Föreslagna trådar av mörk materia som omger Jupiter kan vara en del av de mystiska 95 procent av universums massenergi. Upphovsman:NASA/JPL-Caltech
Det mesta av universum är mörkt, med mörk materia och mörk energi som utgör mer än 95 procent av dess massenergi. Ändå vet vi lite om mörk materia och energi. För att hitta svar, forskare kör stora fysiska experiment med hög energi. Analys av resultaten kräver högpresterande datorer-ibland balanserade med industriella trender.
Efter fyra års datorkörning för Large Hadron Collider CMS -experimentet på CERN nära Genève, Schweiz - en del av arbetet som avslöjade Higgs -bosonen - Oliver Gutsche, en forskare vid Department of Energy's (DOE) Fermi National Accelerator Laboratory, vände sig till sökandet efter mörk materia. "Higgs -bosonen hade förutsetts, och vi visste ungefär var vi skulle leta, "säger han." Med mörk materia, vi vet inte vad vi letar efter. "
För att lära dig om mörk materia, Gutsche behöver mer data. När den informationen är tillgänglig, fysiker måste gruva det. De utforskar beräkningsverktyg för jobbet, inklusive Apache Spark-programvara med öppen källkod.
I sökandet efter mörk materia, fysiker studerar resultat från kolliderande partiklar. "Detta är trivialt att parallellisera, "bryta jobbet i bitar för att få svar snabbare, Gutsche förklarar. "Två datorer kan varje bearbeta en kollision, "vilket innebär att forskare kan använda ett datorgaller för att analysera data.
Mycket av arbetet inom högenergifysik, fastän, beror på mjukvara som forskarna utvecklar. "Om våra doktorander och postdoktor bara känner till våra egna verktyg, då får de problem om de går till industrin, "där sådan programvara inte är tillgänglig, Gutsche anteckningar. "Så jag började titta på Spark."
Spark är ett datareduktionsverktyg för ostrukturerade textfiler. Det skapar en utmaning-tillgång till fysikdata med hög energi, som är i ett objektorienterat format. Fermilabs datavetenskapliga forskare Saba Sehrish och Jim Kowalkowski tar sig an uppgiften.
Spark gav löfte från början, med några särskilt intressanta funktioner, Säger Sehrish. "En var i minnet, storskalig distribuerad bearbetning "genom gränssnitt på hög nivå, vilket gör det enkelt att använda. "Du vill inte att forskare ska oroa sig för hur man distribuerar data och skriver parallellkod, säger hon. Spark tar hand om det.
En annan attraktiv egenskap:Spark är en forskningsplattform som stöds vid National Energy Research Scientific Computing Center (NERSC), en användaranläggning för DOE Office of Science vid DOE:s Lawrence Berkeley National Laboratory. "Detta ger oss ett supportteam som kan ställa in det, "Säger Kowalkowski. Datavetare som Sehrish och Kowalkowski kan lägga till funktioner, men för att få den underliggande koden att fungera så effektivt som möjligt krävs Spark -specialister, några av dem arbetar på NERSC.
Kowalkowski sammanfattar Sparks önskvärda funktioner som "automatiserad skalning, automatiserad parallellism och en rimlig programmeringsmodell. "
Kortfattat, han och Sehrish vill bygga ett system som gör det möjligt för forskare att köra en analys som fungerar extremt bra på stora maskiner utan komplikationer och genom ett enkelt användargränssnitt.
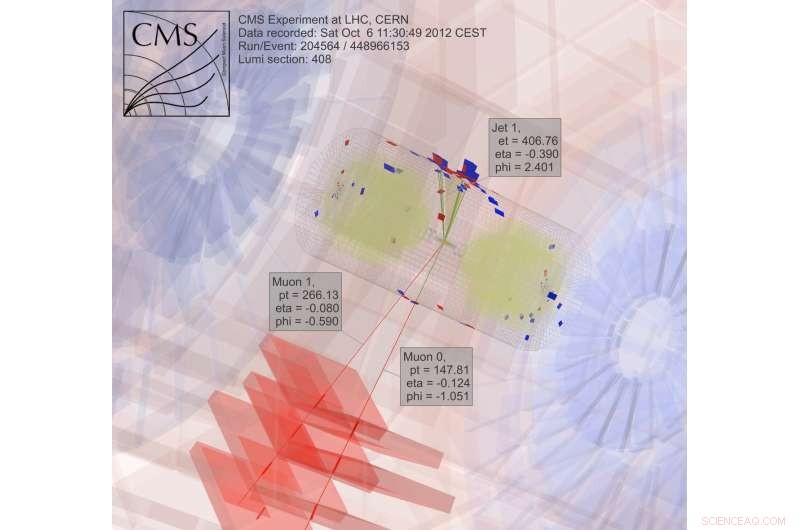
För att söka efter mörk materia, forskare samlar in och analyserar resultat från kolliderande partiklar, en extremt beräkningsmässigt intensiv process. Upphovsman:CMS CERN
Bara att vara enkel att använda, fastän, är inte tillräckligt när det gäller data från högenergifysik. Spark verkar till viss del uppfylla både användarvänlighet och prestationsmål. Forskare undersöker fortfarande vissa aspekter av dess prestanda för högenergifysikapplikationer, men datavetare kan inte ha allt. "Det finns en kompromiss, "Sehrish -stater." När du letar efter mer prestanda, du får inte användarvänlighet. "
Fermilab-forskarna valde Spark som ett första val för att utforska stordatavetenskap, och mörk materia är bara den första applikationen som testas. "Vi behöver flera fall för verklig användning för att förstå möjligheten att använda Spark för en analysuppgift, "Säger Sehrish. Med forskare som Gutsche på Fermilab, mörk materia var ett bra ställe att börja. Sehrish och Kowalkowski vill förenkla livet för forskare som kör analysen. "Vi arbetar med forskare för att förstå deras data och arbeta med deras analys, "Sehrish säger." Då kan vi hjälpa dem att bättre organisera datamängder, bättre organisera analysuppgifter. "
Som ett första steg i processen, Sehrish och Kowalkowski måste hämta data från fysiska experiment med hög energi till Spark. Anteckningar Kowalkowski, "Du har petabyte med data i specifika experimentella format som du måste göra till något användbart för en annan plattform."
Startdata för implementering av mörk materia är formaterade för plattformar med hög kapacitet, men Spark hanterar inte den konfigurationen. Så programvara måste läsa det ursprungliga dataformatet och konvertera det till något som fungerar bra med Spark.
Genom att göra detta, Sehrish förklarar, "Du måste överväga varje beslut i varje steg, för hur du strukturerar data, hur du läser in det i minnet och designar och implementerar operationer för hög prestanda hänger ihop. "
Var och en av dessa datahanteringssteg påverkar Sparks prestanda. Även om det är för tidigt att säga hur mycket prestanda som kan dras från Spark när man analyserar data om mörk materia, Sehrish och Kowalkowski ser att Spark kan tillhandahålla användarvänlig kod som gör det möjligt för högenergifysikforskare att starta ett jobb på hundratusentals kärnor. "Spark är bra i det avseendet, "Sehrish säger." Vi har också sett bra skalning - inte slösat bort datorresurser när vi ökar datamängden och antalet noder. "
Ingen vet om detta kommer att vara ett livskraftigt tillvägagångssätt förrän fastställande av Sparks topprestanda för dessa applikationer. "Huvudnyckeln, "Kowalkowski säger, "är att vi ännu inte är övertygade om att detta är tekniken för att gå vidare."
Faktiskt, Spark själv förändras. Dess omfattande användning av öppen källkod skapar en konstant och snabb utvecklingscykel. Så Sehrish och Kowalkowski måste behålla sin kod med Sparks nya funktioner.
"Den ständiga tillväxtcykeln med Spark är kostnaden för att arbeta med avancerad teknik och något med många utvecklingsintressen, "Säger Sehrish.
Det kan dröja några år innan Sehrish och Kowalkowski fattar ett beslut om Spark. Att konvertera mjukvara som skapats för datorer med hög genomströmning till bra högpresterande datorverktyg som är enkla att använda kräver finjustering och teamarbete mellan experimentella och beräknade forskare. Eller, Du kanske säger, det tar mer än ett skott i mörkret.