Kredit:Gerlach et al.
Forskare vid Northwestern University, University of Bath, och University of Sydney har utvecklat en ny nätverksansats för ämnesmodeller, maskininlärningsstrategier som kan upptäcka abstrakta ämnen och semantiska strukturer i textdokument.
"En av de största beräkningsmässiga och vetenskapliga utmaningarna i modern tid är att extrahera användbar information från ostrukturerade texter, " förklarade forskarna i sin studie. "Ämnesmodeller är en populär metod för maskininlärning som härleder den latenta aktuella strukturen hos en samling dokument."
Ämnesmodeller används för närvarande för att identifiera semantiskt relaterade texter och klassificera dokument inom ett antal områden, inklusive sociologi, historia, lingvistik, och psykologi. Den mest använda metoden, latent Dirichlet-allokering (LDA), används också för bibliometriska, psykologisk och politisk analys, samt för bildbehandling.
Trots sin omfattande framgång, LDA presenterar flera brister i hur den representerar text, såsom brist på metod för att välja antal ämnen, avvikelser med statistiska egenskaper hos verkliga texter och brist på motivering för den Bayesianska preskriptionen, som i Bayesiansk statistisk slutledning är sannolikhetsfördelningen uttryckt innan bevis presenteras.
Kredit:Gerlach et al.
En stor del av den senaste tidens forskning om ämnesmodeller har fokuserat på att skapa mer sofistikerade versioner av LDA som presterar bättre eller effektivt kan analysera specifika aspekter av dokument.
Tillvägagångssättet som utvecklats av detta team av forskare härrör från nätverksteori, en teori som används inom fysik och andra vetenskapliga områden som tillhandahåller tekniker för att analysera grafer, samt strukturer i system med olika interagerande medel. Deras nya ramverk för ämnesmodellering är baserat på den metod som används för att hitta gemenskaper i komplexa nätverk, som, inom nätverksteori, är en graf med funktioner som förekommer vid modellering av verkliga system.
"Jag arbetade med naturligt språk och ämnesmodellering ur perspektivet av komplexa system och komplexa nätverk, "Martin Gerlach, sa postdoktor vid Northwestern University till TechXplore. "Problemen verkade väldigt lika, men gemenskaperna inom datavetenskap (ämnesmodellering) och komplexa nätverk verkade fungera i stort sett oberoende. Utbildad till fysiker, vi ville visa att två till synes olika problem kunde reduceras till samma underliggande matematik."
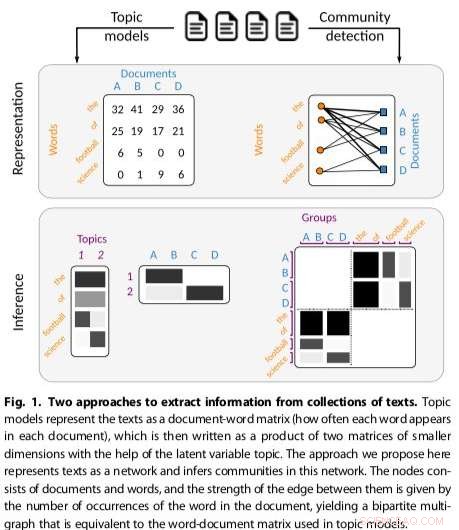
Gerlach och hans kollegor utarbetade ett nytt tillvägagångssätt för att identifiera aktuella strukturer som relaterar till problemet med att hitta gemenskaper i komplexa nätverk. Deras teknik representerar textkorpus som tvådelade nätverk, en klass av komplexa nätverk som delar upp noder i uppsättningar X och Y, tillåter endast anslutningar mellan noder i olika uppsättningar.
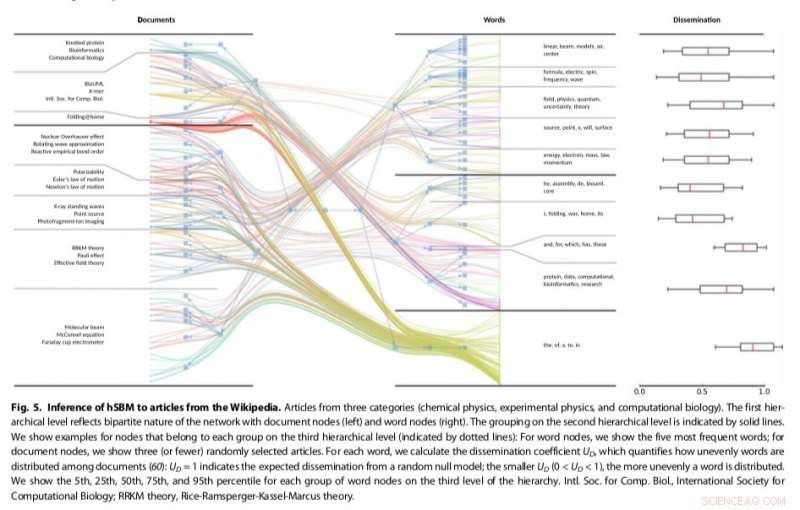
Kredit:Gerlach et al.
"Vi kartlade problemet med ämnesmodellering till problemet med gemenskapsdetektering i ett nätverk bestående av ord och dokument som visar att de är matematiskt likvärdiga, " förklarade Gerlach.
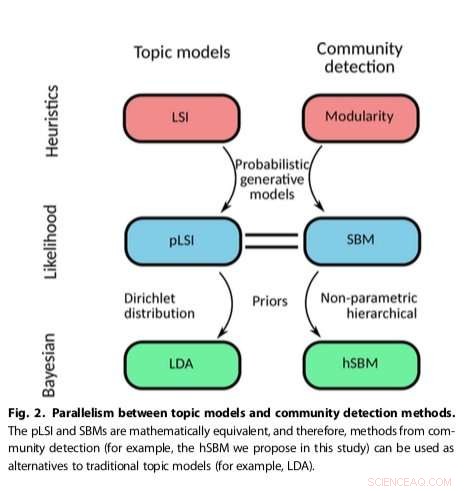
Forskarnas tillvägagångssätt, som anpassar befintliga community-detektionsmetoder, visade sig vara mer mångsidig och principiell än andra befintliga ämnesmodeller, till exempel att upptäcka antalet ämnen som finns i texter och hierarkiskt gruppera både ord och dokument. Deras metod använde en stokastisk blockmodell (SBM), en generativ modell för grafer som generellt kartlägger samhällen, delmängder av objekt som är kopplade till varandra.
"Vi löser några av de inneboende och kända problemen med populära ämnesmodelleringsalgoritmer som LDA (t.ex. hur man bestämmer antalet ämnen), sade Gerlach. Dessutom, vårt arbete visar hur man formellt kan relatera metoder från communitydetektering och ämnesmodellering, öppnar möjligheten för korsbefruktning mellan dessa två fält."
SBM-metoden som utvecklats av Gerlach och hans kollegor kan ha intressanta tillämpningar inom andra områden där maskininlärning används, såsom analys av genetiska koder eller bilder. I framtiden, forskarna planerar att fortsätta utforska potentialen i komplexa nätverk både inom textanalys och utanför.
"Ekvivalensen mellan ämnesmodellering och gemenskapsdetektering gör det möjligt att använda insikter som erhållits i var och en av gemenskaperna och tillämpas på den andra domänen, ", sa Gerlach. "Jag hoppas kunna använda dessa insikter för att få en bättre förståelse för dessa maskininlärningsalgoritmer; varför de jobbar, och ännu viktigare, under vilka förhållanden de inte fungerar."
© 2018 Tech Xplore