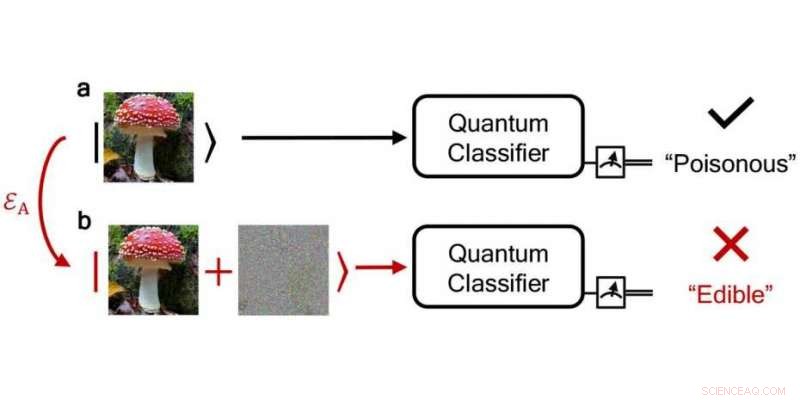
En pålitlig kvantklassificeringsalgoritm klassificerar korrekt en giftig svamp som "giftig" medan en bullrig, störd klassificerar man det felaktigt som "ätbart". Kredit:npj Quantum Information / DS3Lab ETH Zürich
Alla som samlar svamp vet att det är bättre att hålla isär de giftiga och de icke-giftiga. I sådana "klassificeringsproblem, "som kräver att man särskiljer vissa objekt från varandra och att tilldela de objekt vi söker till vissa klasser med hjälp av egenskaper, datorer ger redan användbart stöd.
Intelligenta maskininlärningsmetoder kan känna igen mönster eller objekt och automatiskt välja dem ur datamängder. Till exempel, de kunde plocka ut de där bilderna från en fotodatabas som visar giftfria svampar. Särskilt med mycket stora och komplexa datamängder, maskininlärning kan leverera värdefulla resultat som människor inte skulle kunna avgöra utan mycket tid och ansträngning. Dock, för vissa beräkningsuppgifter, även de snabbaste datorerna som finns tillgängliga idag når sina gränser. Det är här det stora löftet om kvantdatorer kommer in – en dag, de skulle kunna utföra supersnabba beräkningar som klassiska datorer inte kan lösa under en användbar tidsperiod.
Anledningen till denna "kvantöverhöghet" ligger i fysiken:Kvantdatorer beräknar och bearbetar information genom att utnyttja vissa tillstånd och interaktioner som sker inom atomer eller molekyler eller mellan elementarpartiklar.
Det faktum att kvanttillstånd kan överlappa och trassla in skapar en bas som ger kvantdatorer tillgång till en fundamentalt rikare uppsättning bearbetningslogik. Till exempel, till skillnad från klassiska datorer, kvantdatorer beräknar inte med binära koder eller bitar, som endast behandlar information som 0 eller 1, men med kvantbitar eller kvantbitar, som motsvarar partiklarnas kvanttillstånd. Den avgörande skillnaden är att qubits inte bara kan realisera ett tillstånd – 0 eller 1 – per beräkningssteg, men också en överlagring av båda. Dessa mer allmänna metoder för informationsbehandling möjliggör i sin tur en drastisk beräkningshastighet i vissa problem.
Att översätta klassisk visdom till kvantvärlden
Dessa snabbhetsfördelar med kvantberäkning är också en möjlighet för maskininlärningsapplikationer – trots allt, kvantdatorer kan beräkna de enorma mängder data som maskininlärningsmetoder behöver för att förbättra noggrannheten i sina resultat mycket snabbare än klassiska datorer.
Dock, att verkligen utnyttja potentialen med kvantberäkning, det är nödvändigt att anpassa klassiska maskininlärningsmetoder till kvantdatorernas egenheter. Till exempel, algoritmer, dvs. de matematiska reglerna som beskriver hur en klassisk dator löser ett visst problem, måste formuleras annorlunda för kvantdatorer. Att utveckla välfungerande kvantalgoritmer för maskininlärning är inte helt trivialt, eftersom det fortfarande finns några hinder att övervinna på vägen.
Å ena sidan, detta beror på kvanthårdvaran. På ETH Zürich, forskare har för närvarande kvantdatorer som fungerar med upp till 17 qubits (se "ETH Zürich och PSI hittade Quantum Computing Hub" av 3 maj 2021). Dock, om kvantdatorer en dag ska förverkliga sin fulla potential, de kan behöva tusentals till hundratusentals qubits.
Kvantbrus och oundvikligheten av fel
En utmaning som kvantdatorer står inför rör deras sårbarhet för fel. Dagens kvantdatorer arbetar med mycket hög ljudnivå, eftersom fel eller störningar är kända i teknisk jargong. För American Physical Society, detta brus är "det största hindret för att skala upp kvantdatorer." Det finns ingen heltäckande lösning för att både korrigera och mildra fel. Inget sätt har ännu hittats för att producera felfri kvanthårdvara, och kvantdatorer med 50 till 100 qubits är för små för att implementera korrigeringsprogram eller algoritmer.
Till en viss grad, fel i kvantberäkning är i princip oundvikliga, eftersom de kvanttillstånd som de konkreta beräkningsstegen bygger på endast kan särskiljas och kvantifieras med sannolikheter. Vad kan uppnås, å andra sidan, är rutiner som begränsar omfattningen av buller och störningar i en sådan utsträckning att beräkningarna ändå ger tillförlitliga resultat. Datavetare hänvisar till en tillförlitligt fungerande beräkningsmetod som "robust, "och i detta sammanhang, talar också om den nödvändiga "feltoleransen".
Detta är vad forskargruppen leds av Ce Zhang, ETH datavetenskapsprofessor och medlem av ETH AI Center, har nyligen utforskat, på något sätt "av misstag" under en strävan att resonera om robustheten hos klassiska distributioner i syfte att bygga bättre maskininlärningssystem och plattformar. Tillsammans med professor Nana Liu från Shanghai Jiao Tong University och med professor Bo Li från University of Illinois i Urbana, de har utvecklat ett nytt tillvägagångssätt som bevisar robusthetsvillkoren hos vissa kvantbaserade maskininlärningsmodeller, för vilken kvantberäkningen garanterat är tillförlitlig och resultatet blir korrekt. Forskarna har publicerat sin metod, som är en av de första i sitt slag, i den vetenskapliga tidskriften npj Kvantinformation .
Skydd mot fel och hackare
"När vi insåg att kvantalgoritmer, som klassiska algoritmer, är benägna att göra fel och störningar, vi frågade oss själva hur vi kan uppskatta dessa källor till fel och störningar för vissa maskininlärningsuppgifter, och hur vi kan garantera robustheten och tillförlitligheten hos den valda metoden, " säger Zhikuan Zhao, en postdoc i Ce Zhangs grupp. "Om vi vet detta, vi kan lita på beräkningsresultaten, även om de är bullriga."
Forskarna undersökte denna fråga med hjälp av kvantklassificeringsalgoritmer som ett exempel - trots allt, fel i klassificeringsuppgifter är knepiga eftersom de kan påverka den verkliga världen, till exempel om giftiga svampar klassificerades som giftfria. Kanske viktigast av allt, genom att använda teorin om kvanthypotestestning – inspirerad av andra forskares senaste arbete med att tillämpa hypotestestning i den klassiska miljön – vilket gör att kvanttillstånd kan särskiljas, ETH-forskarna bestämde ett tröskelvärde över vilket tilldelningarna av kvantklassificeringsalgoritmen garanterat är korrekta och dess förutsägelser robusta.
Med sin robusthetsmetod, forskarna kan till och med kontrollera om klassificeringen av en felaktig, brusig ingång ger samma resultat som en ren, ljudlös ingång. Från deras fynd, forskarna har också utvecklat ett skyddsschema som kan användas för att specificera feltoleransen för en beräkning, oavsett om ett fel har en naturlig orsak eller är resultatet av manipulation från en hackingattack. Deras robusthetskoncept fungerar för både hackattacker och naturliga fel.
"Metoden kan också tillämpas på en bredare klass av kvantalgoritmer, säger Maurice Weber, en doktorand med Ce Zhang och den första författaren till publikationen. Eftersom effekten av fel i kvantberäkning ökar när systemstorleken ökar, han och Zhao forskar nu om detta problem. "Vi är optimistiska att våra robusthetsvillkor kommer att visa sig användbara, till exempel, i kombination med kvantalgoritmer utformade för att bättre förstå den elektroniska strukturen hos molekyler."