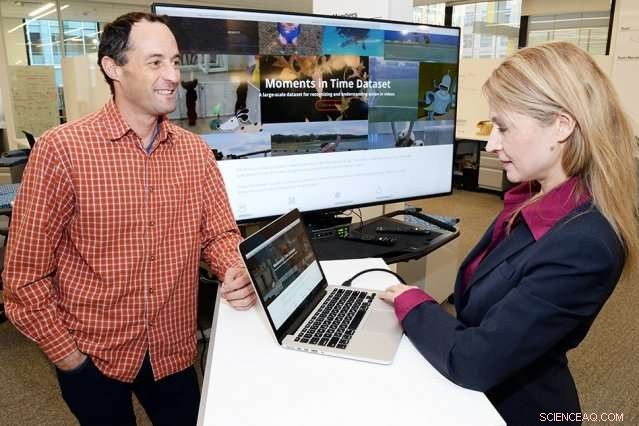
Aude Oliva (höger), en huvudforskare vid datavetenskap och artificiell intelligens Laboratory och Dan Gutfreund (till vänster), en huvudutredare vid MIT–IBM Watson AI Laboratory och en anställd vid IBM Research, är huvudutredarna för datauppsättningen Moments in Time, ett av projekten relaterat till AI-algoritmer finansierat av MIT–IBM Watson AI Laboratory. Kredit:John Mottern/Feature Photo Service för IBM
En person som tittar på videor som visar saker som öppnas – en dörr, en bok, gardiner, en blommande blomma, en gäspande hund – förstår lätt att samma typ av handling avbildas i varje klipp.
"Datormodeller misslyckas med att identifiera dessa saker. Hur gör människor det så enkelt?" frågar Dan Gutfreund, en huvudutredare vid MIT-IBM Watson AI Laboratory och en anställd på IBM Research. "Vi bearbetar information när den sker i rum och tid. Hur kan vi lära datormodeller att göra det?"
Sådana är de stora frågorna bakom ett av de nya projekt som pågår vid MIT-IBM Watson AI Laboratory, ett samarbete för forskning om artificiell intelligenss gränser. Lanserades i höstas, labbet kopplar samman MIT- och IBM-forskare för att arbeta med AI-algoritmer, tillämpningen av AI på industrier, AI:s fysik, och sätt att använda AI för att främja delat välstånd.
Datasetet Moments in Time är ett av projekten relaterade till AI-algoritmer som finansieras av labbet. Den parar Gutfreund med Aude Oliva, en huvudforskare vid MIT Computer Science and Artificial Intelligence Laboratory, som projektets huvudutredare. Moments in Time bygger på en samling av 1 miljon kommenterade videor av dynamiska händelser som utspelar sig inom tre sekunder. Gutfreund och Oliva, som också är MIT verkställande direktör vid MIT-IBM Watson AI Lab, använder dessa klipp för att ta itu med ett av nästa stora steg för AI:lära maskiner att känna igen handlingar.
Lär dig av dynamiska scener
Målet är att tillhandahålla algoritmer för djupinlärning med stor täckning av ett ekosystem av visuella och auditiva ögonblick som kan göra det möjligt för modeller att lära sig information som inte nödvändigtvis lärs ut på ett övervakat sätt och att generalisera till nya situationer och uppgifter, säger forskarna.
"När vi växer upp, vi ser oss omkring, vi ser människor och föremål röra sig, vi hör ljud som människor och föremål gör. Vi har många visuella och auditiva erfarenheter. Ett AI-system behöver lära sig på samma sätt och matas med videor och dynamisk information, säger Oliva.
För varje åtgärdskategori i datamängden, som matlagning, löpning, eller öppning, det finns fler än 2, 000 videor. De korta klippen gör det möjligt för datormodeller att bättre lära sig mångfalden av betydelse kring specifika handlingar och händelser.
"Denna datauppsättning kan fungera som en ny utmaning för att utveckla AI-modeller som skalas till den nivå av komplexitet och abstrakta resonemang som en människa bearbetar dagligen, " tillägger Oliva, beskriva de faktorer som är inblandade. Händelser kan inkludera personer, objekt, djur, och naturen. De kan vara symmetriska i tiden – till exempel, öppning betyder stängning i omvänd ordning. Och de kan vara övergående eller ihållande.
Oliva och Gutfreund, tillsammans med ytterligare forskare från MIT och IBM, träffades varje vecka i mer än ett år för att ta itu med tekniska problem, till exempel hur man väljer åtgärdskategorier för kommentarer, var man hittar videorna, och hur man sätter ihop ett brett utbud så att AI-systemet lär sig utan fördomar. Teamet utvecklade också maskininlärningsmodeller, som sedan användes för att skala datainsamlingen. "Vi anpassade oss väldigt bra eftersom vi har samma entusiasm och samma mål, säger Oliva.
Öka mänsklig intelligens
Ett nyckelmål på labbet är utvecklingen av AI-system som går bortom specialiserade uppgifter för att tackla mer komplexa problem och dra nytta av robust och kontinuerligt lärande. "Vi letar efter nya algoritmer som inte bara utnyttjar big data när de är tillgängliga, men också lära av begränsad data för att öka mänsklig intelligens, " säger Sophie V. Vandebroek, operativ chef för IBM Research, om samarbetet.
Förutom att para ihop de unika tekniska och vetenskapliga styrkorna hos varje organisation, IBM ger också MIT-forskare ett tillflöde av resurser, signalerat av dess investering på 240 miljoner dollar i AI-insatser under de kommande 10 åren, tillägnad MIT-IBM Watson AI Lab. Och anpassningen av MIT-IBMs intresse för AI visar sig vara fördelaktig, enligt Oliva.
"IBM kom till MIT med ett intresse av att utveckla nya idéer för ett artificiellt intelligenssystem baserat på vision. Jag föreslog ett projekt där vi bygger datamängder för att mata modellen om världen. Det hade inte gjorts tidigare på den här nivån. Det var ett nytt företag. Nu har vi nått milstolpen med 1 miljon videor för visuell AI-träning, och folk kan gå till vår webbplats, ladda ner datasetet och våra djupinlärningsdatormodeller, som har lärts känna igen handlingar."
Kvalitativa resultat hittills har visat att modeller kan känna igen ögonblick när handlingen är väl inramad och nära, men de slår fel när kategorin är finkornig eller det är rörigt i bakgrunden, bland annat. Oliva säger att forskare från MIT och IBM har skickat in en artikel som beskriver prestandan för neurala nätverksmodeller som tränats på datamängden, som i sig fördjupades av delade synpunkter. "IBM-forskare gav oss idéer för att lägga till åtgärdskategorier för att få mer rikedom inom områden som hälsovård och sport. De vidgade vår syn. De gav oss idéer om hur AI kan påverka ur affärsperspektivet och världens behov, " hon säger.
Denna första version av Moments in Time-datauppsättningen är en av de största mänskliga kommenterade videodataseten som fångar visuella och hörbara korta händelser, som alla är taggade med en åtgärds- eller aktivitetsetikett bland 339 olika klasser som inkluderar ett brett utbud av vanliga verb. Forskarna avser att producera fler datamängder med en mängd olika abstraktionsnivåer för att fungera som språngbrädor mot utvecklingen av inlärningsalgoritmer som kan bygga analogier mellan saker, föreställa sig och syntetisera nya händelser, och tolka scenarier.
Med andra ord, de har precis börjat, säger Gutfreund. "Vi förväntar oss att datasetet Moments in Time gör det möjligt för modeller att rikt förstå handlingar och dynamik i videor."
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.