, och jag lyssnar på musik hela dagen; under min pendling, på jobbet, och med vänner, "Kai Middlebrook, en av forskarna som genomförde studien, berättade för TechXplore. "Förra våren, Jag började ett forskningsprojekt om automatisk musikgenreklassificering med professor David Guy Brizan vid University of San Francisco (USF). Projektet krävde en stor mängd musikdata, och populära musikstreamingtjänster har precis den typ av data jag behövde."
Medan han arbetade med ett projekt relaterat till automatisk musikgenreklassificering, Middlebrook fick reda på att Spotify tillåter utvecklare att komma åt dess musikdata. Detta uppmuntrade honom att börja experimentera med Spotify Web API för att samla in data för sina studier. När han väl avslutat forskningen relaterad till genreklassificering, dock, han lade API åt sidan för en tid.
"Några månader senare, min vän Kian, som också är datavetare och älskar musik, och jag hade en diskussion om musik, " sa Middlebrook. "Vid någon tidpunkt under konversationen, den allmänt hållna idén att "alla hitlåtar låter likadant" togs upp. Vi trodde inte nödvändigtvis att det var sant, men idén fick oss att undra:Tänk om hitlåtar delar vissa likheter? Det verkade möjligt, så Kian och jag bestämde oss för att undersöka vidare."
Middlebrook och Sheik, som tidigare hade samarbetat i genreklassificeringsprojektet, beslutade att genomföra en ytterligare utredning med hjälp av data extraherad från Spotify. Detta nya projekt skulle också vara den sista uppgiften för deras data mining-kurs på USF.
"Vi samarbetade i flera andra projekt för olika kurser, så det var vettigt att hålla ihop, "Kian Sheik, en annan forskare involverad i studien, berättade för TechXplore. "Lil Nas X:s hit "Old Town Road" hade precis kommit från ingenstans, och var på toppen av Billboard Hot 100. Kai och jag undrade om en dator kunde ha förutspått hans uppgång, eller om det bara var en hitsingel som kom från vänster fält. Det som började som ett enkelt slutprojekt slutade med att vi uttömde alla toppmoderna övervakade inlärningsmodeller på ett stort dataset för att svara på en enkel fråga:Kommer den här låten att bli en hit?"
I deras studie, Middlebrook och Sheik använde Spotify Web API för att samla in data för 1,8 miljoner låtar, som inkluderade funktioner som en låts tempo, nyckel, valens, etc. De samlade sedan också in cirka 30 års data från Billboard Hot 100-diagrammet.
"Vårt mål var att se om hitlåtar delade liknande egenskaper, och i så fall, om dessa funktioner skulle kunna användas för att förutsäga vilka låtar som skulle bli hits i framtiden, sa Middlebrook.
Forskarna tränade och utvärderade fyra olika modeller:en logistisk regression, ett neuralt nätverk, en stödvektormaskin (SVM) och en slumpmässig skogsarkitektur (RF). Under träning, dessa modeller analyserade en mängd olika låtfunktioner, inklusive tempo, nyckel, valens, energi, akustik, dansbarhet och ljudstyrka.
"När man får en sång, våra modeller skulle märka det med antingen en etta eller en nolla, Middlebrook förklarade. "En låt märkt med ett betyder att modellen förutspår att låten var en hit. En låt märkt med en nolla betyder att modellen förutspår att låten inte var en hit."
Den logistiska regressionsmodellen som tränats av forskarna antar att sångdata linjärt kan delas upp i två kategorier:träffar och icke-träffar. Modellen tilldelar en vikt till varje låtfunktion, och använder sedan dessa vikter för att förutsäga om en låt faller i kategorin "hit" eller "icke-hit".
Logistiska regressionsmodeller har två viktiga fördelar:tolkningsbarhet och hastighet. Med andra ord, denna typ av arkitektur gör det lättare att tolka sambandet mellan förklarande variabler (d.v.s. låtfunktionerna) och svarsvariabeln (dvs. träffad eller icke-träff), och den kan också tränas relativt snabbt.
Den andra modellen som forskarna tränade var en RF-arkitektur. Denna modell fungerar genom att kombinera en stor mängd byggstenar som kallas beslutsträd.
"Väsentligen, ett beslutsträd kan ses som en modell som använder en serie ja/nej-frågor för att separera data, " sade Middlebrook. "De är tolkbara, men benägen att överanpassa data. Overfitting innebär att en modell memorerar träningsdatan genom att passa den för tätt. Problemet med överanpassning är att modellen kanske inte lär sig det faktiska förhållandet mellan låtfunktioner och låtpopularitet eftersom data ofta innehåller irrelevant brus."
För att undvika problemet med övermontering, den slumpmässiga skogsmodellen som används av Middlebrook och Sheik kombinerar hundratusentals beslutsträd, som var och en tränas på olika delmängder av träningsdata och olika delmängder av sångfunktionerna. Modellen gör sedan en förutsägelse (dvs. bestämmer om en låt är en hit eller icke-hit) genom att beräkna ett genomsnitt av förutsägelsen för varje träd och kombinera dessa resultat.
"I vårt användningsfall, fördelen med den slumpmässiga skogsmodellen är dess flexibilitet, " sade Middlebrook. "Den är mer flexibel än en linjär modell (t.ex. logistisk regression)."
Den tredje och fjärde modellen som utbildats av forskarna, nämligen SVM och neurala nätverksarkitekturer, är båda icke-linjära och är därför svårare att tolka. SVM-modellen fungerar genom att försöka hitta det "hyperplan" som bäst separerar data i de två kategorierna (dvs. träffar eller icke-träffar). Den neurala nätverksarkitekturen, å andra sidan, använder ett dolt lager med tio filter för att lära av sångdata.
Bland de fyra modellerna som används av Middlebrook och Sheik, den logistiska regressionsmodellen är lättast att tolka, medan det neurala nätverksbaserade är det svåraste. De andra två modellerna faller någonstans i mitten.
"Rent generellt, dessa modeller kommer att förutsäga baserat på begränsningar som de utvecklar genom utbildning, " Sade Sheik. "Varje modell har tränats på samma uppsättning av ljudklassificerare. Resultatet av modellerna testas mot historisk sanning från Billboard API, om det givna spåret någonsin har dykt upp på Billboard Hot 100-listan. Vi använde en flotta av datorer på USF för att göra siffrorna och efter ett par veckors ren beräkning, vi hade beräknat de optimala parametrarna för varje modell."
Forskarna genomförde en serie utvärderingar för att testa hur väl de fyra modellerna kunde förutsäga anslagstavlor. De fann att SVM-arkitekturen uppnådde den högsta precisionsgraden (99,53 procent), medan den slumpmässiga skogsmodellen uppnådde den bästa noggrannhetsgraden (88 procent) och återkallningsgraden (85,51 procent).
"Recall uttrycker förmågan att hitta alla relevanta instanser i en datauppsättning, medan precision uttrycker hur stor andel av data som vår modell säger var relevant som faktiskt var relevant, " förklarade Middlebrook. "Med andra ord, minns berätta hur sannolikt vår modell är att exakt förutsäga en faktisk träff som en träff. Precision berättar för oss hur stor andel av förutspådda träffar som faktiskt var träffar."
Enligt forskarna, om skivbolag skulle använda någon av dessa modeller för att förutsäga vilka låtar som kommer att bli mer framgångsrika, de skulle förmodligen välja en modell med hög precision än en med hög noggrannhet. Detta beror på att en modell som uppnår hög precision tar mindre risk, eftersom det är mindre troligt att förutsäga att en icke-framgångsrik låt kommer att bli en hit.
"Skivbolag har begränsade resurser, " sa Middlebrook. "Om de häller dessa resurser i en låt som modellen förutspår kommer att bli en hit och den låten blir aldrig en, då kan etiketten förlora mycket pengar. Så om ett skivbolag vill ta lite mer risk med möjligheten att släppa fler hitskivor, de kanske väljer att använda vår slumpmässiga skogsmodell. Å andra sidan, om ett skivbolag vill ta mindre risker samtidigt som de släpper några hits, de borde använda vår SVM-modell."
Middlebrook och Sheik fann att att förutsäga en billboardhit baserat på funktionerna i en låts ljud är, faktiskt, möjlig. I sin framtida forskning, forskarna planerar att undersöka andra faktorer som kan bidra till sångframgång, som närvaro på sociala medier, konstnärsupplevelse, och etikettpåverkan.
"Vi kan föreställa oss en värld där skivbolag som ständigt letar efter nya talanger översvämmas av mix-tapes och demos från "nästa heta artister, "" sa Sheik. "Människor har bara så mycket tid att lyssna på musik med mänskliga öron, så "konstgjorda öron, "som våra algoritmer, kan göra det möjligt för skivbolag att träna en modell för den typ av ljud de söker och avsevärt minska antalet låtar de själva måste överväga."
Klassificerare som de som utvecklats av Middlebrook och Sheik kan i slutändan hjälpa skivbolag att bestämma vilka låtar de ska investera i. Även om idén att använda maskininlärning för att skumma igenom demos kan vara av intresse för musikindustrin, Sheik varnar för att det också kan få oönskade konsekvenser.
"Även om detta kan vara en lämplig framtid, utsikterna till en ökända "huggkloss" som konstnärer måste mäta sig med har potential att bli en ekokammare, eller en situation där ny musik måste låta som gammal musik för att kunna släppas på radio, " sa Sheik. "Innehållsskapare på plattformar som YouTube, som också använder algoritmer för att avgöra vilka videor som ska visas för massorna, har förnekat fallgroparna med att tvinga konstnärer att arbeta för en maskin."
Enligt Sheik, om företag och producenter börjar använda algoritmer för att fatta konstnärliga beslut, dessa modeller bör utformas på ett sätt som inte hämmar konstens framsteg. Arkitekturen som utvecklats av de två forskarna vid USF, dock, ännu inte kan uppnå detta.
"Nyhetsbias och andra oortodoxa egenskaper kommer att behöva introduceras och uppfinnas för att musiken som helhet inte ska närma sig en kulturell singularitet i händerna på ändamålsenlighet, " avslutade Sheik.
© 2019 Science X Network