"YoTube"-detektorn hjälper till att göra AI mer människocentrerad. Kredit:iStock
När en polis börjar räcka upp handen i trafiken, mänskliga förare inser att officeren är på väg att signalera dem att stanna. Men datorer har svårare att räkna ut människors nästa sannolika handlingar baserat på deras nuvarande beteende. Nu, ett team av A*STAR -forskare och kollegor har utvecklat en detektor som framgångsrikt kan välja var mänskliga handlingar kommer att inträffa i videor, i nästan realtid.
Bildanalysteknik kommer att behöva bli bättre på att förstå mänskliga avsikter om den ska kunna användas i ett brett spektrum av tillämpningar, säger Hongyuan Zhu, en datavetare vid A*STAR's Institute for Infocomm Research, som ledde studien. Förarlösa bilar måste kunna upptäcka poliser och tolka deras handlingar snabbt och korrekt, för säker körning, han förklarar. Autonoma system kan också tränas för att identifiera misstänkta aktiviteter som strider, stöld, eller tappa farliga föremål, och uppmärksamma säkerhetsansvariga.
Datorer är redan extremt bra på att upptäcka objekt i statiska bilder, tack vare djupinlärningstekniker, som använder artificiella neurala nätverk för att bearbeta komplex bildinformation. Men videor med rörliga föremål är mer utmanande. "Att förstå mänskliga handlingar i videor är ett nödvändigt steg för att bygga smartare och vänligare maskiner, säger Zhu.
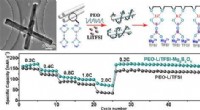
Tidigare metoder för att lokalisera potentiella mänskliga handlingar i videor använde inte ramverk för djupinlärning och var långsamma och felbenägna, säger Zhu. För att övervinna detta, teamets YoTube-detektor kombinerar två typer av neurala nätverk parallellt:ett statiskt neuralt nätverk, som redan har visat sig vara korrekt vid bearbetning av stillbilder, och ett återkommande neuralt nätverk, används vanligtvis för att bearbeta ändrade data, för taligenkänning. "Vår metod är den första som samlar upptäckt och spårning i en djupinlärningspipeline, säger Zhu.
Teamet testade YoTube på mer än 3, 000 videor som rutinmässigt används i datorsexperiment. De rapporterar att den överträffade toppmoderna detektorer när det gällde att korrekt välja ut potentiella mänskliga handlingar med cirka 20 procent för videor som visar allmänna vardagsaktiviteter och cirka 6 procent för sportvideor. Detektorn gör ibland misstag om personerna i videon är små, eller om det är många människor i bakgrunden. Ändå, Zhu säger, "Vi har visat att vi kan upptäcka de flesta potentiella mänskliga aktionsregioner på ett nästan realtidssätt."