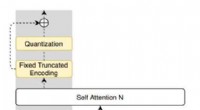
TbD-net löser det visuella resonemangsproblemet genom att dela upp det till en kedja av deluppgifter. Svaret på varje deluppgift visas i värmekartor som markerar objekten av intresse, låter analytiker se nätverkets tankeprocess. Kredit:Intelligence and Decision Technologies Group 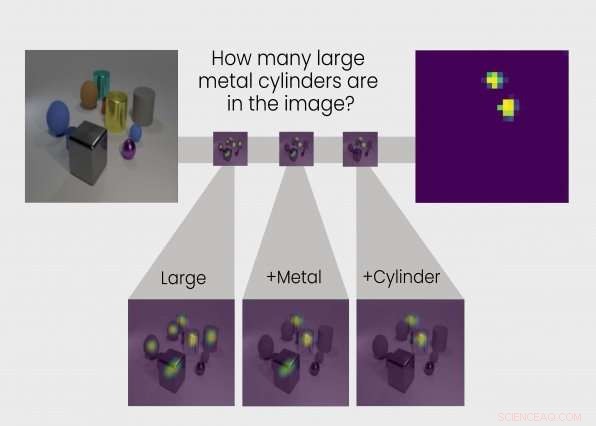
Vi lär oss genom förnuftet hur vi ska tolka världen. Så, för, göra neurala nätverk. Nu har ett team av forskare från MIT Lincoln Laboratorys Intelligence and Decision Technologies Group utvecklat ett neuralt nätverk som utför mänskliga resonemangssteg för att svara på frågor om innehållet i bilder. Döpt till Transparency by Design Network (TbD-net), modellen återger sin tankeprocess visuellt när den löser problem, låter mänskliga analytiker tolka dess beslutsprocess. Modellen presterar bättre än dagens bästa visuellt resonerande neurala nätverk.
Att förstå hur ett neuralt nätverk kommer till sina beslut har varit en långvarig utmaning för forskare inom artificiell intelligens (AI). Som den neurala delen av namnet antyder, neurala nätverk är hjärninspirerade AI-system som är avsedda att replikera det sätt som människor lär sig. De består av ingångs- och utdatalager, och lager däremellan som omvandlar inmatningen till rätt utdata. Vissa djupa neurala nätverk har blivit så komplexa att det är praktiskt taget omöjligt att följa denna transformationsprocess. Det är därför de kallas "black box"-system, med deras exakta händelser inuti ogenomskinliga även för ingenjörerna som bygger dem.
Med TbD-net, utvecklarna strävar efter att göra dessa inre funktioner transparenta. Transparens är viktigt eftersom det tillåter människor att tolka en AI:s resultat.
Det är viktigt att veta, till exempel, vad exakt ett neuralt nätverk som används i självkörande bilar tror att skillnaden är mellan en fotgängare och stoppskylt, och vid vilken tidpunkt i dess resonemangskedja ser den den skillnaden. Dessa insikter gör det möjligt för forskare att lära det neurala nätverket att korrigera eventuella felaktiga antaganden. Men TbD-net-utvecklarna säger att de bästa neurala nätverken idag saknar en effektiv mekanism för att göra det möjligt för människor att förstå sin resonemangsprocess.
"Framsteg när det gäller att förbättra prestanda i visuella resonemang har kommit på bekostnad av tolkningsbarhet, säger Ryan Soklaski, som byggde TbD-net tillsammans med forskarkollegorna Arjun Majumdar, David Mascharka, och Philip Tran.
Lincoln Laboratory-gruppen lyckades minska gapet mellan prestanda och tolkningsbarhet med TbD-net. En nyckel till deras system är en samling "moduler, " små neurala nätverk som är specialiserade för att utföra specifika deluppgifter. När TbD-net får en visuell resonemangsfråga om en bild, den delar upp frågan i deluppgifter och tilldelar lämplig modul för att uppfylla sin del. Som arbetare längs ett löpande band, varje modul bygger på det som modulen innan den har kommit på för att så småningom producera finalen, rätt svar. Som helhet, TbD-net använder en AI-teknik som tolkar mänskliga språkfrågor och delar upp dessa meningar i deluppgifter, följt av flera datorseende AI-tekniker som tolkar bilderna.
Majumdar säger:"Att bryta en komplex kedja av resonemang i en serie mindre delproblem, som var och en kan lösas oberoende och sammansatt, är ett kraftfullt och intuitivt sätt att resonera."
Varje moduls utdata avbildas visuellt i vad gruppen kallar en "uppmärksamhetsmask". Uppmärksamhetsmasken visar värmekartblobbar över objekt i bilden som modulen identifierar som sitt svar. Dessa visualiseringar låter den mänskliga analytikern se hur en modul tolkar bilden.
Ta, till exempel, följande fråga ställd till TbD-net:"I den här bilden, vilken färg har den stora metallkuben?" För att svara på frågan, den första modulen lokaliserar bara stora objekt, producerar en uppmärksamhetsmask med de stora föremålen markerade. Nästa modul tar denna utdata och hittar vilka av de objekt som identifierats som stora av den föregående modulen som också är metall. Den modulens utdata skickas till nästa modul, som identifierar vilken av de stora, metallföremål är också en kub. Äntligen, denna utdata skickas till en modul som kan bestämma färgen på objekt. TbD-nets slutliga utdata är "röd, "rätt svar på frågan.
När den testades, TbD-net uppnådde resultat som överträffar de bäst presterande visuella resonemangsmodellerna. Forskarna utvärderade modellen med hjälp av en visuell frågesvarsdatauppsättning bestående av 70, 000 träningsbilder och 700, 000 frågor, tillsammans med test- och valideringsset om 15, 000 bilder och 150, 000 frågor. Den ursprungliga modellen uppnådde 98,7 procent testnoggrannhet på datamängden, som, enligt forskarna, överträffar andra nätverksbaserade tillvägagångssätt med neurala moduler.
Viktigt, forskarna kunde sedan förbättra dessa resultat på grund av deras modells viktigaste fördel – transparens. Genom att titta på uppmärksamhetsmaskerna som produceras av modulerna, de kunde se var det gick fel och förfina modellen. Slutresultatet var en toppmodern prestanda med 99,1 procents noggrannhet.
"Vår modell ger rättfram, tolkbara utdata i varje steg av den visuella resonemangsprocessen, säger Mascharka.
Tolkbarhet är särskilt värdefullt om algoritmer för djupinlärning ska användas tillsammans med människor för att hjälpa till att hantera komplexa verkliga uppgifter. För att skapa förtroende för dessa system, användare kommer att behöva förmågan att inspektera resonemangsprocessen så att de kan förstå varför och hur en modell kan göra felaktiga förutsägelser.
Paul Metzger, ledare för Intelligence and Decision Technologies Group, säger forskningen "är en del av Lincoln Laboratorys arbete mot att bli världsledande inom tillämpad maskininlärningsforskning och artificiell intelligens som främjar samarbete mellan människa och maskin."
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.