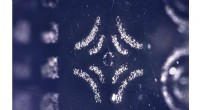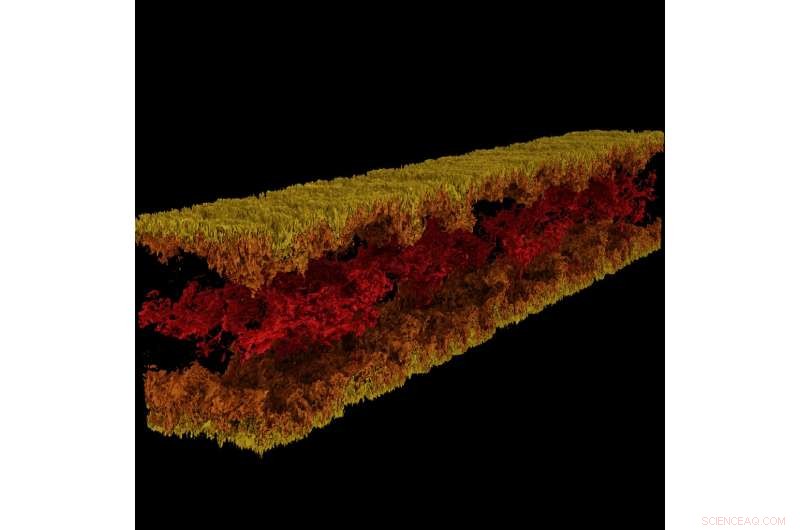
Turbulent kanalflödesvisualisering producerad med GraviT. Kredit:Visualisering:Texas Advanced Computing Center. Data:ICES, University of Texas i Austin.
Stor, effektfull vetenskap kräver att ett helt tekniskt ekosystem utvecklas. Detta inkluderar banbrytande datorsystem, lagring med hög kapacitet, höghastighetsnät, kraft, svalnar ... listan fortsätter och fortsätter.
Kritiskt, det kräver också toppmodern programvara:program som fungerar sömlöst för att låta forskare och ingenjörer svara på svåra frågor, dela med sig av sina lösningar, och bedriva forskning med maximal effektivitet och minimal smärta.
För att vårda detta kritiska sätt för vetenskapliga framsteg, 2012 etablerade NSF programmet Software Infrastructure for Sustained Innovation (SI2), med målet att omvandla innovationer inom forskning och utbildning till hållbara programvaruresurser som är en integrerad del av cyberinfrastrukturen.
"Vetenskaplig upptäckt och innovation går framåt på grundläggande nya vägar som öppnats genom utveckling av allt mer sofistikerad programvara, "National Science Foundation (NSF) skrev i SI2 -programmet." Programvara är också direkt ansvarig för ökad vetenskaplig produktivitet och betydande förbättring av forskares kapacitet. "
Med fem nuvarande SI2 -utmärkelser, och samarbetsroller på flera fler, Texas Advanced Computing Center (TACC) är bland de nationella ledarna när det gäller att utveckla programvara för vetenskaplig databehandling. Huvudutredare från TACC kommer att presentera sitt arbete från 30 april till 2 maj vid NSF SI2 huvudutredningsmöte 2018 i Washington, D.C.
"En del av TACCs uppdrag är att öka produktiviteten för forskare som använder våra system, "sa Bill Barth, TACC -chef för högpresterande datorer och en tidigare SI2 -bidragsmottagare. "SI2 -programmet har hjälpt oss att göra det genom att stödja ansträngningar för att utveckla nya verktyg och utöka befintliga verktyg med ytterligare prestanda och användbarhet."
Från ramverk för storskalig visualisering till automatiska parallelliseringsverktyg och mer, TACC-utvecklad programvara förändrar hur forskare beräknar i framtiden.
Interaktivt parallelliseringsverktyg
Superdatornas kraft ligger främst i deras förmåga att lösa matematiska ekvationer parallellt. Ta ett tufft problem, dela den i dess beståndsdelar, lösa varje del individuellt och sammanför svaren igen - detta är parallell beräkning i dess väsen. Dock, uppgiften att organisera sitt problem så att det kan hanteras av en superdator är inte lätt, även för erfarna beräkningsvetare.
Ritu Arora, en forskare vid TACC, har arbetat för att sänka ribban till parallell databehandling genom att utveckla ett verktyg som kan vända en seriell kod, som bara kan använda en enda processor åt gången, till en parallellkod som kan använda tiotals till tusentals processorer. Verktyget analyserar en seriell applikation, begär ytterligare information från användaren, tillämpar inbyggd heuristik, och genererar en parallellversion av den inmatade seriella applikationen.
Arora och hennes medarbetare distribuerade den nuvarande versionen av IPT i molnet så att forskare enkelt kan använda den via en webbläsare. Forskare kan generera parallella versioner av sin kod halvautomatiskt och testa parallellkoden för noggrannhet och prestanda på TACC- och XSEDE-resurser, inklusive Stampede2, Lonestar5, och kometen.
"Storleken på den samhälleliga effekten av IPT är en direkt funktion av betydelsen av HPC i STEM och framväxande icke-traditionella domäner, och de branta utmaningar som domenexperter och studenter står inför när de klättrar på inlärningskurvan för parallell programmering, "Arora sa." Förutom att minska tiden till utveckling och körtiden för applikationerna på HPC-plattformar, IPT kommer att minska energianvändningen och maximera prestandan från HPC -plattformarna genom dess förmåga att generera hybridkod. "

GraviT gjorde det möjligt för forskare att producera strålspårningsvisualiseringar med data från Enzo, en simuleringskod utformad för rik, multi-fysik hydrodynamiska astrofysiska beräkningar. Upphovsman:University of Texas i Austin
Som ett exempel på IPT:s kapacitet, Arora pekar på en nyligen genomförd insats för att parallellisera en molekylär dynamik (MD) applikation. Genom att parallellisera den seriella applikationen med OpenMP på en hög abstraktionsnivå - det vill säga utan att användaren känner till OpenMP-syntaxen på låg nivå-de uppnådde en hastighet på 88% i koden.
De kvantifierade också effekten av IPT när det gäller användarproduktiviteten genom att mäta antalet kodrader som en forskare måste skriva under processen att parallellisera en applikation manuellt jämfört med att använda IPT.
"I våra testfall, IPT förbättrade användarens produktivitet med mer än 90%, jämfört med att skriva koden manuellt, och genererade parallellkoden som ligger inom 10% av prestanda för den bästa tillgängliga handskrivna parallellkoden för dessa applikationer, "sa Arora." Vi är mycket nöjda med framgångarna hittills. "
TACC utökar IPT för att stödja ytterligare typer av seriella applikationer samt applikationer som uppvisar oregelbundna beräknings- och kommunikationsmönster.
(Se en videodemonstration av IPT där TACC visar processen för parallellisering av en molekylär dynamikapplikation med OpenMP -programmeringsmodellen.)
GraviT
Vetenskaplig visualisering - processen för att omvandla rådata till tolkningsbara bilder - är en nyckelaspekt i forskningen. Dock, det kan vara utmanande när du försöker visualisera datauppsättningar i petabyte-skala spridda bland många noder i ett datorkluster. Ännu mer när du försöker använda avancerade visualiseringsmetoder som strålspårning - en teknik för att generera en bild genom att spåra ljusets väg som pixlar i ett bildplan och simulera effekterna av dess möten med virtuella objekt.
För att lösa detta problem, Paul Navratil, direktör för visualisering på TACC, har lett ett försök att skapa GraviT, en skalbar, distribuerat minnesstrålspårningsramverk och mjukvarubibliotek för applikationer som omfattar så stora data att de inte kan finnas i minnet hos en enda beräkningsnod. Collaborators on the project include Hank Childs (University of Oregon), Chuck Hansen (University of Utah), Matt Turk (National Center for Supercomputing Applications) and Allen Malony (ParaTools).
GraviT works across a variety of hardware platforms, including the Intel Xeon processors and NVIDIA GPUs. It can also function in heterogeneous computing environments, till exempel, hybrid CPU and GPU systems. GraviT has been successfully integrated into the GLuRay OpenGL-based ray tracing interface, the VisIt visualization toolkit, the VTK visualization toolkit, and the yt visualization framework.
"High-fidelity rendering techniques like ray tracing improve visual analysis by providing the same spatial cues of light and shadow that we see in the world around us, but these are challenging to use in distributed contexts, " said Navratil. "GraviT enables these techniques to be used efficiently across distributed computing resources, unlocking their potential for large scale analysis and to be used in situ, where data is not written to disk prior to analysis."
(The GraviT source code is available at the TACC GitHub site ).
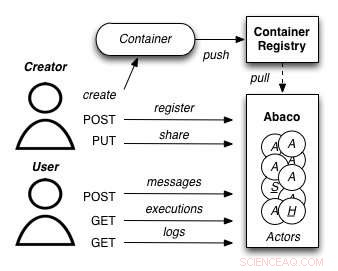
A diagram showing how the Abaco "Actor" model works. Credit:University of Texas at Austin
Abaco
The increased availability of data has enabled entirely new kinds of analyses to emerge, yielding answers to many important questions. Dock, these analyses are complex and frequently require advanced computer science expertise to run correctly.
Joe Stubbs, who leads TACC's Cloud and Interactive Computing (CIC) group, is working on a project that simplifies how researchers create analysis tools that are reliable and scalable. The project, known as Abaco, adapts the "Actor" model, whereby software systems are designed as a collection of simple functions, which can then be provided as a cloud-based capability on high performance computing environments.
"Abaco significantly simplifies the way scientific software is developed and used, " said Stubbs. "Scientific software developers will find it much easier to design and implement a system. Further, scientists and researchers that use software will be able to easily compose collections of actors with pre-determined functionality in order to get the computation and data they need."
The Abaco API (application programming interface) combines technologies and techniques from cloud computing, including Linux Containers and the "functions-as-a-service" paradigm, with the Actor model for concurrent computation. Investigators addressing grand challenge problems in synthetic biology, earthquake engineering and food safety are already using the tool to advance their work. Stubbs is working to extend Abaco's ability to do data federation and discoverability, so Abaco programs can be used to build federated datasets consisting of separate datasets from all over the internet.
"By reducing the barriers to developing and using such services, this project will boost the productivity of scientists and engineers working on the problems of today, and better prepare them to tackle the new problems of tomorrow, " Stubbs said.
Expanding volunteer computing
Volunteer computing uses donated computing time on consumer devices such as home computers and smartphones to conduct scientific investigations. Early successes from this approach include the discovery of the structure of an enzyme involved in reproduction of HIV by FoldIt participants; and the detection of pulsars using Einstein@Home.
Volunteer computing can provide greater computing power, at lower cost, than conventional approaches such as organizational computing centers and commercial clouds, but participation in volunteer computing efforts is yet to reach its full potential.
TACC is partnering with the University of California at Berkeley and Purdue University to build new capabilities for BOINC (the most common software framework used for volunteer computing) to grow this promising mode of distributed computing. The project involves two complementary development efforts. Först, it adds BOINC-based volunteer computing conduits to two major high-performance computing providers:TACC and nanoHUB, a web portal for nano science that provides computing capabilities. På det här sättet, the project benefits the thousands of scientists who use these facilities and creates technologies that make it easy for other HPC providers to add their own volunteer computing capability to their systems.
Second, the team will develop a unified interface for volunteer computing, tentatively called Science United, where donors can register to participate and scientists can market their volunteer computing projects to the public.
TACC is currently setting up a BOINC server on Jetstream and using containerization technologies, such as Docker and VirtualBox, to build and package popular applications that can run in high-throughput computing mode on the devices of volunteers. Initial applications being tested include AutoDock Vina, used for drug discovery, and OpenSees, used by the natural hazards community. As a next step, TACC will develop the plumbing required for selecting and routing qualified jobs from TACC resources to the BOINC server.
"By creating a huge pool of low-cost computing power that will benefit thousands of scientists, and increasing public awareness of and interest in science, the project plans to establish volunteer computing as a central and long-term part of the U.S. scientific cyber infrastructure, " said David Anderson, the lead principal investigator on the project from UC Berkeley.