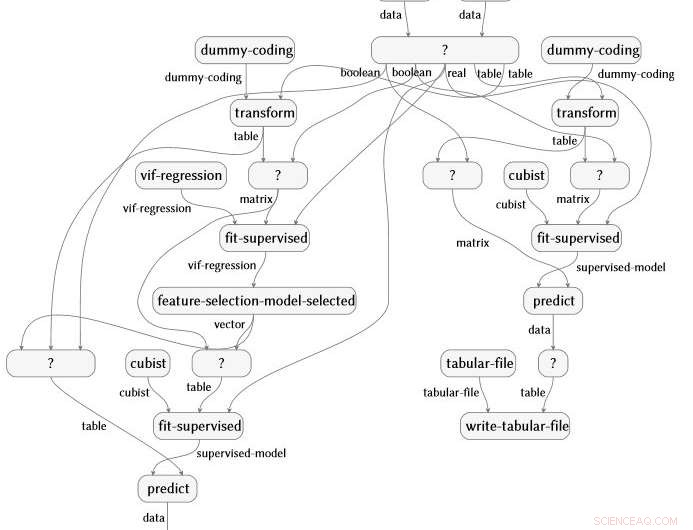
Semantisk flödesgrafrepresentation producerad automatiskt från en analys av data om reumatoid artrit. Kredit:IBM
Vi har sett betydande framsteg nyligen inom mönsteranalys och maskinintelligens tillämpad på bilder, ljud- och bildsignaler, och naturligt språktext, men inte lika mycket tillämpat på en annan artefakt som producerats av människor:datorprograms källkod. I en artikel som ska presenteras vid FEED-workshopen på KDD 2018, vi visar upp ett system som gör framsteg mot semantisk analys av kod. Genom att göra så, vi tillhandahåller grunden för maskiner att verkligen resonera om programkod och lära av den.
Arbetet, demonstrerade nyligen på IJCAI 2018, är utformad och leds av IBM Science for Social Good-kollegan Evan Patterson och fokuserar specifikt på datavetenskaplig programvara. Datavetenskapsprogram är en speciell typ av datorkod, ofta ganska kort, men fullt av semantiskt rikt innehåll som specificerar en sekvens av datatransformation, analys, modellering, och tolkningsoperationer. Vår teknik utför en dataanalys (tänk dig ett R- eller Python-skript) och fångar alla funktioner som anropas i analysen. Den kopplar sedan dessa funktioner till en datavetenskaplig ontologi som vi har skapat, utför flera förenklingssteg, och producerar en semantisk flödesgrafrepresentation av programmet. Som ett exempel, flödesdiagrammet nedan produceras automatiskt från en analys av data om reumatoid artrit.
Tekniken är tillämpbar över val av programmeringsspråk och paket. De tre kodavsnitten nedan är skrivna i R, Python med paketen NumPy och SciPy, och Python med Pandas och Scikit-learn-paketen. Alla producerar exakt samma semantiska flödesdiagram.
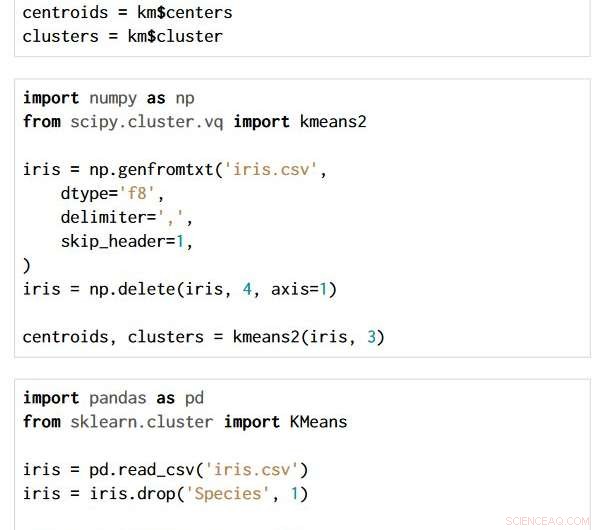
Kredit:IBM
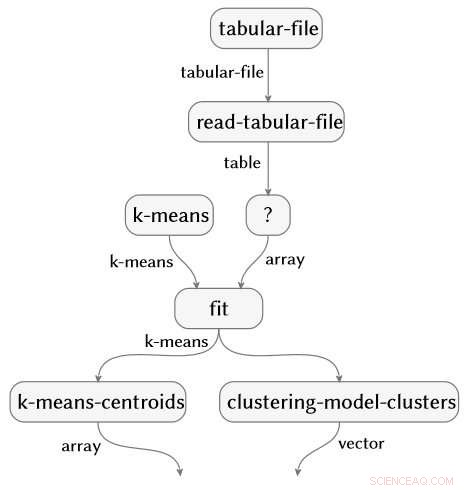
Kredit:IBM
Vi kan tänka på den semantiska flödesgrafen vi extraherar som en enda datapunkt, precis som en bild eller ett stycke text, för att utföra ytterligare uppgifter på högre nivå. Med den representation vi har utvecklat, vi kan aktivera flera användbara funktioner för praktiserande datavetare, inklusive intelligent sökning och automatisk komplettering av analyser, rekommendation av liknande eller kompletterande analyser, visualisering av utrymmet för alla analyser som utförs på ett visst problem eller datauppsättning, översättning eller stilöverföring, och till och med maskingenerering av nya dataanalyser (d.v.s. beräkningskreativitet) – allt baserat på den verkligt semantiska förståelsen av vad koden gör.
Data Science Ontology är skriven i ett nytt ontologispråk som vi har utvecklat som heter Monoidal Ontology and Computing Language (Monocl). Denna arbetslinje inleddes 2016 i samarbete med Accelerated Cure Project for multipel skleros.
Den här historien återpubliceras med tillstånd av IBM Research. Läs originalberättelsen här.














