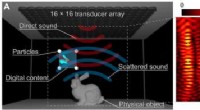
Exempel på makroplaceringsalgoritmen som föreslagits av Google. Kredit:Science China Press
Elektronisk designautomation (EDA) eller datorstödd design (CAD) är en kategori av mjukvaruverktyg för att designa elektroniska system, såsom integrerade kretsar (IC). Med EDA-verktyg kan designers avsluta designflödet av mycket storskaliga integrerade (VLSI)-chips med miljarder transistorer. EDA-verktyg är avgörande för modern VLSI-design på grund av den stora skalan och den höga komplexiteten hos elektroniska system.
Nyligen, med uppsvinget av artificiell intelligens (AI) algoritmer, utforskar EDA-gemenskapen aktivt AI för IC-tekniker för design av avancerade chips. Många studier har utforskat maskininlärning (ML)-baserade tekniker för stegvisa prediktionsuppgifter i designflödet för att uppnå snabbare designkonvergens. Till exempel publicerade Google en artikel i Nature 2021 med titeln "A graphplacement methodology for fast chip design", som utnyttjar förstärkningsinlärning (RL) för att placera makron i en chipdesign.
Grundidén är att betrakta chiplayouten som en Go-bräda, medan varje makro som en sten. På så sätt kan en RL-agent förtränas med 10 000 interna designprover och lära sig att placera ett makro i taget. Genom att finjustera agenten på varje design i cirka 6 timmar kan den överträffa prestandan för konventionella EDA-verktyg på Googles TPU-chips och uppnå bättre prestanda, kraft och area (PPA).
Det kan ses att "AI for EDA" aktivt utforskas inom designautomationsgemenskapen. Även om att bygga ML-modeller vanligtvis kräver en stor mängd data, kan de flesta studier bara generera små interna datauppsättningar för validering, på grund av bristen på stora offentliga datauppsättningar och svårigheten att generera data. För detta ändamål är en datauppsättning med öppen källkod dedikerad till ML-uppgifter i EDA angelägen.
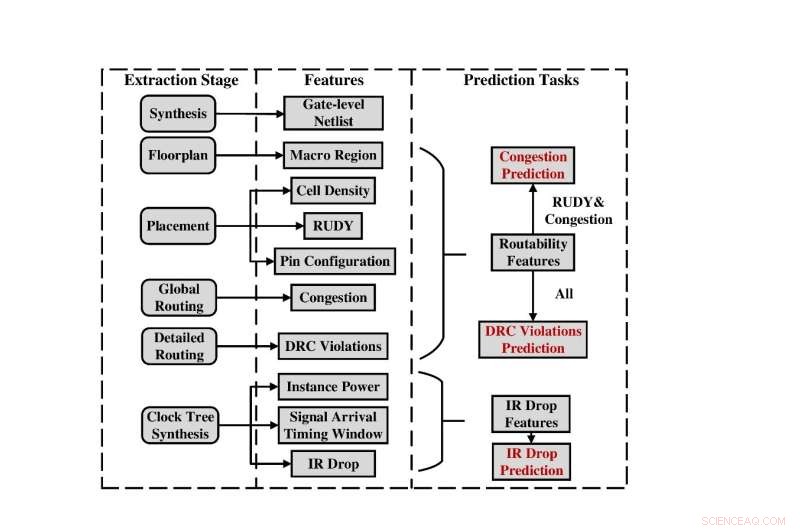
Övergripande flöde för datainsamling och funktionsextraktion. Kredit:Science China Press
För att ta itu med detta problem har forskargruppen från Peking University släppt den första datauppsättningen med öppen källkod, kallad CircuitNet, som är dedikerad till AI för IC-applikationer i VLSI CAD. Datauppsättningen består av över 10 000 sampel och 54 syntetiserade kretsnätlistor från sex RISC-V-designer med öppen källkod, tillhandahåller holistiskt stöd för prediktionsuppgifter i flera steg och stöder uppgifter inklusive förutsägelse av routingstockning, förutsägelse av överträdelse av designregel (DRC) och IR fallförutsägelse. De huvudsakliga egenskaperna hos CircuitNet kan sammanfattas enligt följande:
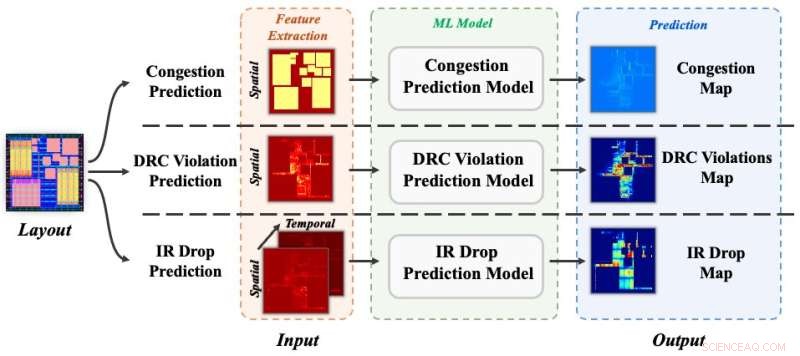
Tre stegvis förutsägelseuppgifter:trafikstockning, DRC-överträdelser och IR-fall. Kredit:Science China Press
För att utvärdera effektiviteten av CircuitNet, validerar författarna datamängden genom experiment på tre förutsägelseuppgifter:trafikstockning, DRC-överträdelser och IR-fall. Varje experiment tar en metod från nya studier och utvärderar dess resultat på CircuitNet med samma utvärderingsmått som de ursprungliga studierna. Sammantaget överensstämmer resultaten med originalpublikationerna, vilket visar effektiviteten hos CircuitNet. En detaljerad handledning om experimentinställningen finns tillgänglig på GitHub. I framtiden planerar författarna att införliva fler dataprover med storskalig design i avancerade teknologinoder för att förbättra datauppsättningens skala och mångfald.
Forskningen publicerades i Science China Information Sciences . + Utforska vidare