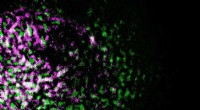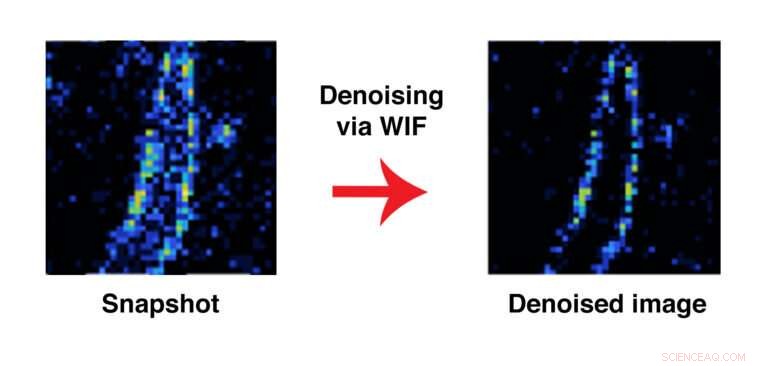
Forskare från McKelvey School of Engineering har utvecklat en beräkningsmetod som gör att de inte kan avgöra om en hel bildbild är korrekt, men om någon given punkt på bilden är sannolik, baserat på antagandena inbyggda i modellen. Här, en bild av en amyloidfibril före och efter applicering av metoden känd som WIF. Upphovsman:Lew Lab
En mäklare skickar en blivande husköpare ett suddigt fotografi av ett hus taget tvärs över gatan. Hemköparen kan jämföra det med den riktiga saken - titta på bilden, titta sedan på det riktiga huset - och se att karnappfönstret faktiskt är två fönster nära varandra, blommorna framför är av plast och det som såg ut som en dörr är faktiskt ett hål i väggen.
Tänk om du inte tittar på en bild av ett hus, men något väldigt litet - som ett protein? Det finns inget sätt att se det utan en specialiserad enhet så det finns inget att döma bilden mot, ingen grundlig sanning, 'som det heter. Det finns inte mycket att göra, men lita på att bildutrustningen och datormodellen som används för att skapa bilder är korrekta.
Nu, dock, forskning från labbet av Matthew Lew vid McKelvey School of Engineering vid Washington University i St. Louis har utvecklat en beräkningsmetod för att avgöra hur mycket förtroende en forskare ska ha för sina mätningar, när som helst, är korrekta, med tanke på modellen som används för att producera dem.
Forskningen publicerades 11 december i Naturkommunikation .
"I grunden detta är ett rättsmedicinskt verktyg för att berätta om något är rätt eller inte, "sa Lew, biträdande professor vid Preston M. Green Department of Electrical &Systems Engineering. Det är inte bara ett sätt att få en skarpare bild. "Detta är ett helt nytt sätt att validera tillförlitligheten för varje detalj inom en vetenskaplig bild.
"Det handlar inte om att ge bättre upplösning, "tillade han beräkningsmetoden, kallas Wasserstein-inducerad flux (WIF). "Det säger, "Den här delen av bilden kan vara fel eller felplacerad."
Processen som används av forskare för att "se" den mycket små-enmolekylära lokaliseringsmikroskopi (SMLM)-bygger på att fånga massiva mängder information från objektet som avbildas. Den informationen tolkas sedan av en datormodell som i slutändan tar bort det mesta av data, rekonstruera en till synes korrekt bild - en sann bild av en biologisk struktur, som ett amyloidprotein eller ett cellmembran.
Det finns några metoder som redan används för att avgöra om en bild är, generellt, en bra bild av det som avbildas. Dessa metoder, dock, kan inte avgöra hur sannolikt det är att någon enskild datapunkt i en bild är korrekt.
Hesam Mazidi, en nyutexaminerad doktorand i Lew's lab för denna forskning, tacklat problemet.
"Vi ville se om det finns ett sätt att göra något åt detta scenario utan grundlig sanning, "sa han." Om vi kunde använda modellering och algoritmisk analys för att kvantifiera om våra mätningar är trogna, eller noggrann nog. "
Forskarna hade ingen grundsanning - inget hus att jämföra med mäklarens bild - men de var inte tomma händer. De hade en mängd data som vanligtvis ignoreras. Mazidi utnyttjade den massiva mängden information som samlats in av bildenheten som vanligtvis kastas som buller. Fördelningen av buller är något forskarna kan använda som grundsanning eftersom det överensstämmer med specifika fysikaliska lagar.
"Han kunde säga, 'Jag vet hur bildens brus manifesteras, det är en grundläggande fysisk lag, '"Sa Lew om Mazidis insikt.
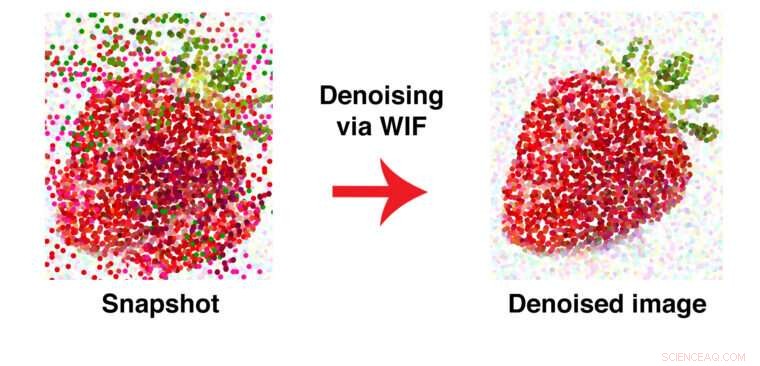
Denna grafik illustrerar hur WIF tar bort felplacerade datapunkter. Efter denoise, gröna bitar av "blad" tas bort från fruktens röda kropp. Upphovsman:Washington University i St. Louis
"Han gick tillbaka till det bullriga, ofullkomlig domän för den faktiska vetenskapliga mätningen, "Sa Lew. Alla datapunkter som registrerats av bildenheten." Det finns riktiga data där som folk slänger och ignorerar. "
Istället för att ignorera det, Mazidi tittade på hur bra modellen förutspådde bruset - med tanke på den slutliga bilden och modellen som skapade den.
Att analysera så många datapunkter liknar att köra bildenheten om och om igen, utför flera testkörningar för att kalibrera det.
"Alla dessa mätningar ger oss statistiskt förtroende, "Sa Lew.
WIF tillåter dem att inte avgöra om hela bilden är trolig utifrån modellen, men, med tanke på bilden, om någon given punkt på bilden är sannolik, baserat på antagandena inbyggda i modellen.
I sista hand, Mazidi utvecklade en metod som med ett starkt statistiskt förtroende kan säga att varje given datapunkt i den slutliga bilden bör eller inte bör vara på en viss plats.
Det är som om algoritmen analyserade bilden av huset och - utan att någonsin ha sett platsen - det rensade upp bilden, avslöjar hålet i väggen.
I slutet, analysen ger ett enda tal per datapunkt, mellan -1 och 1. Ju närmare en, ju mer säker en forskare kan vara att en punkt på en bild är, faktiskt, korrekt representerar det som avbildas.
Denna process kan också hjälpa forskare att förbättra sina modeller. "Om du kan kvantifiera prestanda, då kan du också förbättra din modell genom att använda poängen, Sa Mazidi. Utan tillgång till grundsanning, "det gör att vi kan utvärdera prestanda under verkliga experimentella förhållanden snarare än en simulering."
De potentiella användningsområdena för WIF är långtgående. Lew sa att nästa steg är att använda det för att validera maskininlärning, där partiska datauppsättningar kan ge felaktiga utdata.
Hur skulle en forskare veta, i så fall, att deras data var partisk? "Med denna modell, du skulle kunna testa på data som inte har någon grundlig sanning, där du inte vet om det neurala nätverket har tränats med data som liknar verkliga data.
"Var försiktig i varje typ av mätningar du gör, "Sa Lew." Ibland vill vi bara trycka på den stora röda knappen och se vad vi får, men vi måste komma ihåg, det händer mycket när du trycker på den knappen. "