Kredit:Liu et al.
Forskare vid Leiden University och National University of Defense Technology (NUDT), i Kina, har nyligen utvecklat en ny metod för bild-textmatchning, kallas CycleMatch. Deras tillvägagångssätt, presenteras i en artikel publicerad i Elsevier's Mönsterigenkänning tidning, bygger på cykelkonsekvent lärande, en teknik som ibland används för att träna artificiella neurala nätverk på bild-till-bild översättningsuppgifter. Den allmänna tanken bakom cykelkonsistens är att när källdata omvandlas till måldata och sedan tvärtom, man bör äntligen få de ursprungliga källproverna.
När det gäller att utveckla verktyg för artificiell intelligens (AI) som fungerar bra i multimodala eller multimediabaserade uppgifter, att hitta sätt att överbrygga bilder och textrepresentationer är av avgörande betydelse. Tidigare studier har försökt uppnå detta genom att avslöja semantik eller egenskaper som är relevanta för både syn och språk.
När du tränar algoritmer om korrelationer mellan olika metoder, dock, dessa studier har ofta försummat eller misslyckats med att ta itu med intra-modal semantisk konsistens, vilket är konsistensen av semantik för de individuella modaliteterna (dvs syn och språk). För att komma till rätta med denna brist, forskargruppen vid Leiden University och NUDT föreslog ett tillvägagångssätt som tillämpar cykelkonsistenta inbäddningar i ett djupt neuralt nätverk för att matcha visuella och textuella representationer.
"Vårt tillvägagångssätt, heter CycleMatch, kan upprätthålla både intermodala korrelationer och intramodal konsistens genom att kaskadkoppla dubbla mappningar och rekonstruerade mappningar på ett cykliskt sätt, "skrev forskarna i sitt papper." Dessutom, för att uppnå en robust slutsats, vi föreslår att använda två sena fusionsmetoder:genomsnittlig fusion och adaptiv fusion."
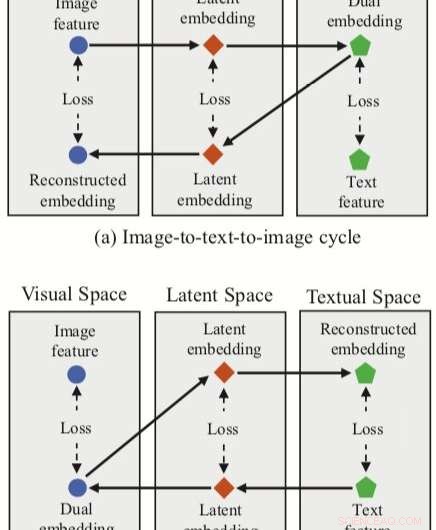
Tillvägagångssättet som utarbetats av forskarna integrerar tre funktionsinbäddningar (dubbel, rekonstruerade och latenta inbäddningar) med ett neuralt nätverk för bild-textmatchning. Metoden har två cykelgrenar, en utgående från ett bildinslag i det visuella rummet och ett från ett textinslag i det textuella rummet.
För var och en av dessa cykler, deras tillvägagångssätt uppnår en dubbel kartläggning, översätta en ingångsfunktion i källutrymmet till en dubbel inbäddning i målutrymmet. Forskarna tillämpar sedan rekonstruerad kartläggning, försöker översätta denna dubbla inbäddning tillbaka till källutrymmet.
Deras tillvägagångssätt gör det också möjligt för forskarna att förvärva ett 'latent utrymme' under både dubbla och rekonstruerade kartläggningar, och därefter korrelera latenta inbäddningar. I motsats till andra tekniker för bild-textmatchning, därför, deras metod kan lära sig både intermodala mappningar (d.v.s. bild-till-text och text-till-bild) och intra-modala mappningar (bild-till-bild och text-till-text).
För att utvärdera deras tillvägagångssätt, forskarna genomförde en rad experiment med två kända multimodala datamängder, Flickr30K och MSCOCO. Deras metod gav toppmoderna resultat, överträffar traditionella tillvägagångssätt och leder till betydande förbättringar av intermodal hämtning.
Dessa fynd tyder på att cykelkonsekventa inbäddningar kan förbättra prestandan hos neurala nätverk i multimodala uppgifter, som bild-textmatchning, gör det möjligt för dem att förvärva både intermodala och intramodala kartläggningar. I deras framtida arbete, forskarna planerar att utveckla sitt tillvägagångssätt ytterligare, genom att ta hänsyn till lokala relationer vid matchning av bilder och text (t.ex. semantiska samband mellan visuella regioner och fraser).
© 2019 Science X Network