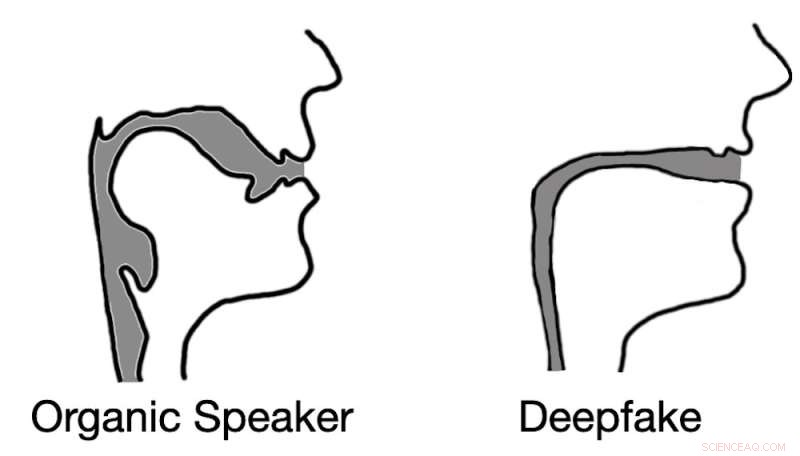
Djupt ljud resulterar ofta i rekonstruktioner av röstkanalen som liknar sugrör snarare än biologiska sångkanaler. Kredit:Logan Blue et al., CC BY-ND
Föreställ dig följande scenario. En telefon ringer. En kontorsanställd svarar på det och hör hans chef, i panik, berätta för honom att hon glömde att överföra pengar till den nya entreprenören innan hon åkte för dagen och behöver honom för att göra det. Hon ger honom banköverföringsinformationen och med pengarna överförda har krisen avvärjts.
Arbetaren sätter sig tillbaka i stolen, tar ett djupt andetag och ser på när hans chef går in genom dörren. Rösten i andra änden av samtalet var inte hans chef. Det var faktiskt inte ens en människa. Rösten han hörde var en ljuddeepfake, ett maskingenererat ljudprov designat för att låta precis som hans chef.
Attacker som denna med inspelat ljud har redan inträffat, och konversationsljud är kanske inte långt borta.
Deepfakes, både ljud och video, har bara varit möjliga med utvecklingen av sofistikerad maskininlärningsteknik under de senaste åren. Deepfakes har fört med sig en ny nivå av osäkerhet kring digitala medier. För att upptäcka djupförfalskningar har många forskare vänt sig till att analysera visuella artefakter – små fel och inkonsekvenser – som finns i videoförfalskningar.
Deepfakes för ljud utgör potentiellt ett ännu större hot, eftersom människor ofta kommunicerar verbalt utan video – till exempel via telefonsamtal, radio och röstinspelningar. Denna kommunikation med enbart röst utökar kraftigt möjligheterna för angripare att använda deepfakes.
För att upptäcka djupa ljudförfalskningar har vi och våra forskarkollegor vid University of Florida utvecklat en teknik som mäter de akustiska och flytande dynamiska skillnaderna mellan röstprover skapade organiskt av mänskliga högtalare och de som genereras syntetiskt av datorer.
Ekologiska kontra syntetiska röster
Människor vokaliserar genom att tvinga luft över de olika strukturerna i stämkanalen, inklusive stämband, tunga och läppar. Genom att omarrangera dessa strukturer ändrar du de akustiska egenskaperna hos ditt röstsystem, vilket gör att du kan skapa över 200 distinkta ljud eller fonem. Men mänsklig anatomi begränsar i grunden det akustiska beteendet hos dessa olika fonem, vilket resulterar i ett relativt litet utbud av korrekta ljud för varje.
Däremot skapas ljuddeepfakes genom att först låta en dator lyssna på ljudinspelningar av en riktad offerhögtalare. Beroende på vilken teknik som används kan datorn behöva lyssna på så lite som 10 till 20 sekunders ljud. Detta ljud används för att extrahera nyckelinformation om de unika aspekterna av offrets röst.
Angriparen väljer en fras för deepfake att tala och sedan, med hjälp av en modifierad text-till-tal-algoritm, genererar han ett ljudprov som låter som att offret säger den valda frasen. Den här processen att skapa ett enda djupt falskt ljudprov kan utföras på några sekunder, vilket potentiellt ger angripare tillräckligt med flexibilitet för att använda den djupfalska rösten i en konversation.
Deepfakes upptäcker ljud
Det första steget i att skilja tal som produceras av människor från tal som genereras av deepfakes är att förstå hur man akustiskt modellerar röstkanalen. Lyckligtvis har forskare tekniker för att uppskatta hur någon - eller någon varelse som en dinosaurie - skulle låta baserat på anatomiska mätningar av dess röstkanal.
Vi gjorde tvärtom. Genom att invertera många av samma tekniker kunde vi extrahera en approximation av en talares röstkanal under ett talsegment. Detta gjorde det möjligt för oss att effektivt titta in i anatomin hos talaren som skapade ljudprovet.
Härifrån antog vi att djupfalska ljudprover inte skulle kunna begränsas av samma anatomiska begränsningar som människor har. Med andra ord, analysen av djupförfalskade ljudprover simulerade röstkanalformer som inte finns hos människor.
Våra testresultat bekräftade inte bara vår hypotes utan avslöjade något intressant. När vi extraherade uppskattningar av röstkanalen från deepfake-ljud, fann vi att uppskattningarna ofta var komiskt felaktiga. Till exempel var det vanligt att deepfake-ljud resulterade i sångkanaler med samma relativa diameter och konsistens som ett sugrör, i motsats till mänskliga sångkanaler, som är mycket bredare och mer varierande i form.
Denna insikt visar att deepfake ljud, även när det övertygar för mänskliga lyssnare, är långt ifrån omöjligt att skilja från mänskligt genererat tal. Genom att uppskatta anatomin som är ansvarig för att skapa det observerade talet, är det möjligt att identifiera om ljudet genererades av en person eller en dator.
Varför detta är viktigt
Dagens värld definieras av digitalt utbyte av media och information. Allt från nyheter till underhållning till samtal med nära och kära sker vanligtvis via digitala utbyten. Även i sin linda undergräver djupfalsk video och ljud det förtroende som människor har för dessa utbyten, vilket effektivt begränsar deras användbarhet.
Om den digitala världen ska förbli en kritisk resurs för information i människors liv är effektiva och säkra tekniker för att fastställa källan till ett ljudprov avgörande. + Utforska vidare
Den här artikeln är återpublicerad från The Conversation under en Creative Commons-licens. Läs originalartikeln. 














