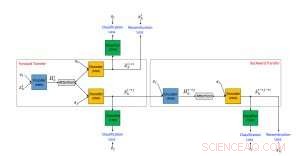
Föreslagen ram för en överföringsalgoritm för neural textstil som använder icke-parallella data. Kredit:IBM
Sociala medier online har blivit ett av de viktigaste sätten att kommunicera och utbyta idéer. Tyvärr, diskursen är ofta förlamad av kränkande språkbruk som kan ha skadliga effekter på användare av sociala medier. Till exempel, en nyligen genomförd undersökning av YouGov.uk upptäckte att, bland den information som arbetsgivare kan hitta online om jobbkandidater, aggressivt eller stötande språk är den mest professionellt skadliga aktiviteten i sociala medier. Sociala medier online hanterar normalt det stötande språkproblemet genom att helt enkelt filtrera bort ett inlägg när det flaggas som stötande.
I tidningen "Fighting Offensive Language on Social Media with Onsupervised Text Style Transfer, " som presenterades vid det 56:e årsmötet i Association for Computational Linguistics (ACL 2018), vi introducerar ett helt nytt tillvägagångssätt för att ta itu med detta problem. Vår metod använder oövervakad textstilsöverföring för att översätta stötande meningar till motsvarande icke stötande former. Som vi förstår det, allt tidigare arbete som behandlar problemet med stötande språk på sociala medier har fokuserat enbart på textklassificering. Dessa metoder kan därför främst användas för att flagga och filtrera bort det stötande innehållet, men vårt föreslagna tillvägagångssätt går ett steg framåt och producerar en alternativ icke-stötande version av innehållet. Detta har två potentiella fördelar för användare av sociala medier. För de användare som planerar att skicka ett stötande meddelande, får en varning om att innehållet är stötande och kommer att blockeras, tillsammans med en mer artig version av meddelandet som kan läggas upp, kan uppmuntra dem att ändra sig och undvika svordomar. Dessutom, för användare som konsumerar onlineinnehåll, detta gör att de fortfarande kan se och förstå budskapet men i en icke-offensiv och artig ton.
En arkitektur för att ersätta stötande språk
Vår metod är baserad på den nu populära encoder-decoder neurala nätverksarkitekturen, vilket är det toppmoderna tillvägagångssättet för maskinöversättning. I maskinöversättning, utbildningen av kodar-avkodare neurala nätverk förutsätter existensen av en "Rosetta Stone" där samma text är skriven på både käll- och målspråk. Denna parade data gör det möjligt för utvecklare att enkelt avgöra om ett system översätter korrekt och därför utbilda ett kodare-avkodarsystem för att göra det bra. Tyvärr, till skillnad från maskinöversättning, så vitt vi vet, det finns ingen datauppsättning med parade data tillgängligt för fallet med stötande till icke-stötande straff. Dessutom, den överförda texten måste använda ett ordförråd som är vanligt i en viss applikationsdomän. Därför, oövervakade metoder som inte använder parad data behövs för att utföra denna uppgift.

Vi föreslog en oövervakad metod för överföring av textstil som består av tre huvudkomponenter, var och en får en separat uppgift under utbildningen. En (en RNN-kodare) analyserar en stötande mening och komprimerar den mest relevanta informationen till en vektor med verkligt värde. Detta läses av en annan komponent (en RNN -avkodare), som genererar en ny mening som är den översatta versionen av den ursprungliga. Den översatta meningen utvärderas sedan av den tredje komponenten (en CNN-klassificerare) för att identifiera om utmatningen har översatts korrekt från den offensiva stilen till icke-offensiv. Dessutom, den genererade meningen är också "back-translated" från icke-stötande till stötande och jämförs med den ursprungliga meningen för att kontrollera om innehållet bevarats. Om resultaten av någon av ovanstående utvärderingar innehåller fel, systemet anpassas därefter. Kodaren och avkodaren är också, parallellt, tränas med hjälp av en autoencoding setup där målet består i att rekonstruera den inmatade meningen. Vi använder också uppmärksamhetsmekanismen som hjälper till att säkerställa innehållsbevarande. Vårt främsta bidrag när det gäller arkitektur är den kombinerade användningen av en kollaborativ klassificerare, uppmärksamhet, och tillbakaöverföring.
Översätta kränkande språk
Vi testade vår föreslagna metod med hjälp av data från två populära sociala medier:Twitter och Reddit. Vi skapade datamängder av stötande och icke-kränkande texter genom att klassificera cirka 10 miljoner inlägg med en offensiv språkklassificerare som föreslagits av Davidson et al. (2017). Följande tabell visar exempel på ursprungliga stötande meningar och de icke-stötande översättningarna som genereras av en textstilsöverföringsmetod som föreslagits av Shen et al. (2017) och enligt vårt tillvägagångssätt. Vårt system visade bättre prestanda när det gällde att översätta stötande meningar till icke-stötande, samtidigt som det övergripande innehållet bevarades, men det ger ibland udda meningar.
Detta arbete är ett första steg i riktning mot en ny lovande strategi för att bekämpa kränkande inlägg på sociala medier. Oövervakad textstilsöverföring är ett forskningsområde som precis har börjat se några lovande resultat. Vårt arbete är ett bra bevis på att nuvarande oövervakade metoder för överföring av textstil kan tillämpas på användbara uppgifter. Dock, det är viktigt att notera att nuvarande oövervakade metoder för textstilsöverföring endast kan hantera de fall där det stötande språkproblemet är lexikalt (som exemplen som visas i tabellen) och kan lösas genom att ändra eller ta bort några ord. De modeller vi använde kommer inte att vara effektiva i fall av implicit bias där vanliga oförargliga ord används kränkande.
Vi tror att förbättrade versioner av den föreslagna metoden, tillsammans med användningen av mycket större mängder träningsdata, kommer att kunna hantera andra kränkande inlägg som inlägg som innehåller hatretorik, rasism, och sexism. Vi föreställer oss att vår metod skulle kunna användas för att förbättra konversations-AI, genom att se till att chatbots som lär sig genom att interagera med användare online inte senare kommer att reproducera stötande språk och hatprat. Föräldrakontroll är en annan potentiell användning av det föreslagna systemet.
Den här historien återpubliceras med tillstånd av IBM Research.