Kredit:York University
Deep convolutional neural networks (DCNN) ser inte objekt som människor gör – med hjälp av konfigurerad formuppfattning – och det kan vara farligt i verkliga AI-tillämpningar, säger professor James Elder, medförfattare till en studie från York University som publicerades idag.
Publicerad i tidskriften Cell Press iScience , Modeller för djupinlärning misslyckas med att fånga den konfigurerade karaktären av mänsklig formuppfattning är en samarbetsstudie av Elder, som innehar York Research Chair in Human and Computer Vision och är meddirektör för Yorks Center for AI &Society, och assisterande psykologiprofessor Nicholas Baker vid Loyola College i Chicago, tidigare VISTA postdoktor vid York.
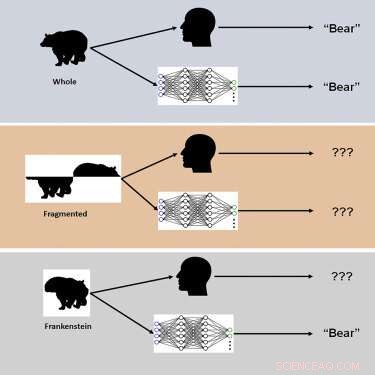
Studien använde nya visuella stimuli kallade "Frankensteins" för att utforska hur den mänskliga hjärnan och DCNN:er bearbetar holistiska, konfigurerade objektegenskaper.
"Frankensteins är helt enkelt föremål som har tagits isär och satts ihop på fel sätt", säger Elder. "Som ett resultat har de alla rätt lokala funktioner, men på fel platser."
Utredarna fann att även om det mänskliga visuella systemet är förvirrat av Frankensteins, är DCNN inte det – vilket avslöjar en okänslighet för konfigurerade objektegenskaper.
"Våra resultat förklarar varför djupa AI-modeller misslyckas under vissa förhållanden och pekar på behovet av att överväga uppgifter bortom objektigenkänning för att förstå visuell bearbetning i hjärnan", säger Elder. "Dessa djupa modeller tenderar att ta "genvägar" när de löser komplexa igenkänningsuppgifter. Även om dessa genvägar kan fungera i många fall, kan de vara farliga i några av de verkliga AI-applikationerna som vi för närvarande arbetar med med vår industri och regeringspartners, " Äldste påpekar.
En sådan applikation är trafiksäkerhetssystem:"Föremålen i en trafikerad trafikplats - fordonen, cyklarna och fotgängarna - hindrar varandra och kommer fram till en förares öga som ett virrvarr av frånkopplade fragment", förklarar Elder. "Hjärnan behöver gruppera dessa fragment på rätt sätt för att identifiera de korrekta kategorierna och platserna för objekten. Ett AI-system för trafiksäkerhetsövervakning som bara kan uppfatta fragmenten individuellt kommer att misslyckas med denna uppgift, vilket potentiellt missförstår risker för utsatta trafikanter. "
Enligt forskarna ledde modifieringar av träning och arkitektur som syftade till att göra nätverk mer hjärnliknande inte till konfigurerad bearbetning, och inget av nätverken kunde korrekt förutsäga försök för försök mänskliga objektbedömningar. "Vi spekulerar i att för att matcha mänsklig konfigurationskänslighet måste nätverk tränas för att lösa ett bredare utbud av objektuppgifter bortom kategoriigenkänning", konstaterar Elder. + Utforska vidare