Oier Mees visar hur det nya tillvägagångssättet fungerar. Kredit:Mees et al.
Med fler robotar nu på väg in i ett antal inställningar, forskare försöker göra sin interaktion med människor så smidig och naturlig som möjligt. Tränar robotar att reagera omedelbart på talade instruktioner, som "ta upp glaset, flytta den till höger, " etc., skulle vara idealiskt i många situationer, eftersom det i slutändan skulle möjliggöra mer direkta och intuitiva interaktioner mellan människa och robot. Dock, det här är inte alltid lätt, eftersom det kräver att roboten förstår användarens instruktioner, men också att veta hur man flyttar objekt i enlighet med specifika rumsliga relationer.
Forskare vid universitetet i Freiburg i Tyskland har nyligen utarbetat ett nytt tillvägagångssätt för att lära robotar hur man flyttar runt föremål enligt instruktioner från mänskliga användare, som fungerar genom att klassificera "hallucinerade" scenrepresentationer. Deras papper, förpublicerad på arXiv, kommer att presenteras på IEEE International Conference on Robotics and Automation (ICRA) i Paris, denna juni.
"I vårt arbete, vi koncentrerar oss på instruktioner för placering av relationsobjekt, som "ställ muggen till höger om lådan" eller "lägg den gula leksaken ovanpå lådan, "Oier Mees, en av forskarna som genomförde studien, berättade TechXplore. "Att göra så, roboten måste resonera om var den ska placera muggen i förhållande till lådan eller något annat referensobjekt för att återskapa den rumsliga relationen som beskrivs av en användare."
Att träna robotar att förstå rumsliga relationer och flytta objekt därefter kan vara mycket svårt, eftersom en användares instruktioner vanligtvis inte avgränsar en specifik plats inom en större scen som observeras av roboten. Med andra ord, om en mänsklig användare säger "placera muggen till vänster om klockan, "hur långt kvar från klockan ska roboten placera muggen och var är den exakta gränsen mellan olika riktningar (t.ex. höger, vänster, framför, Bakom, etc.)?
"På grund av denna inneboende tvetydighet, det finns heller ingen grundsanning eller "korrekt" data som kan användas för att lära sig modellera rumsliga relationer, ", sade Mees. "Vi tar itu med problemet med otillgängligheten av pixelvisa annoteringar om rumsliga relationer utifrån perspektivet av hjälpinlärning."
Huvudtanken bakom tillvägagångssättet som utarbetats av Mees och hans kollegor är att när de ges två objekt och en bild som representerar sammanhanget där de finns, det är lättare att bestämma det rumsliga förhållandet mellan dem. Detta gör att robotarna kan upptäcka om ett objekt är till vänster om det andra, ovanpå det, framför det, etc.
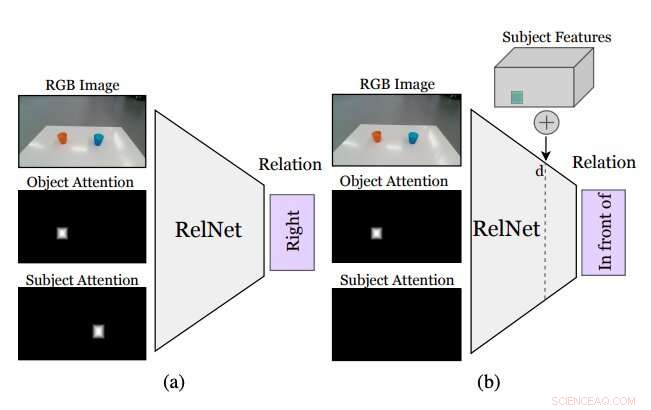
Figur som sammanfattar hur forskarnas tillvägagångssätt fungerar. En extra CNN, kallas RelNet, är tränad att förutsäga rumsliga relationer givet ingångsbilden och två uppmärksamhetsmasker som hänvisar till två objekt som bildar en relation. (a) efter träning, nätverket kan "luras" att klassificera hallucinerade scener genom att (b) implementera högnivåfunktioner hos objekt på olika rumsliga platser. Kredit:Mees et al.
Även om identifiering av ett rumsligt förhållande mellan två objekt inte specificerar var objekten ska placeras för att reproducera den relationen, Att infoga andra objekt i scenen kan tillåta roboten att sluta sig till en fördelning över flera rumsliga relationer. Lägga till dessa obefintliga (dvs. hallucinerade) föremål mot vad roboten ser bör göra det möjligt för den att utvärdera hur scenen skulle se ut om den utförde en viss handling (d.v.s. placera ett av föremålen på en specifik plats på bordet eller ytan framför det).
"Vanligast, Att "klistra in" objekt realistiskt i en bild kräver antingen tillgång till 3D-modeller och silhuetter eller noggrant design av optimeringsproceduren för generativa motstridiga nätverk (GAN), sade Mees. Dessutom, Att naivt "klistra in" objektmasker i bilder skapar subtila pixelartefakter som leder till märkbart olika funktioner och till att träningen felaktigt fokuserar på dessa avvikelser. Vi tar ett annat tillvägagångssätt och implanterar högnivåegenskaper hos objekt i särdragskartor över scenen som genereras av ett konvolutionellt neuralt nätverk för att hallucinera scenrepresentationer, som sedan klassificeras som en hjälpuppgift för att få inlärningssignalen."
Innan man tränar ett konvolutionellt neuralt nätverk (CNN) för att lära sig rumsliga relationer baserade på hallucinerade objekt, forskarna var tvungna att se till att den kunde klassificera relationer mellan enskilda par av objekt baserat på en enda bild. Senare, de "lurade" sitt nätverk, dubbad RelNet, till att klassificera "hallucinerade" scener genom att implantera egenskaper på hög nivå av föremål på olika rumsliga platser.
"Vårt tillvägagångssätt tillåter en robot att följa naturliga språkinstruktioner som ges av mänskliga användare med minimal datainsamling eller heuristik, ", sa Mees. "Alla skulle vilja ha en servicerobot hemma som kan utföra uppgifter genom att förstå instruktioner på naturliga språk. Detta är ett första steg för att göra det möjligt för en robot att bättre förstå innebörden av vanliga rumsliga prepositioner."
Den mest existerande metoden för att träna robotar för att flytta objekt använder information om objekten "3D-former för att modellera parvisa rumsliga relationer. En viktig begränsning för dessa tekniker är att de ofta kräver ytterligare tekniska komponenter, såsom spårningssystem som kan spåra olika föremåls rörelser. Tillvägagångssättet som föreslagits av Mees och hans kollegor, å andra sidan, kräver inga ytterligare verktyg, eftersom den inte är baserad på 3D-seendetekniker.
Forskarna utvärderade sin metod i en serie experiment som involverade riktiga mänskliga användare och robotar. Resultaten av dessa tester var mycket lovande, eftersom deras metod tillät robotar att effektivt identifiera de bästa strategierna för att placera objekt på ett bord i enlighet med de rumsliga relationerna som beskrivs av en mänsklig användares talade instruktioner.
"Vårt nya tillvägagångssätt för hallucinerande scenrepresentationer kan också ha flera tillämpningar inom robotik och datorseende, eftersom robotar ofta behöver kunna uppskatta hur bra ett framtida tillstånd kan vara för att kunna resonera över de åtgärder de behöver vidta, "Mees sa." Det kan också användas för att förbättra prestanda för många neurala nätverk, såsom objektdetekteringsnätverk, genom att använda hallucinerade scenrepresentationer som en form av dataförstoring. "
Mees och hans kollegor kan vi modellera en uppsättning rumsliga prepositioner för naturligt språk (t.ex. höger, vänster, ovanpå, etc.) tillförlitligt och utan att använda 3D-visionverktyg. I framtiden, det tillvägagångssätt som presenterades i deras studie skulle kunna användas för att förbättra kapaciteten hos befintliga robotar, så att de kan slutföra enkla objektförskjutningsuppgifter mer effektivt samtidigt som de följer en mänsklig användares talade instruktioner.
Under tiden, deras papper skulle kunna informera om utvecklingen av liknande tekniker för att förbättra interaktioner mellan människor och robotar under andra objektmanipuleringsuppgifter. Om den kombineras med hjälpinlärningsmetoder, tillvägagångssättet som utvecklats av Mees och hans kollegor kan också minska kostnaderna och ansträngningarna för att sammanställa datauppsättningar för robotforskning, eftersom det möjliggör förutsägelse av pixelvisa sannolikheter utan att kräva stora annoterade datamängder.
"Vi känner att detta är ett lovande första steg mot att möjliggöra en delad förståelse mellan människor och robotar, ", avslutade Mees. "I framtiden, vi vill utöka vårt tillvägagångssätt till att inkludera förståelse för hänvisande uttryck, för att utveckla ett pick-and-place-system som följer naturliga språkinstruktioner. "
© 2020 Science X Network