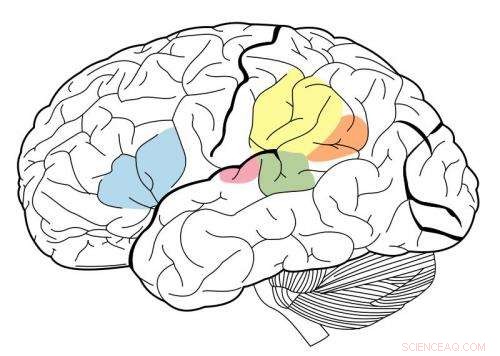
Den primära hörselbarken är markerad i magenta, och har varit känd för att interagera med alla områden som är markerade på denna neurala karta. Kredit:Wikipedia.
Genom att använda ett maskininlärningssystem som kallas ett djupt neuralt nätverk, MIT-forskare har skapat den första modellen som kan replikera mänsklig prestation på auditiva uppgifter som att identifiera en musikalisk genre.
Den här modellen, som består av många lager av informationsbehandlingsenheter som kan tränas på stora mängder data för att utföra specifika uppgifter, användes av forskarna för att belysa hur den mänskliga hjärnan kan utföra samma uppgifter.
"Vad dessa modeller ger oss, för första gången, är maskinsystem som kan utföra sensoriska uppgifter som är viktiga för människor och som gör det på mänsklig nivå, " säger Josh McDermott, Frederick A. och Carole J. Middleton biträdande professor i neurovetenskap vid avdelningen för hjärn- och kognitionsvetenskap vid MIT och den seniora författaren till studien. "Historiskt sett, denna typ av sensorisk bearbetning har varit svår att förstå, delvis för att vi inte riktigt har haft en särskilt tydlig teoretisk grund och ett bra sätt att utveckla modeller för vad som kan hända."
Studien, som visas i 19 april-numret av Nervcell , ger också bevis på att den mänskliga hörselbarken är ordnad i en hierarkisk organisation, ungefär som synbarken. I denna typ av arrangemang, sensorisk information passerar genom successiva stadier av bearbetning, med grundläggande information som bearbetats tidigare och mer avancerade funktioner som ordbetydelse extraheras i senare skeden.
MIT doktorand Alexander Kell och Stanford University Assistant Professor Daniel Yamins är tidningens huvudförfattare. Andra författare är tidigare MIT-besökande student Erica Shook och före detta MIT postdoc Sam Norman-Haignere.
Modellera hjärnan
När djupa neurala nätverk först utvecklades på 1980-talet, neuroforskare hoppades att sådana system skulle kunna användas för att modellera den mänskliga hjärnan. Dock, datorer från den eran var inte tillräckligt kraftfulla för att bygga modeller som var tillräckligt stora för att utföra verkliga uppgifter som objektigenkänning eller taligenkänning.
Under de senaste fem åren, framsteg inom datorkraft och neurala nätverksteknik har gjort det möjligt att använda neurala nätverk för att utföra svåra verkliga uppgifter, och de har blivit standardmetoden i många tekniska tillämpningar. Parallellt, vissa neuroforskare har återupptagit möjligheten att dessa system kan användas för att modellera den mänskliga hjärnan.
"Det har varit en spännande möjlighet för neurovetenskap, genom att vi faktiskt kan skapa system som kan göra några av de saker som människor kan göra, och vi kan sedan förhöra modellerna och jämföra dem med hjärnan, " säger Kell.
MIT-forskarna tränade sitt neurala nätverk för att utföra två auditiva uppgifter, den ena involverar tal och den andra involverar musik. För taluppgiften, forskarna gav modellen tusentals två sekunder långa inspelningar av en person som pratade. Uppgiften var att identifiera ordet i mitten av klippet. För musikuppgiften, modellen ombads att identifiera genren för ett två sekunder långt musikklipp. Varje klipp inkluderade också bakgrundsljud för att göra uppgiften mer realistisk (och svårare).
Efter många tusen exempel, modellen lärde sig att utföra uppgiften lika exakt som en mänsklig lyssnare.
"Tanken är att modellen med tiden blir bättre och bättre på uppgiften, " säger Kell. "Förhoppningen är att det lär sig något allmänt, så om du presenterar ett nytt ljud som modellen aldrig har hört förut, det kommer att gå bra, och i praktiken är det ofta så."
Modellen tenderade också att göra misstag på samma klipp som människor gjorde flest misstag på.
Bearbetningsenheterna som utgör ett neuralt nätverk kan kombineras på en mängd olika sätt, bildar olika arkitekturer som påverkar modellens prestanda.
MIT-teamet upptäckte att den bästa modellen för dessa två uppgifter var en som delade upp bearbetningen i två uppsättningar av steg. Den första uppsättningen steg delades mellan uppgifter, men efter det, den delas upp i två grenar för vidare analys – en gren för taluppgiften, och en för musikgenreuppgiften.
Bevis för hierarki
Forskarna använde sedan sin modell för att utforska en långvarig fråga om strukturen hos hörselbarken:om den är organiserad hierarkiskt.
I ett hierarkiskt system, en serie hjärnregioner utför olika typer av beräkning av sensorisk information när den flödar genom systemet. Det är väl dokumenterat att den visuella cortex har denna typ av organisation. Tidigare regioner, känd som den primära visuella cortex, svara på enkla funktioner som färg eller orientering. Senare stadier möjliggör mer komplexa uppgifter som objektigenkänning.
Dock, det har varit svårt att testa om denna typ av organisation även finns i hörselbarken, delvis för att det inte har funnits bra modeller som kan replikera mänskligt hörselbeteende.
"Vi tänkte att om vi kunde konstruera en modell som kunde göra några av samma saker som människor gör, vi kanske då kan jämföra olika stadier av modellen med olika delar av hjärnan och få några bevis för om dessa delar av hjärnan kan vara hierarkiskt organiserade, " säger McDermott.
Forskarna fann att i sin modell, grundläggande egenskaper hos ljud som frekvens är lättare att extrahera i de tidiga stadierna. När information bearbetas och förflyttas längre längs nätverket, det blir svårare att extrahera frekvens men lättare att extrahera information på högre nivå som ord.
För att se om modellstadierna kan replikera hur den mänskliga hörselbarken bearbetar ljudinformation, forskarna använde funktionell magnetisk resonanstomografi (fMRI) för att mäta olika regioner av hörselbarken när hjärnan bearbetar verkliga ljud. De jämförde sedan hjärnans svar med svaren i modellen när den bearbetade samma ljud.
De fann att mellanstadierna i modellen bäst motsvarade aktiviteten i den primära hörselbarken, och senare stadier motsvarade bäst aktivitet utanför den primära cortexen. Detta ger bevis för att den auditiva cortex kan vara ordnad på ett hierarkiskt sätt, liknande den visuella cortex, säger forskarna.
"Vad vi ser väldigt tydligt är en skillnad mellan primär hörselbark och allt annat, " säger McDermott.
Författarna planerar nu att utveckla modeller som kan utföra andra typer av auditiva uppgifter, som att bestämma varifrån ett visst ljud kom, att undersöka om dessa uppgifter kan utföras via de vägar som identifierats i denna modell eller om de kräver separata vägar, som sedan kunde undersökas i hjärnan.